 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoloBrain-0 Technical Report
Feb 12, 2026In this work, we introduce HoloBrain-0, a comprehensive Vision-Language-Action (VLA) framework that bridges the gap between foundation model research and reliable real-world robot deployment. The core of our system is a novel VLA architecture that explicitly incorporates robot embodiment priors, including multi-view camera parameters and kinematic descriptions (URDF), to enhance 3D spatial reasoning and support diverse embodiments. We validate this design through a scalable ``pre-train then post-train" paradigm, achieving state-of-the-art results on simulation benchmarks such as RoboTwin 2.0, LIBERO, and GenieSim, as well as strong results on challenging long-horizon real-world manipulation tasks. Notably, our efficient 0.2B-parameter variant rivals significantly larger baselines, enabling low-latency on-device deployment. To further accelerate research and practical adoption, we fully open-source the entire HoloBrain ecosystem, which includes: (1) powerful pre-trained VLA foundations; (2) post-trained checkpoints for multiple simulation suites and real-world tasks; and (3) RoboOrchard, a full-stack VLA infrastructure for data curation, model training and deployment. Together with standardized data collection protocols, this release provides the community with a complete, reproducible path toward high-performance robotic manipulation.
Relative Difficulty Distillation for Semantic Segmentation
Jul 04, 2024



Current knowledge distillation (KD) methods primarily focus on transferring various structured knowledge and designing corresponding optimization goals to encourage the student network to imitate the output of the teacher network. However, introducing too many additional optimization objectives may lead to unstable training, such as gradient conflicts. Moreover, these methods ignored the guidelines of relative learning difficulty between the teacher and student networks. Inspired by human cognitive science, in this paper, we redefine knowledge from a new perspective -- the student and teacher networks' relative difficulty of samples, and propose a pixel-level KD paradigm for semantic segmentation named Relative Difficulty Distillation (RDD). We propose a two-stage RDD framework: Teacher-Full Evaluated RDD (TFE-RDD) and Teacher-Student Evaluated RDD (TSE-RDD). RDD allows the teacher network to provide effective guidance on learning focus without additional optimization