 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Document Question Answering in Hungarian
May 29, 2025Modern VLMs have achieved near-saturation accuracy in English document visual question-answering (VQA). However, this task remains challenging in lower resource languages due to a dearth of suitable training and evaluation data. In this paper we present scalable methods for curating such datasets by focusing on Hungarian, approximately the 17th highest resource language on the internet. Specifically, we present HuDocVQA and HuDocVQA-manual, document VQA datasets that modern VLMs significantly underperform on compared to English DocVQA. HuDocVQA-manual is a small manually curated dataset based on Hungarian documents from Common Crawl, while HuDocVQA is a larger synthetically generated VQA data set from the same source. We apply multiple rounds of quality filtering and deduplication to HuDocVQA in order to match human-level quality in this dataset. We also present HuCCPDF, a dataset of 117k pages from Hungarian Common Crawl PDFs along with their transcriptions, which can be used for training a model for Hungarian OCR. To validate the quality of our datasets, we show how finetuning on a mixture of these datasets can improve accuracy on HuDocVQA for Llama 3.2 11B Instruct by +7.2%. Our datasets and code will be released to the public to foster further research in multilingual DocVQA.
Composition of Experts: A Modular Compound AI System Leveraging Large Language Models
Dec 02, 2024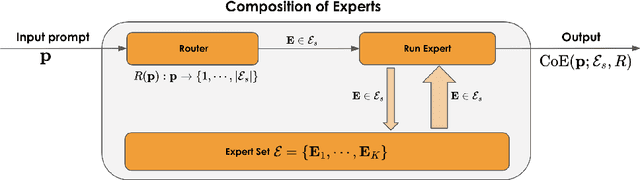
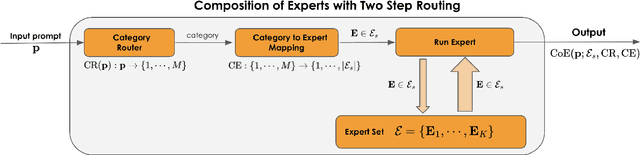
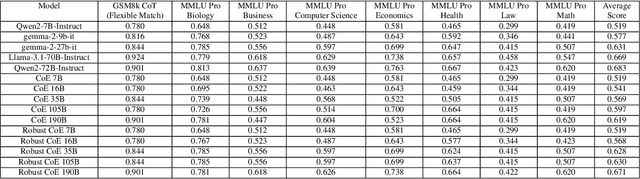
Large Language Models (LLMs) have achieved remarkable advancements, but their monolithic nature presents challenges in terms of scalability, cost, and customization. This paper introduces the Composition of Experts (CoE), a modular compound AI system leveraging multiple expert LLMs. CoE leverages a router to dynamically select the most appropriate expert for a given input, enabling efficient utilization of resources and improved performance. We formulate the general problem of training a CoE and discuss inherent complexities associated with it. We propose a two-step routing approach to address these complexities that first uses a router to classify the input into distinct categories followed by a category-to-expert mapping to obtain desired experts. CoE offers a flexible and cost-effective solution to build compound AI systems. Our empirical evaluation demonstrates the effectiveness of CoE in achieving superior performance with reduced computational overhead. Given that CoE comprises of many expert LLMs it has unique system requirements for cost-effective serving. We present an efficient implementation of CoE leveraging SambaNova SN40L RDUs unique three-tiered memory architecture. CoEs obtained using open weight LLMs Qwen/Qwen2-7B-Instruct, google/gemma-2-9b-it, google/gemma-2-27b-it, meta-llama/Llama-3.1-70B-Instruct and Qwen/Qwen2-72B-Instruct achieve a score of $59.4$ with merely $31$ billion average active parameters on Arena-Hard and a score of $9.06$ with $54$ billion average active parameters on MT-Bench.
