 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Agents Enable User-Governed Personalization Beyond Platform Boundaries
May 10, 2026Personalization today is fundamentally platform-centric: services build user representations from the behavioral fragments they observe. Yet no platform can construct a complete picture of the user, as competitive incentives, legal constraints, user privacy concerns, and epistemic limits create persistent data barriers. This paper argues for a shift from platform-centric personalization to user-governed personalization, where only the user can integrate fragmented contexts across platforms and the offline world. The key asymmetry lies in data access: only users can aggregate their own cross-platform and offline information. Large language model (LLM) agents make such integration practically feasible for the first time by enabling reasoning over heterogeneous personal data and transforming users' cross-context information into actionable personalization capabilities. We provide proof-of-concept evidence that users equipped with cross-platform data exports and an off-the-shelf LLM agent can outperform single-platform personalization baselines. We conclude by outlining a research agenda for building scalable user-governed personalization systems.
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
Adaptation of Agentic AI
Dec 22, 2025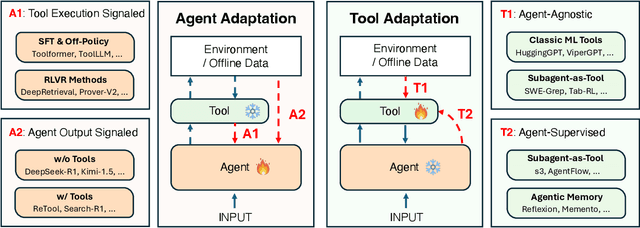
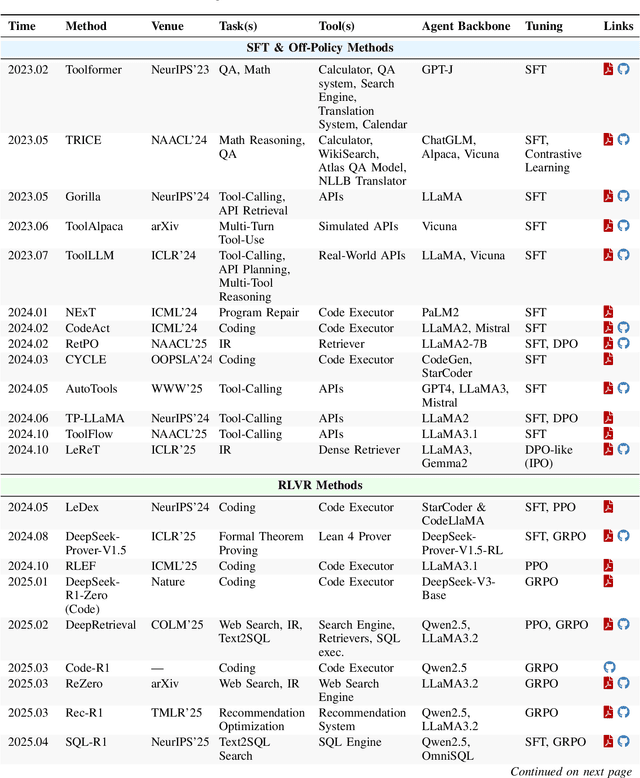
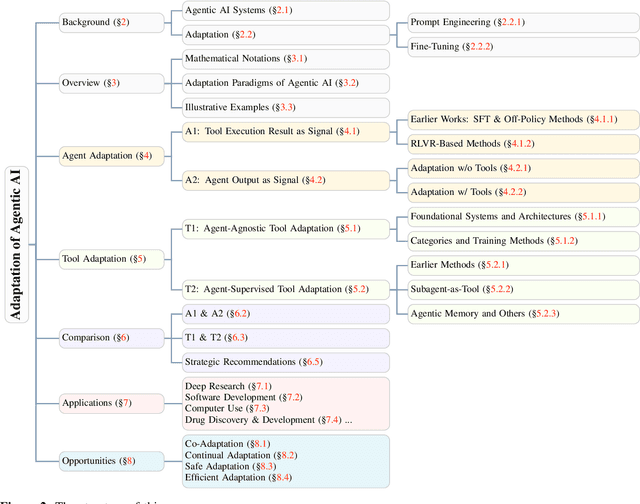
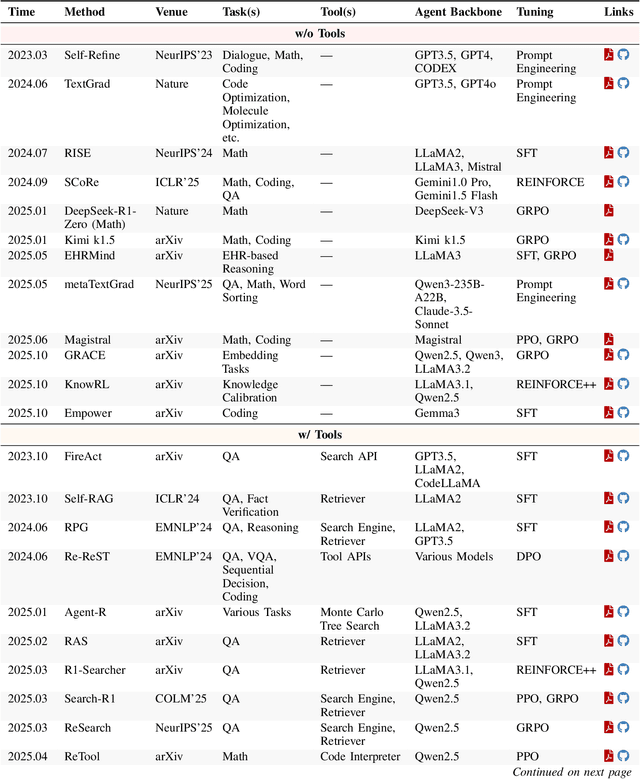
Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these systems grow in capability and scope, adaptation becomes a central mechanism for improving performance, reliability, and generalization. In this paper, we unify the rapidly expanding research landscape into a systematic framework that spans both agent adaptations and tool adaptations. We further decompose these into tool-execution-signaled and agent-output-signaled forms of agent adaptation, as well as agent-agnostic and agent-supervised forms of tool adaptation. We demonstrate that this framework helps clarify the design space of adaptation strategies in agentic AI, makes their trade-offs explicit, and provides practical guidance for selecting or switching among strategies during system design. We then review the representative approaches in each category, analyze their strengths and limitations, and highlight key open challenges and future opportunities. Overall, this paper aims to offer a conceptual foundation and practical roadmap for researchers and practitioners seeking to build more capable, efficient, and reliable agentic AI systems.
