 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Active Learning Under Extreme Non-IID and Global Class Imbalance
Mar 11, 2026Federated active learning (FAL) seeks to reduce annotation cost under privacy constraints, yet its effectiveness degrades in realistic settings with severe global class imbalance and highly heterogeneous clients. We conduct a systematic study of query-model selection in FAL and uncover a central insight: the model that achieves more class-balanced sampling, especially for minority classes, consistently leads to better final performance. Moreover, global-model querying is beneficial only when the global distribution is highly imbalanced and client data are relatively homogeneous; otherwise, the local model is preferable. Based on these findings, we propose FairFAL, an adaptive class-fair FAL framework. FairFAL (1) infers global imbalance and local-global divergence via lightweight prediction discrepancy, enabling adaptive selection between global and local query models; (2) performs prototype-guided pseudo-labeling using global features to promote class-aware querying; and (3) applies a two-stage uncertainty-diversity balanced sampling strategy with k-center refinement. Experiments on five benchmarks show that FairFAL consistently outperforms state-of-the-art approaches under challenging long-tailed and non-IID settings. The code is available at https://github.com/chenchenzong/FairFAL.
Revisiting Unknowns: Towards Effective and Efficient Open-Set Active Learning
Mar 09, 2026Open-set active learning (OSAL) aims to identify informative samples for annotation when unlabeled data may contain previously unseen classes-a common challenge in safety-critical and open-world scenarios. Existing approaches typically rely on separately trained open-set detectors, introducing substantial training overhead and overlooking the supervisory value of labeled unknowns for improving known-class learning. In this paper, we propose E$^2$OAL (Effective and Efficient Open-set Active Learning), a unified and detector-free framework that fully exploits labeled unknowns for both stronger supervision and more reliable querying. E$^2$OAL first uncovers the latent class structure of unknowns through label-guided clustering in a frozen contrastively pre-trained feature space, optimized by a structure-aware F1-product objective. To leverage labeled unknowns, it employs a Dirichlet-calibrated auxiliary head that jointly models known and unknown categories, improving both confidence calibration and known-class discrimination. Building on this, a logit-margin purity score estimates the likelihood of known classes to construct a high-purity candidate pool, while an OSAL-specific informativeness metric prioritizes partially ambiguous yet reliable samples. These components together form a flexible two-stage query strategy with adaptive precision control and minimal hyperparameter sensitivity. Extensive experiments across multiple OSAL benchmarks demonstrate that E$^2$OAL consistently surpasses state-of-the-art methods in accuracy, efficiency, and query precision, highlighting its effectiveness and practicality for real-world applications. The code is available at github.com/chenchenzong/E2OAL.
Continuous Exposure-Time Modeling for Realistic Atmospheric Turbulence Synthesis
Mar 03, 2026Atmospheric turbulence significantly degrades long-range imaging by introducing geometric warping and exposure-time-dependent blur, which adversely affects both visual quality and the performance of high-level vision tasks. Existing methods for synthesizing turbulence effects often oversimplify the relationship between blur and exposure-time, typically assuming fixed or binary exposure settings. This leads to unrealistic synthetic data and limited generalization capability of trained models. To address this gap, we revisit the modulation transfer function (MTF) formulation and propose a novel Exposure-Time-dependent MTF (ET-MTF) that models blur as a continuous function of exposure-time. For blur synthesis, we derive a tilt-invariant point spread function (PSF) from the ET-MTF, which, when integrated with a spatially varying blur-width field, provides a comprehensive and physically accurate characterization of turbulence-induced blur. Building on this synthesis pipeline, we construct ET-Turb, a large-scale synthetic turbulence dataset that explicitly incorporates continuous exposure-time modeling across diverse optical and atmospheric conditions. The dataset comprises 5,083 videos (2,005,835 frames), partitioned into 3,988 training and 1,095 test videos. Extensive experiments demonstrate that models trained on ET-Turb produce more realistic restorations and achieve superior generalization on real-world turbulence data compared to those trained on other datasets. The dataset is publicly available at: github.com/Jun-Wei-Zeng/ET-Turb.
Compress the Easy, Explore the Hard: Difficulty-Aware Entropy Regularization for Efficient LLM Reasoning
Feb 26, 2026Chain-of-Thought (CoT) has substantially empowered Large Language Models (LLMs) to tackle complex reasoning tasks, yet the verbose nature of explicit reasoning steps incurs prohibitive inference latency and computational costs, limiting real-world deployment. While existing compression methods - ranging from self-training to Reinforcement Learning (RL) with length constraints - attempt to mitigate this, they often sacrifice reasoning capability for brevity. We identify a critical failure mode in these approaches: explicitly optimizing for shorter trajectories triggers rapid entropy collapse, which prematurely shrinks the exploration space and stifles the discovery of valid reasoning paths, particularly for challenging questions requiring extensive deduction. To address this issue, we propose Compress responses for Easy questions and Explore Hard ones (CEEH), a difficulty-aware approach to RL-based efficient reasoning. CEEH dynamically assesses instance difficulty to apply selective entropy regularization: it preserves a diverse search space for currently hard questions to ensure robustness, while permitting aggressive compression on easier instances where the reasoning path is well-established. In addition, we introduce a dynamic optimal-length penalty anchored to the historically shortest correct response, which effectively counteracts entropy-induced length inflation and stabilizes the reward signal. Across six reasoning benchmarks, CEEH consistently reduces response length while maintaining accuracy comparable to the base model, and improves Pass@k relative to length-only optimization.
