 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-augmented Prompt Learning for Pre-trained Foundation Models
Dec 23, 2025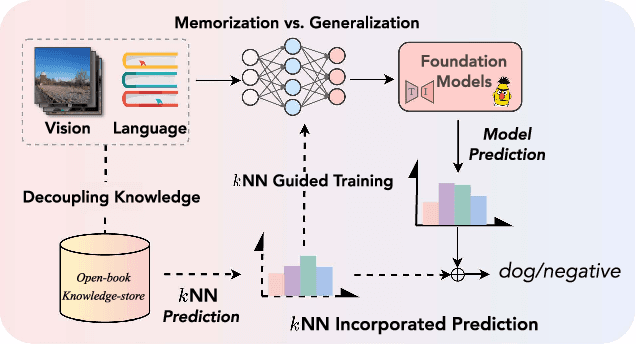
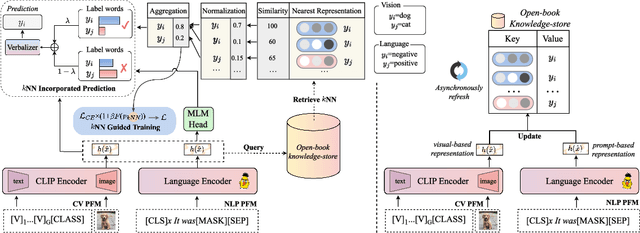
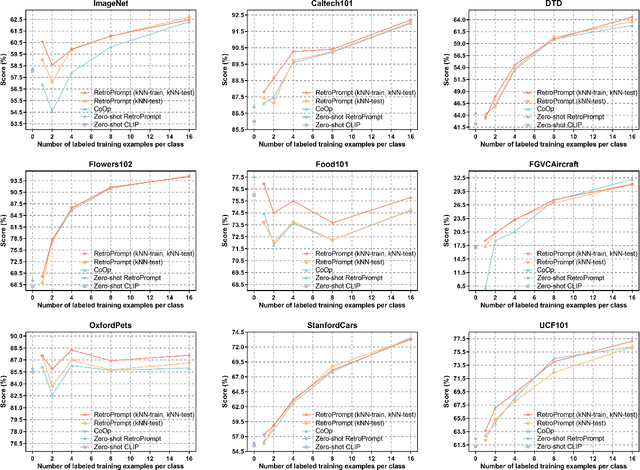
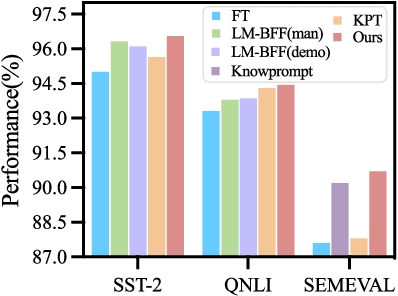
The pre-trained foundation models (PFMs) have become essential for facilitating large-scale multimodal learning. Researchers have effectively employed the ``pre-train, prompt, and predict'' paradigm through prompt learning to induce improved few-shot performance. However, prompt learning approaches for PFMs still follow a parametric learning paradigm. As such, the stability of generalization in memorization and rote learning can be compromised. More specifically, conventional prompt learning might face difficulties in fully utilizing atypical instances and avoiding overfitting to shallow patterns with limited data during the process of fully-supervised training. To overcome these constraints, we present our approach, named RetroPrompt, which aims to achieve a balance between memorization and generalization by decoupling knowledge from mere memorization. Unlike traditional prompting methods, RetroPrompt leverages a publicly accessible knowledge base generated from the training data and incorporates a retrieval mechanism throughout the input, training, and inference stages. This enables the model to actively retrieve relevant contextual information from the corpus, thereby enhancing the available cues. We conduct comprehensive experiments on a variety of datasets across natural language processing and computer vision tasks to demonstrate the superior performance of our proposed approach, RetroPrompt, in both zero-shot and few-shot scenarios. Through detailed analysis of memorization patterns, we observe that RetroPrompt effectively reduces the reliance on rote memorization, leading to enhanced generalization.