goals, thus avoiding adjusting learning weights for multiple losses. Extensive experimental evaluations using a general distillation loss function on popular datasets such as Cityscapes, CamVid, Pascal VOC, and ADE20k demonstrate the effectiveness of RDD against state-of-the-art KD methods. Additionally, our research showcases that RDD can integrate with existing KD methods to improve their upper performance bound.
SambaNova SN40L: Scaling the AI Memory Wall with Dataflow and Composition of Experts
May 13, 2024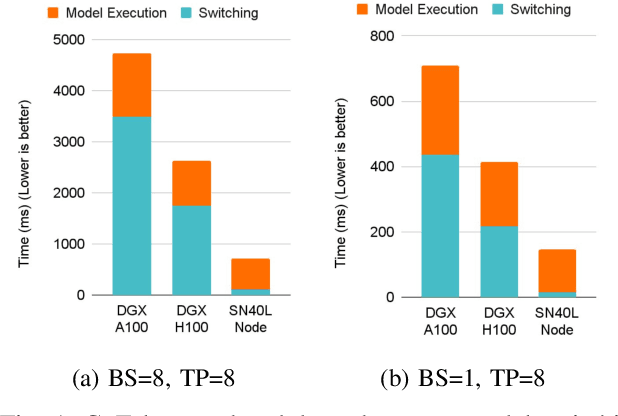
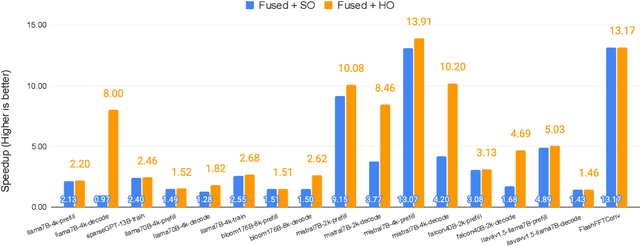
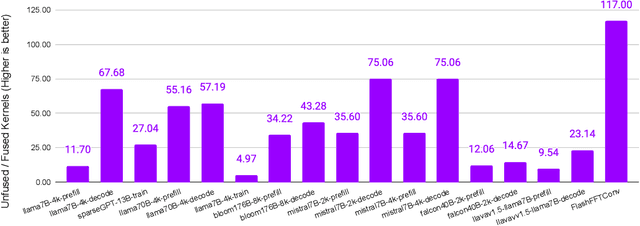
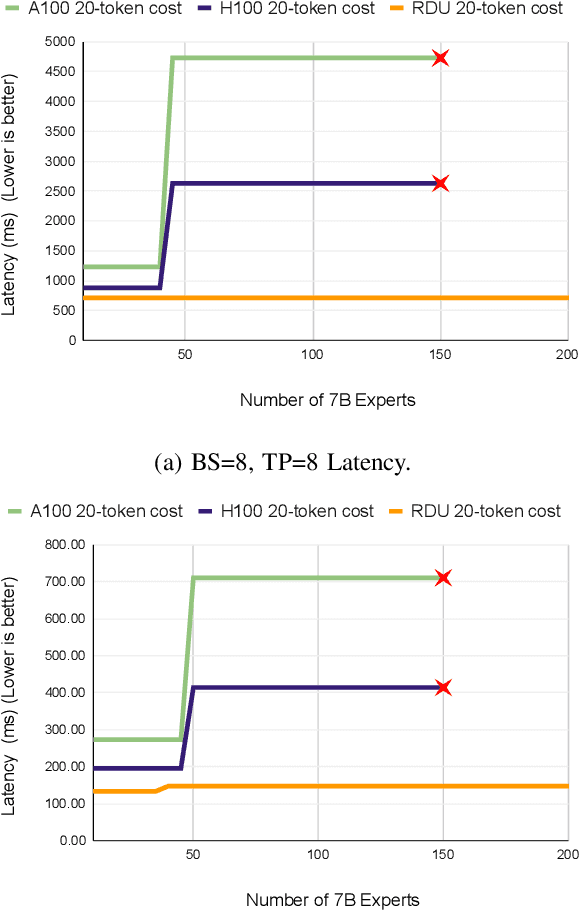
Monolithic large language models (LLMs) like GPT-4 have paved the way for modern generative AI applications. Training, serving, and maintaining monolithic LLMs at scale, however, remains prohibitively expensive and challenging. The disproportionate increase in compute-to-memory ratio of modern AI accelerators have created a memory wall, necessitating new methods to deploy AI. Composition of Experts (CoE) is an alternative modular approach that lowers the cost and complexity of training and serving. However, this approach presents two key challenges when using conventional hardware: (1) without fused operations, smaller models have lower operational intensity, which makes high utilization more challenging to achieve; and (2) hosting a large number of models can be either prohibitively expensive or slow when dynamically switching between them. In this paper, we describe how combining CoE, streaming dataflow, and a three-tier memory system scales the AI memory wall. We describe Samba-CoE, a CoE system with 150 experts and a trillion total parameters. We deploy Samba-CoE on the SambaNova SN40L Reconfigurable Dataflow Unit (RDU) - a commercial dataflow accelerator architecture that has been co-designed for enterprise inference and training applications. The chip introduces a new three-tier memory system with on-chip distributed SRAM, on-package HBM, and off-package DDR DRAM. A dedicated inter-RDU network enables scaling up and out over multiple sockets. We demonstrate speedups ranging from 2x to 13x on various benchmarks running on eight RDU sockets compared with an unfused baseline. We show that for CoE inference deployments, the 8-socket RDU Node reduces machine footprint by up to 19x, speeds up model switching time by 15x to 31x, and achieves an overall speedup of 3.7x over a DGX H100 and 6.6x over a DGX A100.