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Oct 06, 2025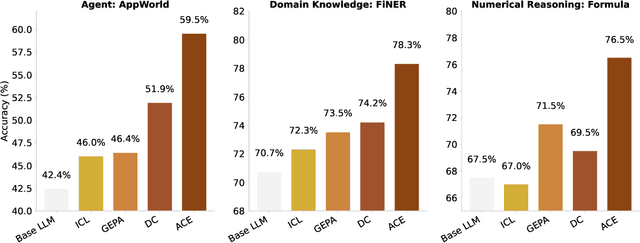
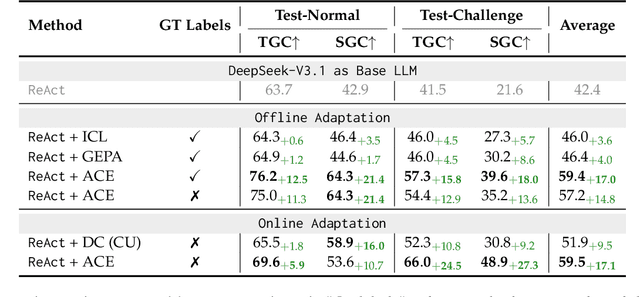
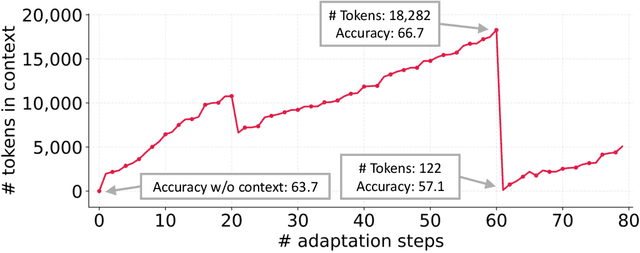
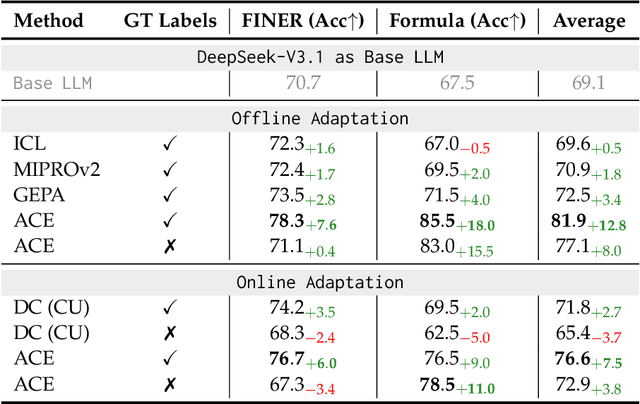
Large language model (LLM) applications such as agents and domain-specific reasoning increasingly rely on context adaptation -- modifying inputs with instructions, strategies, or evidence, rather than weight updates. Prior approaches improve usability but often suffer from brevity bias, which drops domain insights for concise summaries, and from context collapse, where iterative rewriting erodes details over time. Building on the adaptive memory introduced by Dynamic Cheatsheet, we introduce ACE (Agentic Context Engineering), a framework that treats contexts as evolving playbooks that accumulate, refine, and organize strategies through a modular process of generation, reflection, and curation. ACE prevents collapse with structured, incremental updates that preserve detailed knowledge and scale with long-context models. Across agent and domain-specific benchmarks, ACE optimizes contexts both offline (e.g., system prompts) and online (e.g., agent memory), consistently outperforming strong baselines: +10.6% on agents and +8.6% on finance, while significantly reducing adaptation latency and rollout cost. Notably, ACE could adapt effectively without labeled supervision and instead by leveraging natural execution feedback. On the AppWorld leaderboard, ACE matches the top-ranked production-level agent on the overall average and surpasses it on the harder test-challenge split, despite using a smaller open-source model. These results show that comprehensive, evolving contexts enable scalable, efficient, and self-improving LLM systems with low overhead.
Distilling Tool Knowledge into Language Models via Back-Translated Traces
Jun 23, 2025Large language models (LLMs) often struggle with mathematical problems that require exact computation or multi-step algebraic reasoning. Tool-integrated reasoning (TIR) offers a promising solution by leveraging external tools such as code interpreters to ensure correctness, but it introduces inference-time dependencies that hinder scalability and deployment. In this work, we propose a new paradigm for distilling tool knowledge into LLMs purely through natural language. We first construct a Solver Agent that solves math problems by interleaving planning, symbolic tool