SambaLingo: Teaching Large Language Models New Languages
Apr 08, 2024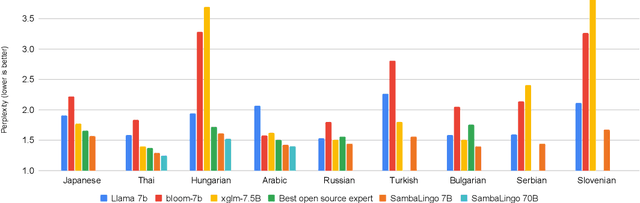
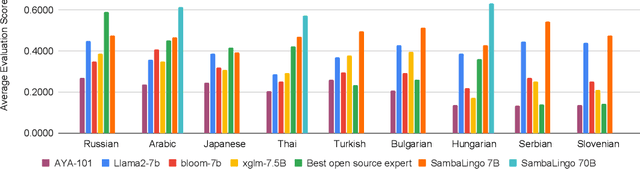

Despite the widespread availability of LLMs, there remains a substantial gap in their capabilities and availability across diverse languages. One approach to address these issues has been to take an existing pre-trained LLM and continue to train it on new languages. While prior works have experimented with language adaptation, many questions around best practices and methodology have not been covered. In this paper, we present a comprehensive investigation into the adaptation of LLMs to new languages. Our study covers the key components in this process, including vocabulary extension, direct preference optimization and the data scarcity problem for human alignment in low-resource languages. We scale these experiments across 9 languages and 2 parameter scales (7B and 70B). We compare our models against Llama 2, Aya-101, XGLM, BLOOM and existing language experts, outperforming all prior published baselines. Additionally, all evaluation code and checkpoints are made public to facilitate future research.
Efficiently Adapting Pretrained Language Models To New Languages
Nov 09, 2023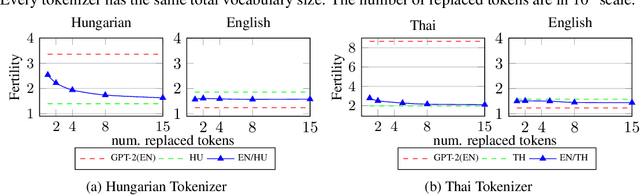
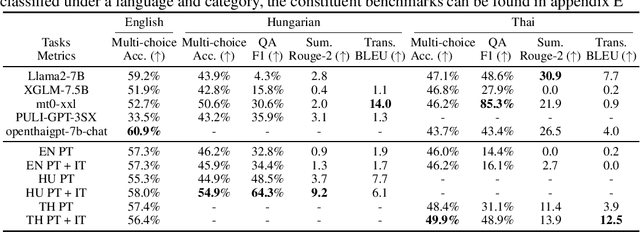
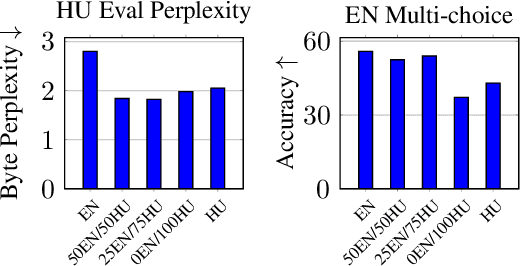
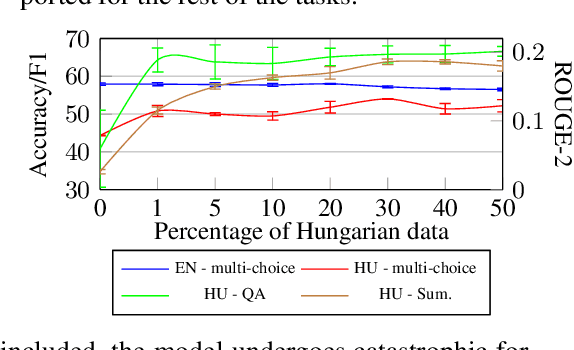
Recent large language models (LLM) exhibit sub-optimal performance on low-resource languages, as the training data of these models is usually dominated by English and other high-resource languages. Furthermore, it is challenging to train models for low-resource languages, especially from scratch, due to a lack of high quality training data. Adapting pretrained LLMs reduces the need for data in the new language while also providing cross lingual transfer capabilities. However, naively adapting to new languages leads to catastrophic forgetting and poor tokenizer efficiency. In this work, we study how to efficiently adapt any existing pretrained LLM to a new language without running into these issues. In particular, we improve the encoding efficiency of the tokenizer by adding new tokens from the target language and study the data mixing recipe to mitigate forgetting. Our experiments on adapting an English LLM to Hungarian and Thai show that our recipe can reach better performance than open source models on the target language, with minimal regressions on English.