SambaLingo: Teaching Large Language Models New Languages
Apr 08, 2024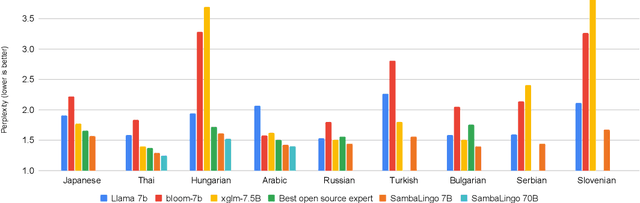
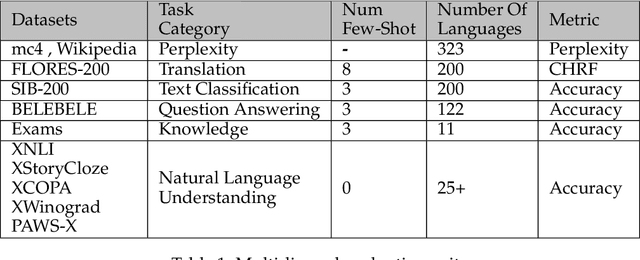
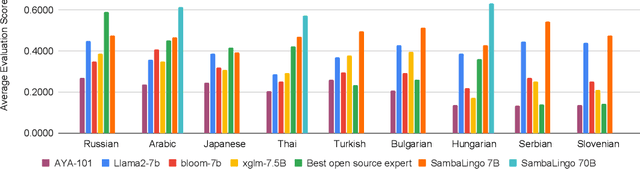

Despite the widespread availability of LLMs, there remains a substantial gap in their capabilities and availability across diverse languages. One approach to address these issues has been to take an existing pre-trained LLM and continue to train it on new languages. While prior works have experimented with language adaptation, many questions around best practices and methodology have not been covered. In this paper, we present a comprehensive investigation into the adaptation of LLMs to new languages. Our study covers the key components in this process, including vocabulary extension, direct preference optimization and the data scarcity problem for human alignment in low-resource languages. We scale these experiments across 9 languages and 2 parameter scales (7B and 70B). We compare our models against Llama 2, Aya-101, XGLM, BLOOM and existing language experts, outperforming all prior published baselines. Additionally, all evaluation code and checkpoints are made public to facilitate future research.
Noise-Robust Bidirectional Learning with Dynamic Sample Reweighting
Sep 03, 2022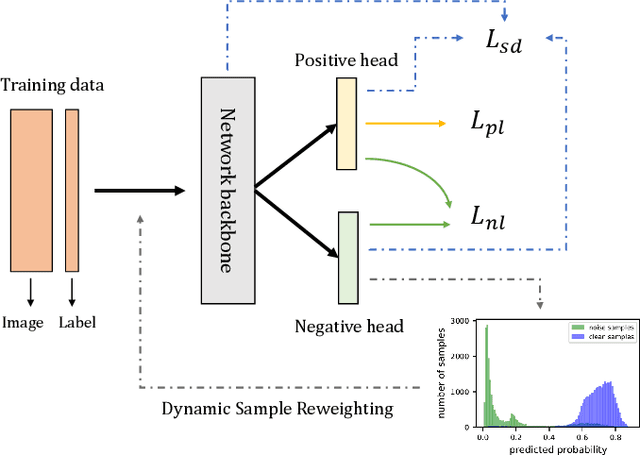

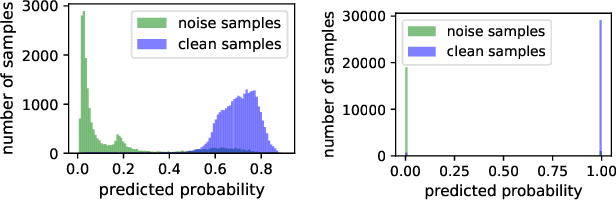
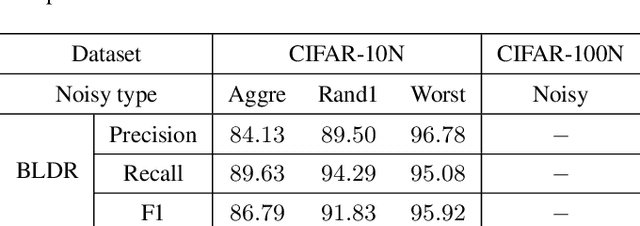
Deep neural networks trained with standard cross-entropy loss are more prone to memorize noisy labels, which degrades their performance. Negative learning using complementary labels is more robust when noisy labels intervene but with an extremely slow model convergence speed. In this paper, we first introduce a bidirectional learning scheme, where positive learning ensures convergence speed while negative learning robustly copes with label noise. Further, a dynamic sample reweighting strategy is proposed to globally weaken the effect of noise-labeled samples by exploiting the excellent discriminatory ability of negative learning on the sample probability distribution. In addition, we combine self-distillation to further improve the model performance. The code is available at \url{https://github.com/chenchenzong/BLDR}.
