 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Robust Bidirectional Learning with Dynamic Sample Reweighting
Sep 03, 2022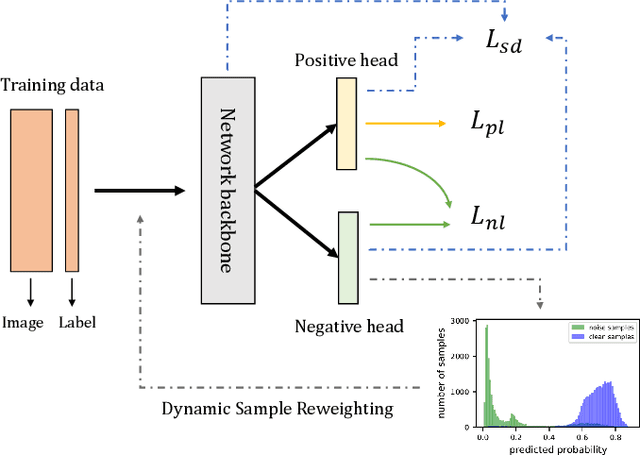

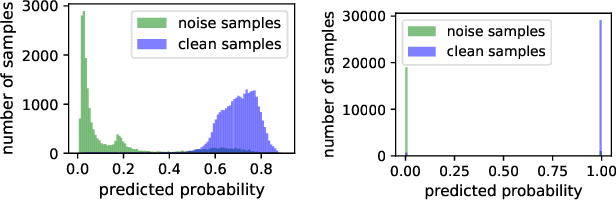
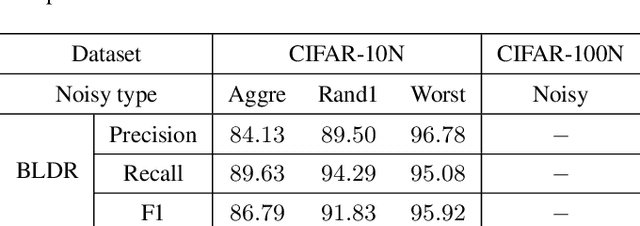
Deep neural networks trained with standard cross-entropy loss are more prone to memorize noisy labels, which degrades their performance. Negative learning using complementary labels is more robust when noisy labels intervene but with an extremely slow model convergence speed. In this paper, we first introduce a bidirectional learning scheme, where positive learning ensures convergence speed while negative learning robustly copes with label noise. Further, a dynamic sample reweighting strategy is proposed to globally weaken the effect of noise-labeled samples by exploiting the excellent discriminatory ability of negative learning on the sample probability distribution. In addition, we combine self-distillation to further improve the model performance. The code is available at \url{https://github.com/chenchenzong/BLDR}.
Learning from Crowds with Sparse and Imbalanced Annotations
Jul 11, 2021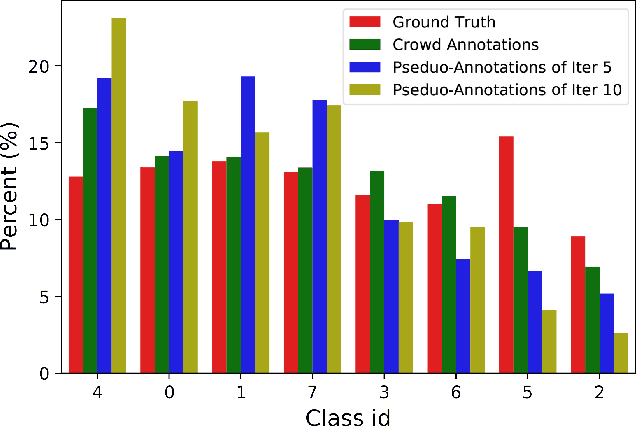
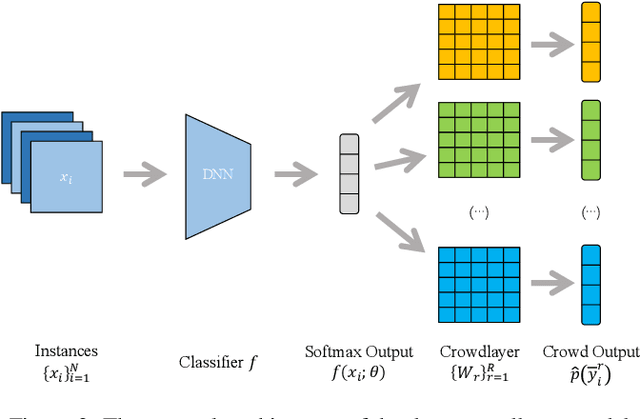
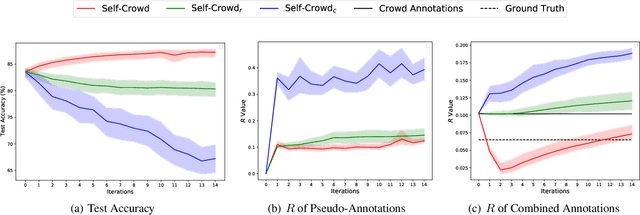
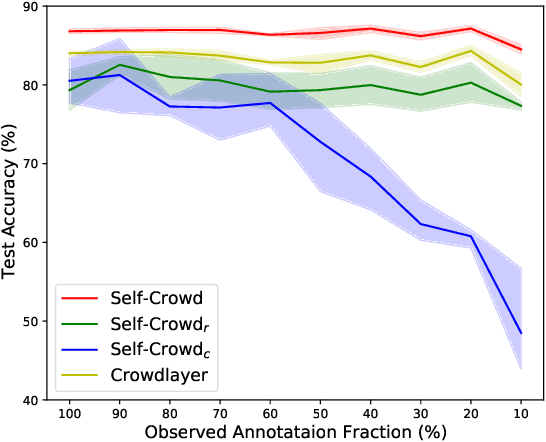
Traditional supervised learning requires ground truth labels for the training data, whose collection can be difficult in many cases. Recently, crowdsourcing has established itself as an efficient labeling solution through resorting to non-expert crowds. To reduce the labeling error effects, one common practice is to distribute each instance to multiple workers, whereas each worker only annotates a subset of data, resulting in the {\it sparse annotation} phenomenon. In this paper, we note that when meeting with class-imbalance, i.e., when the ground truth labels are {\it class-imbalanced}, the sparse annotations are prone to be skewly distributed, which thus can severely bias