History-Guided Iterative Visual Reasoning with Self-Correction
Feb 04, 2026Self-consistency methods are the core technique for improving the reasoning reliability of multimodal large language models (MLLMs). By generating multiple reasoning results through repeated sampling and selecting the best answer via voting, they play an important role in cross-modal tasks. However, most existing self-consistency methods are limited to a fixed ``repeated sampling and voting'' paradigm and do not reuse historical reasoning information. As a result, models struggle to actively correct visual understanding errors and dynamically adjust their reasoning during iteration. Inspired by the human reasoning behavior of repeated verification and dynamic error correction, we propose the H-GIVR framework. During iterative reasoning, the MLLM observes the image multiple times and uses previously generated answers as references for subsequent steps, enabling dynamic correction of errors and improving answer accuracy. We conduct comprehensive experiments on five datasets and three models. The results show that the H-GIVR framework can significantly improve cross-modal reasoning accuracy while maintaining low computational cost. For instance, using \texttt{Llama3.2-vision:11b} on the ScienceQA dataset, the model requires an average of 2.57 responses per question to achieve an accuracy of 78.90\%, representing a 107\% improvement over the baseline.
SafeThinker: Reasoning about Risk to Deepen Safety Beyond Shallow Alignment
Jan 23, 2026Despite the intrinsic risk-awareness of Large Language Models (LLMs), current defenses often result in shallow safety alignment, rendering models vulnerable to disguised attacks (e.g., prefilling) while degrading utility. To bridge this gap, we propose SafeThinker, an adaptive framework that dynamically allocates defensive resources via a lightweight gateway classifier. Based on the gateway's risk assessment, inputs are routed through three distinct mechanisms: (i) a Standardized Refusal Mechanism for explicit threats to maximize efficiency; (ii) a Safety-Aware Twin Expert (SATE) module to intercept deceptive attacks masquerading as benign queries; and (iii) a Distribution-Guided Think (DDGT) component that adaptively intervenes during uncertain generation. Experiments show that SafeThinker significantly lowers attack success rates across diverse jailbreak strategies without compromising utility, demonstrating that coordinating intrinsic judgment throughout the generation process effectively balances robustness and practicality.
Beyond Superficial Unlearning: Sharpness-Aware Robust Erasure of Hallucinations in Multimodal LLMs
Jan 23, 2026Multimodal LLMs are powerful but prone to object hallucinations, which describe non-existent entities and harm reliability. While recent unlearning methods attempt to mitigate this, we identify a critical flaw: structural fragility. We empirically demonstrate that standard erasure achieves only superficial suppression, trapping the model in sharp minima where hallucinations catastrophically resurge after lightweight relearning. To ensure geometric stability, we propose SARE, which casts unlearning as a targeted min-max optimization problem and uses a Targeted-SAM mechanism to explicitly flatten the loss landscape around hallucinated concepts. By suppressing hallucinations under simulated worst-case parameter perturbations, our framework ensures robust removal stable against weight shifts. Extensive experiments demonstrate that SARE significantly outperforms baselines in erasure efficacy while preserving general generation quality. Crucially, it maintains persistent hallucination suppression against relearning and parameter updates, validating the effectiveness of geometric stabilization.