Exploring Contextual Relationships for Cervical Abnormal Cell Detection
Jul 18, 2022

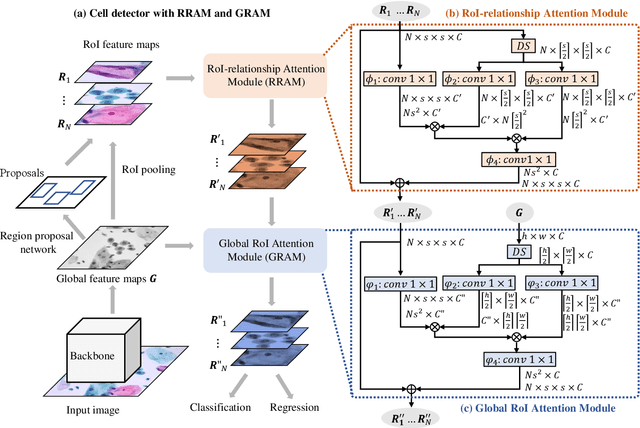
Cervical abnormal cell detection is a challenging task as the morphological discrepancies between abnormal and normal cells are usually subtle. To determine whether a cervical cell is normal or abnormal, cytopathologists always take surrounding cells as references to identify its abnormality. To mimic these behaviors, we propose to explore contextual relationships to boost the performance of cervical abnormal cell detection. Specifically, both contextual relationships between cells and cell-to-global images are exploited to enhance features of each region of interest (RoI) proposals. Accordingly, two modules, dubbed as RoI-relationship attention module (RRAM) and global RoI attention module (GRAM), are developed and their combination strategies are also investigated. We establish a strong baseline by using Double-Head Faster R-CNN with feature pyramid network (FPN) and integrate our RRAM and GRAM into it to validate the effectiveness of the proposed modules. Experiments conducted on a large cervical cell detection dataset reveal that the introduction of RRAM and GRAM both achieves better average precision (AP) than the baseline methods. Moreover, when cascading RRAM and GRAM, our method outperforms the state-of-the-art (SOTA) methods. Furthermore, we also show the proposed feature enhancing scheme can facilitate both image-level and smear-level classification. The code and trained models are publicly available at https://github.com/CVIU-CSU/CR4CACD.
Semantically Contrastive Learning for Low-light Image Enhancement
Dec 13, 2021

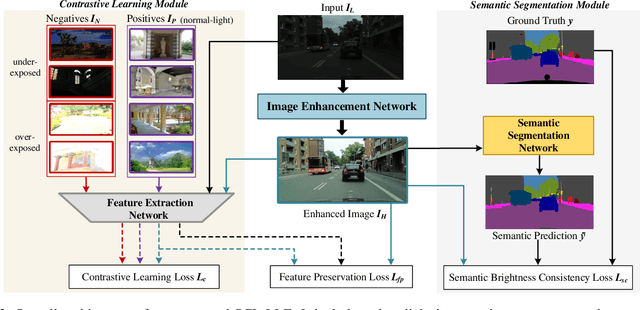

Low-light image enhancement (LLE) remains challenging due to the unfavorable prevailing low-contrast and weak-visibility problems of single RGB images. In this paper, we respond to the intriguing learning-related question -- if leveraging both accessible unpaired over/underexposed images and high-level semantic guidance, can improve the performance of cutting-edge LLE models? Here, we propose an effective semantically contrastive learning paradigm for LLE (namely SCL-LLE). Beyond the existing LLE wisdom, it casts the image enhancement task as multi-task joint learning, where LLE is converted into three constraints of contrastive learning, semantic brightness consistency, and feature preservation for simultaneously ensuring the exposure, texture, and color consistency. SCL-LLE allows the LLE model to learn from unpaired positives (normal-light)/negatives (over/underexposed), and enables it to interact with the scene semantics to regularize the image enhancement network, yet the interaction of high-level semantic knowledge and the low-level signal prior is seldom investigated in previous methods. Training on readily available open data, extensive experiments demonstrate that our method surpasses the state-of-the-arts LLE models over six independent cross-scenes datasets. Moreover, SCL-LLE's potential to benefit the downstream semantic segmentation under extremely dark conditions is discussed. Source Code: https://github.com/LingLIx/SCL-LLE.