the learning algorithm. To combat this issue, we propose one self-training based approach named {\it Self-Crowd} by progressively adding confident pseudo-annotations and rebalancing the annotation distribution. Specifically, we propose one distribution aware confidence measure to select confident pseudo-annotations, which adopts the resampling strategy to oversample the minority annotations and undersample the majority annotations. On one real-world crowdsourcing image classification task, we show that the proposed method yields more balanced annotations throughout training than the distribution agnostic methods and substantially improves the learning performance at different annotation sparsity levels.
Multi-Label Active Learning from Crowds
Aug 04, 2015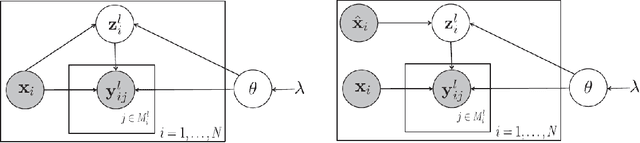
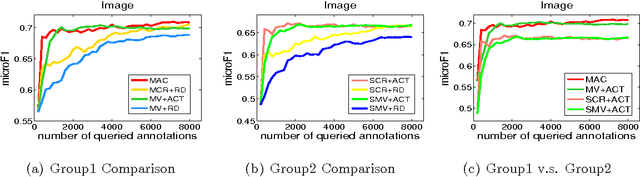
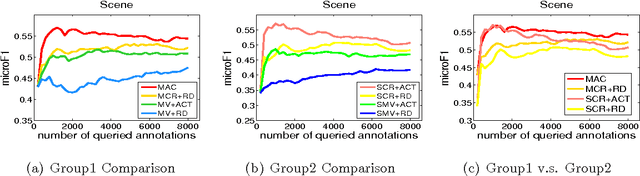
Multi-label active learning is a hot topic in reducing the label cost by optimally choosing the most valuable instance to query its label from an oracle. In this paper, we consider the poolbased multi-label active learning under the crowdsourcing setting, where during the active query process, instead of resorting to a high cost oracle for the ground-truth, multiple low cost imperfect annotators with various expertise are available for labeling. To deal with this problem, we propose the MAC (Multi-label Active learning from Crowds) approach which incorporate the local influence of label correlations to build a probabilistic model over the multi-label classifier and annotators. Based on this model, we can estimate the labels for instances as well as the expertise of each annotator. Then we propose the instance selection and annotator selection criteria that consider the uncertainty/diversity of instances and the reliability of annotators, such that the most reliable annotator will be queried for the most valuable instances. Experimental results demonstrate the effectiveness of the proposed approach.