calls, and reflective reasoning. Then, using a back-translation pipeline powered by multiple LLM-based agents, we convert interleaved TIR traces into natural language reasoning traces. A Translator Agent generates explanations for individual tool calls, while a Rephrase Agent merges them into a fluent and globally coherent narrative. Empirically, we show that fine-tuning a small open-source model on these synthesized traces enables it to internalize both tool knowledge and structured reasoning patterns, yielding gains on competition-level math benchmarks without requiring tool access at inference.
LLMs Know What to Drop: Self-Attention Guided KV Cache Eviction for Efficient Long-Context Inference
Mar 11, 2025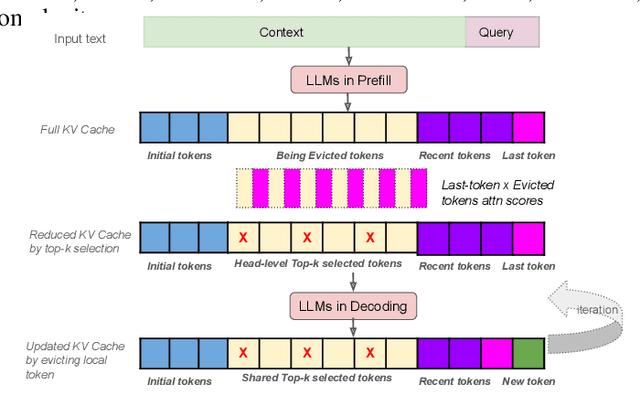
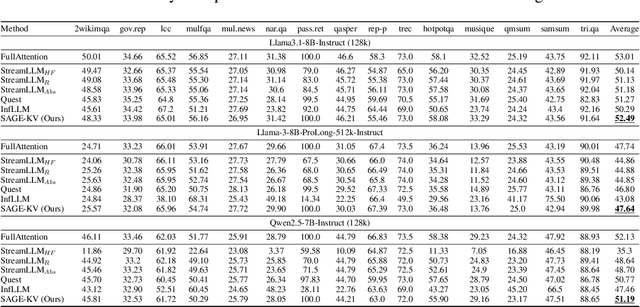
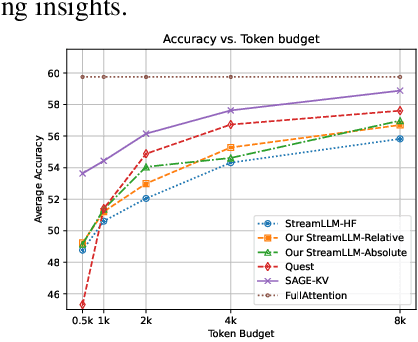
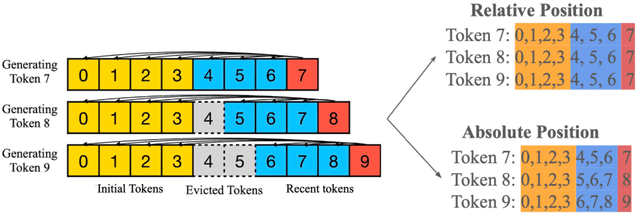
Efficient long-context inference is critical as large language models (LLMs) adopt context windows of ranging from 128K to 1M tokens. However, the growing key-value (KV) cache and the high computational complexity of attention create significant bottlenecks in memory usage and latency. In this paper, we find that attention in diverse long-context tasks exhibits sparsity, and LLMs implicitly "know" which tokens can be dropped or evicted at the head level after the pre-filling stage. Based on this insight, we propose Self-Attention Guided Eviction~(SAGE-KV), a simple and effective KV eviction cache method for long-context inference. After prefilling, our method performs a one-time top-k selection at both the token and head levels to compress the KV cache, enabling efficient inference with the reduced cache. Evaluations on LongBench and three long-context LLMs (Llama3.1-8B-Instruct-128k, Llama3-8B-Prolong-512k-Instruct, and Qwen2.5-7B-Instruct-128k) show that SAGE-KV maintains accuracy comparable to full attention while significantly improving efficiency. Specifically, SAGE-KV achieves 4x higher memory efficiency with improved accuracy over the static KV cache selection method StreamLLM, and 2x higher memory efficiency with better accuracy than the dynamic KV cache selection method Quest.
Training Domain Draft Models for Speculative Decoding: Best Practices and Insights
Mar 10, 2025