Cloud detection in Landsat-8 imagery in Google Earth Engine based on a deep neural network
Jun 18, 2020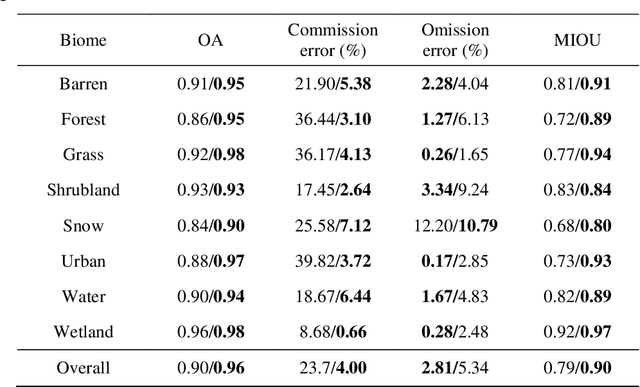
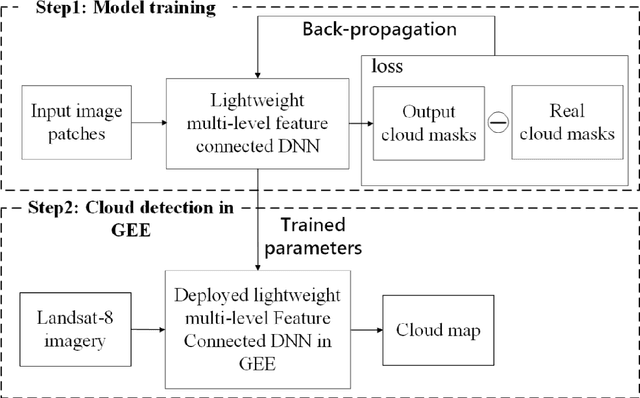
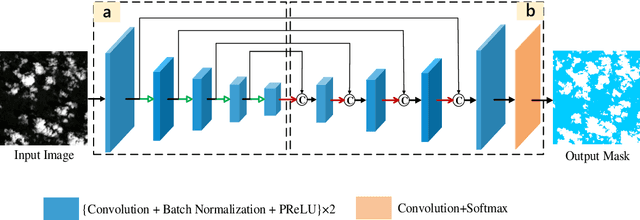
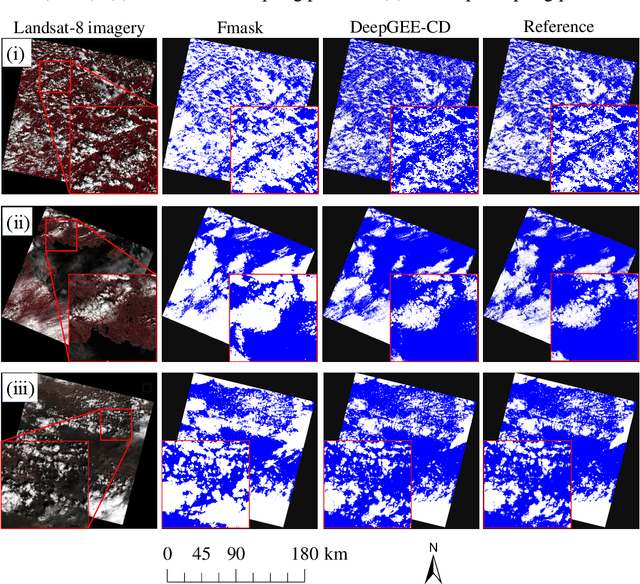
Google Earth Engine (GEE) provides a convenient platform for applications based on optical satellite imagery of large areas. With such data sets, the detection of cloud is often a necessary prerequisite step. Recently, deep learning-based cloud detection methods have shown their potential for cloud detection but they can only be applied locally, leading to inefficient data downloading time and storage problems. This letter proposes a method to directly perform cloud detection in Landsat-8 imagery in GEE based on deep learning (DeepGEE-CD). A deep neural network (DNN) was first trained locally, and then the trained DNN was deployed in the JavaScript client of GEE. An experiment was undertaken to validate the proposed method with a set of Landsat-8 images and the results show that DeepGEE-CD outperformed the widely used function of mask (Fmask) algorithm. The proposed DeepGEE-CD approach can accurately detect cloud in Landsat-8 imagery without downloading it, making it a promising method for routine cloud detection of Landsat-8 imagery in GEE.