 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Crowds with Sparse and Imbalanced Annotations
Paper and Code
Jul 11, 2021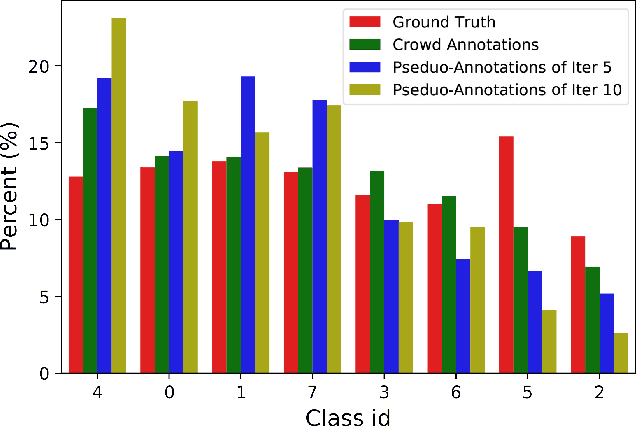
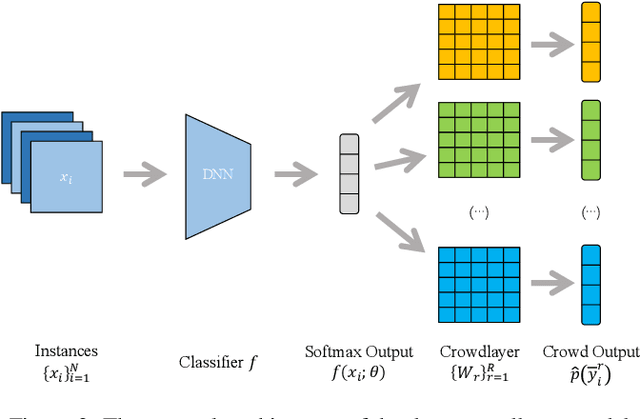
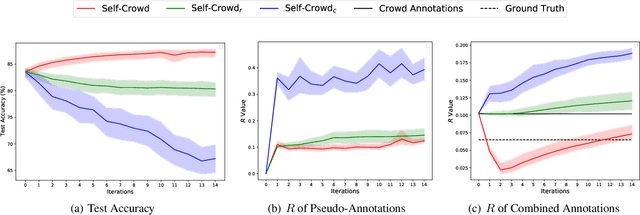
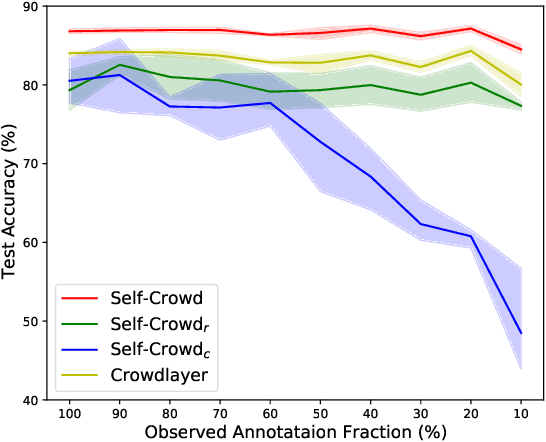
Traditional supervised learning requires ground truth labels for the training data, whose collection can be difficult in many cases. Recently, crowdsourcing has established itself as an efficient labeling solution through resorting to non-expert crowds. To reduce the labeling error effects, one common practice is to distribute each instance to multiple workers, whereas each worker only annotates a subset of data, resulting in the {\it sparse annotation} phenomenon. In this paper, we note that when meeting with class-imbalance, i.e., when the ground truth labels are {\it class-imbalanced}, the sparse annotations are prone to be skewly distributed, which thus can severely bias the learning algorithm. To combat this issue, we propose one self-training based approach named {\it Self-Crowd} by progressively adding confident pseudo-annotations and rebalancing the annotation distribution. Specifically, we propose one distribution aware confidence measure to select confident pseudo-annotations, which adopts the resampling strategy to oversample the minority annotations and undersample the majority annotations. On one real-world crowdsourcing image classification task, we show that the proposed method yields more balanced annotations throughout training than the distribution agnostic methods and substantially improves the learning performance at different annotation sparsity levels.