Speculative decoding is an effective method for accelerating inference of large language models (LLMs) by employing a small draft model to predict the output of a target model. However, when adapting speculative decoding to domain-specific target models, the acceptance rate of the generic draft model drops significantly due to domain shift. In this work, we systematically investigate knowledge distillation techniques for training domain draft models to improve their speculation accuracy. We compare white-box and black-box distillation approaches and explore their effectiveness in various data accessibility scenarios, including historical user queries, curated domain data, and synthetically generated alignment data. Our experiments across Function Calling, Biology, and Chinese domains show that offline distillation consistently outperforms online distillation by 11% to 25%, white-box distillation surpasses black-box distillation by 2% to 10%, and data scaling trends hold across domains. Additionally, we find that synthetic data can effectively align draft models and achieve 80% to 93% of the performance of training on historical user queries. These findings provide practical guidelines for training domain-specific draft models to improve speculative decoding efficiency.
SubgoalXL: Subgoal-based Expert Learning for Theorem Proving
Aug 20, 2024



Formal theorem proving, a field at the intersection of mathematics and computer science, has seen renewed interest with advancements in large language models (LLMs). This paper introduces SubgoalXL, a novel approach that synergizes subgoal-based proofs with expert learning to enhance LLMs' capabilities in formal theorem proving within the Isabelle environment. SubgoalXL addresses two critical challenges: the scarcity of specialized mathematics and theorem-proving data, and the need for improved multi-step reasoning abilities in LLMs. By optimizing data efficiency and employing subgoal-level supervision, SubgoalXL extracts richer information from limited human-generated proofs. The framework integrates subgoal-oriented proof strategies with an expert learning system, iteratively refining formal statement, proof, and subgoal generators. Leveraging the Isabelle environment's advantages in subgoal-based proofs, SubgoalXL achieves a new state-of-the-art performance of 56.1\% in Isabelle on the standard miniF2F dataset, marking an absolute improvement of 4.9\%. Notably, SubgoalXL successfully solves 41 AMC12, 9 AIME, and 3 IMO problems from miniF2F. These results underscore the effectiveness of maximizing limited data utility and employing targeted guidance for complex reasoning in formal theorem proving, contributing to the ongoing advancement of AI reasoning capabilities. The implementation is available at \url{https://github.com/zhaoxlpku/SubgoalXL}.