Retrieval-augmented Prompt Learning for Pre-trained Foundation Models
Dec 23, 2025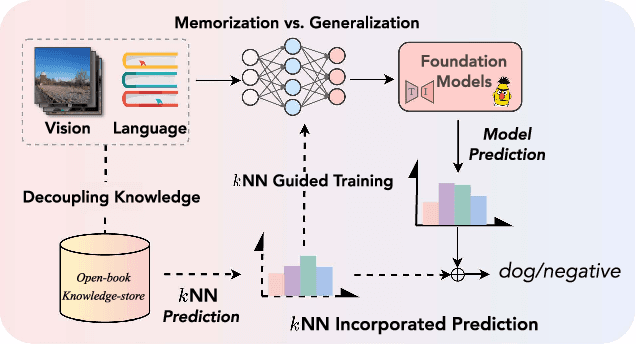
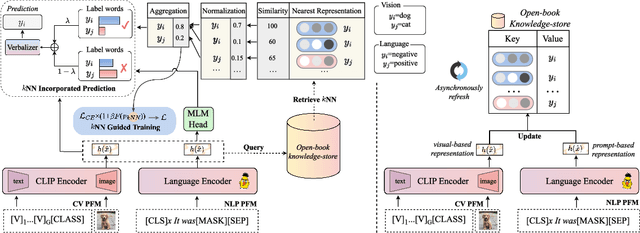
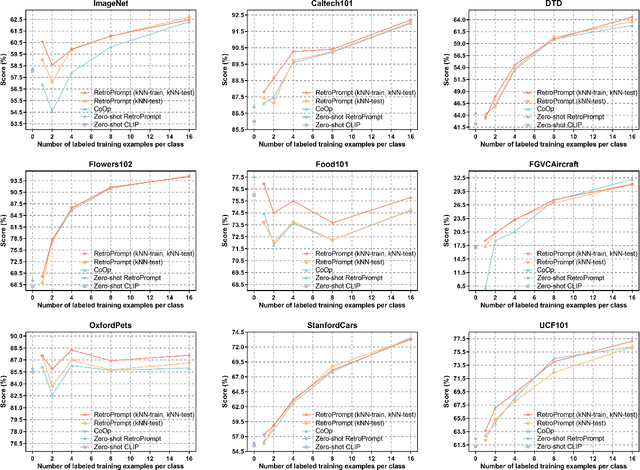
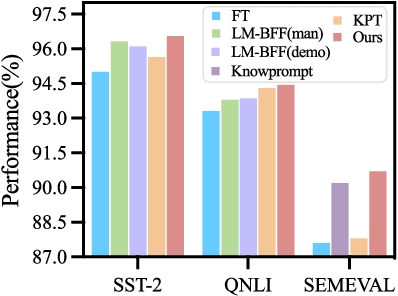
The pre-trained foundation models (PFMs) have become essential for facilitating large-scale multimodal learning. Researchers have effectively employed the ``pre-train, prompt, and predict'' paradigm through prompt learning to induce improved few-shot performance. However, prompt learning approaches for PFMs still follow a parametric learning paradigm. As such, the stability of generalization in memorization and rote learning can be compromised. More specifically, conventional prompt learning might face difficulties in fully utilizing atypical instances and avoiding overfitting to shallow patterns with limited data during the process of fully-supervised training. To overcome these constraints, we present our approach, named RetroPrompt, which aims to achieve a balance between memorization and generalization by decoupling knowledge from mere memorization. Unlike traditional prompting methods, RetroPrompt leverages a publicly accessible knowledge base generated from the training data and incorporates a retrieval mechanism throughout the input, training, and inference stages. This enables the model to actively retrieve relevant contextual information from the corpus, thereby enhancing the available cues. We conduct comprehensive experiments on a variety of datasets across natural language processing and computer vision tasks to demonstrate the superior performance of our proposed approach, RetroPrompt, in both zero-shot and few-shot scenarios. Through detailed analysis of memorization patterns, we observe that RetroPrompt effectively reduces the reliance on rote memorization, leading to enhanced generalization.
Tailored Teaching with Balanced Difficulty: Elevating Reasoning in Multimodal Chain-of-Thought via Prompt Curriculum
Aug 26, 2025The effectiveness of Multimodal Chain-of-Thought (MCoT) prompting is often limited by the use of randomly or manually selected examples. These examples fail to account for both model-specific knowledge distributions and the intrinsic complexity of the tasks, resulting in suboptimal and unstable model performance. To address this, we propose a novel framework inspired by the pedagogical principle of "tailored teaching with balanced difficulty". We reframe prompt selection as a prompt curriculum design problem: constructing a well ordered set of training examples that align with the model's current capabilities. Our approach integrates two complementary signals: (1) model-perceived difficulty, quantified through prediction disagreement in an active learning setup, capturing what the model itself finds challenging; and (2) intrinsic sample complexity, which measures the inherent difficulty of each question-image pair independently of any model. By jointly analyzing these signals, we develop a difficulty-balanced sampling strategy that ensures the selected prompt examples are diverse across both dimensions. Extensive experiments conducted on five challenging benchmarks and multiple popular Multimodal Large Language Models (MLLMs) demonstrate that our method yields substantial and consistent improvements and greatly reduces performance discrepancies caused by random sampling, providing a principled and robust approach for enhancing multimodal reasoning.
MultiMedEdit: A Scenario-Aware Benchmark for Evaluating Knowledge Editing in Medical VQA
Aug 09, 2025Knowledge editing (KE) provides a scalable approach for updating factual knowledge in large language models without full retraining. While previous studies have demonstrated effectiveness in general domains and medical QA tasks, little attention has been paid to KE in multimodal medical scenarios. Unlike text-only settings, medical KE demands integrating updated knowledge with visual reasoning to support safe and interpretable clinical decisions. To address this gap, we propose MultiMedEdit, the first benchmark tailored to evaluating KE in clinical multimodal tasks. Our framework spans both understanding and reasoning task types, defines a three-dimensional metric suite (reliability, generality, and locality), and supports cross-paradigm comparisons across general and domain-specific models. We conduct extensive experiments under single-editing and lifelong-editing settings. Results suggest that current methods struggle with generalization and long-tail reasoning, particularly in complex clinical workflows. We further present an efficiency analysis (e.g., edit latency, memory footprint), revealing practical trade-offs in real-world deployment across KE paradigms. Overall, MultiMedEdit not only reveals the limitations of current approaches but also provides a solid foundation for developing clinically robust knowledge editing techniques in the future.