SambaLingo: Teaching Large Language Models New Languages
Apr 08, 2024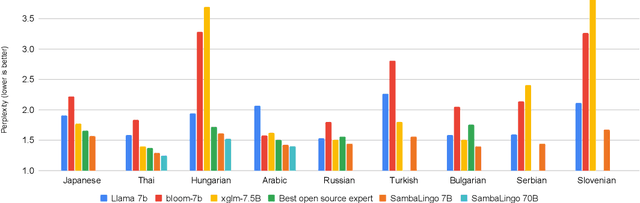
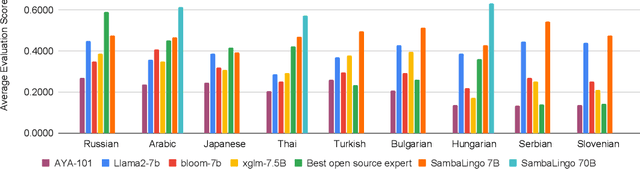

Despite the widespread availability of LLMs, there remains a substantial gap in their capabilities and availability across diverse languages. One approach to address these issues has been to take an existing pre-trained LLM and continue to train it on new languages. While prior works have experimented with language adaptation, many questions around best practices and methodology have not been covered. In this paper, we present a comprehensive investigation into the adaptation of LLMs to new languages. Our study covers the key components in this process, including vocabulary extension, direct preference optimization and the data scarcity problem for human alignment in low-resource languages. We scale these experiments across 9 languages and 2 parameter scales (7B and 70B). We compare our models against Llama 2, Aya-101, XGLM, BLOOM and existing language experts, outperforming all prior published baselines. Additionally, all evaluation code and checkpoints are made public to facilitate future research.
On the Tool Manipulation Capability of Open-source Large Language Models
May 25, 2023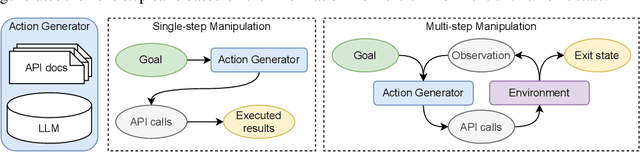
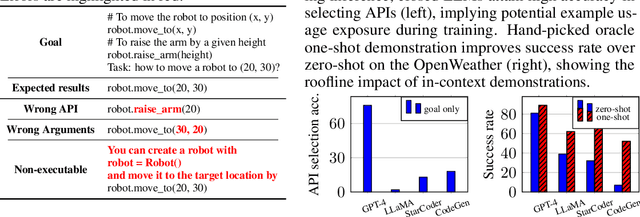
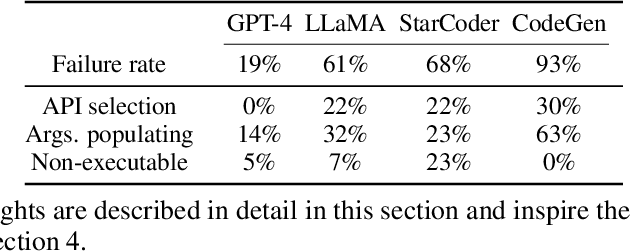
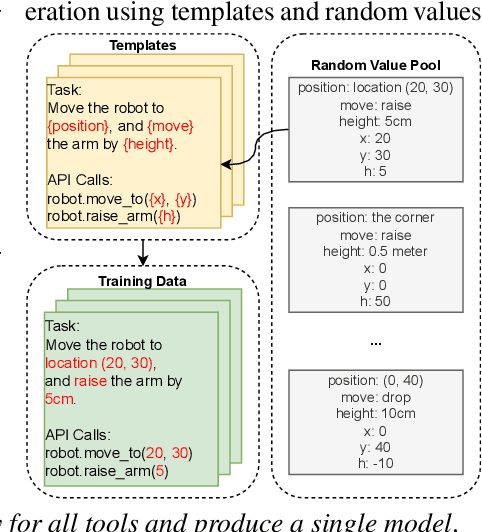
Recent studies on software tool manipulation with large language models (LLMs) mostly rely on closed model APIs. The industrial adoption of these models is substantially constrained due to the security and robustness risks in exposing information to closed LLM API services. In this paper, we ask can we enhance open-source LLMs to be competitive to leading closed LLM APIs in tool manipulation, with practical amount of human supervision. By analyzing common tool manipulation failures, we first demonstrate that open-source LLMs may require training with usage examples, in-context demonstration and generation style regulation to resolve failures. These insights motivate us to revisit classical methods in LLM literature, and demonstrate that we can adapt them as model alignment with programmatic data generation, system prompts and in-context demonstration retrievers to enhance open-source LLMs for tool manipulation. To evaluate these techniques, we create the ToolBench, a tool manipulation benchmark consisting of diverse software tools for real-world tasks. We demonstrate that our techniques can boost leading open-source LLMs by up to 90% success rate, showing capabilities competitive to OpenAI GPT-4 in 4 out of 8 ToolBench tasks. We show that such enhancement typically requires about one developer day to curate data for each tool, rendering a recipe with practical amount of human supervision.