Tailored Teaching with Balanced Difficulty: Elevating Reasoning in Multimodal Chain-of-Thought via Prompt Curriculum
Aug 26, 2025The effectiveness of Multimodal Chain-of-Thought (MCoT) prompting is often limited by the use of randomly or manually selected examples. These examples fail to account for both model-specific knowledge distributions and the intrinsic complexity of the tasks, resulting in suboptimal and unstable model performance. To address this, we propose a novel framework inspired by the pedagogical principle of "tailored teaching with balanced difficulty". We reframe prompt selection as a prompt curriculum design problem: constructing a well ordered set of training examples that align with the model's current capabilities. Our approach integrates two complementary signals: (1) model-perceived difficulty, quantified through prediction disagreement in an active learning setup, capturing what the model itself finds challenging; and (2) intrinsic sample complexity, which measures the inherent difficulty of each question-image pair independently of any model. By jointly analyzing these signals, we develop a difficulty-balanced sampling strategy that ensures the selected prompt examples are diverse across both dimensions. Extensive experiments conducted on five challenging benchmarks and multiple popular Multimodal Large Language Models (MLLMs) demonstrate that our method yields substantial and consistent improvements and greatly reduces performance discrepancies caused by random sampling, providing a principled and robust approach for enhancing multimodal reasoning.
CMTNet: Convolutional Meets Transformer Network for Hyperspectral Images Classification
Jun 20, 2024Hyperspectral remote sensing (HIS) enables the detailed capture of spectral information from the Earth's surface, facilitating precise classification and identification of surface crops due to its superior spectral diagnostic capabilities. However, current convolutional neural networks (CNNs) focus on local features in hyperspectral data, leading to suboptimal performance when classifying intricate crop types and addressing imbalanced sample distributions. In contrast, the Transformer framework excels at extracting global features from hyperspectral imagery. To leverage the strengths of both approaches, this research introduces the Convolutional Meet Transformer Network (CMTNet). This innovative model includes a spectral-spatial feature extraction module for shallow feature capture, a dual-branch structure combining CNN and Transformer branches for local and global feature extraction, and a multi-output constraint module that enhances classification accuracy through multi-output loss calculations and cross constraints across local, international, and joint features. Extensive experiments conducted on three datasets (WHU-Hi-LongKou, WHU-Hi-HanChuan, and WHU-Hi-HongHu) demonstrate that CTDBNet significantly outperforms other state-of-the-art networks in classification performance, validating its effectiveness in hyperspectral crop classification.
Deep Semi-supervised Learning with Double-Contrast of Features and Semantics
Nov 28, 2022



In recent years, the field of intelligent transportation systems (ITS) has achieved remarkable success, which is mainly due to the large amount of available annotation data. However, obtaining these annotated data has to afford expensive costs in reality. Therefore, a more realistic strategy is to leverage semi-supervised learning (SSL) with a small amount of labeled data and a large amount of unlabeled data. Typically, semantic consistency regularization and the two-stage learning methods of decoupling feature extraction and classification have been proven effective. Nevertheless, representation learning only limited to semantic consistency regularization may not guarantee the separation or discriminability of representations of samples with different semantics; due to the inherent limitations of the two-stage learning methods, the extracted features may not match the specific downstream tasks. In order to deal with the above drawbacks, this paper proposes an end-to-end deep semi-supervised learning double contrast of semantic and feature, which extracts effective tasks specific discriminative features by contrasting the semantics/features of positive and negative augmented samples pairs. Moreover, we leverage information theory to explain the rationality of double contrast of semantics and features and slack mutual information to contrastive loss in a simpler way. Finally, the effectiveness of our method is verified in benchmark datasets.
Learning Downstream Task by Selectively Capturing Complementary Knowledge from Multiple Self-supervisedly Learning Pretexts
Apr 11, 2022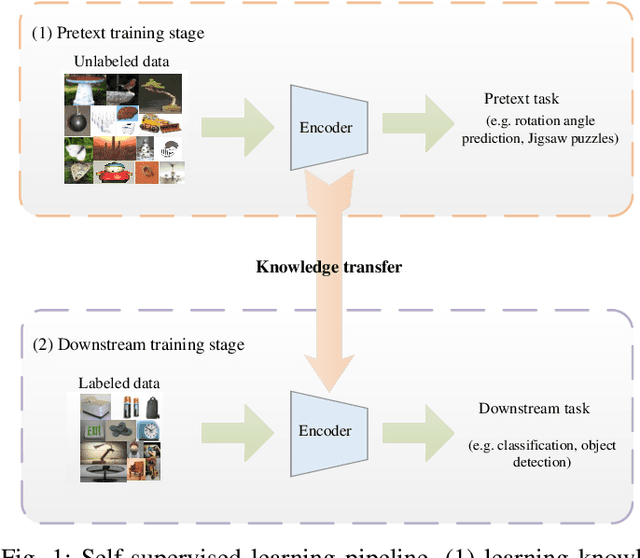

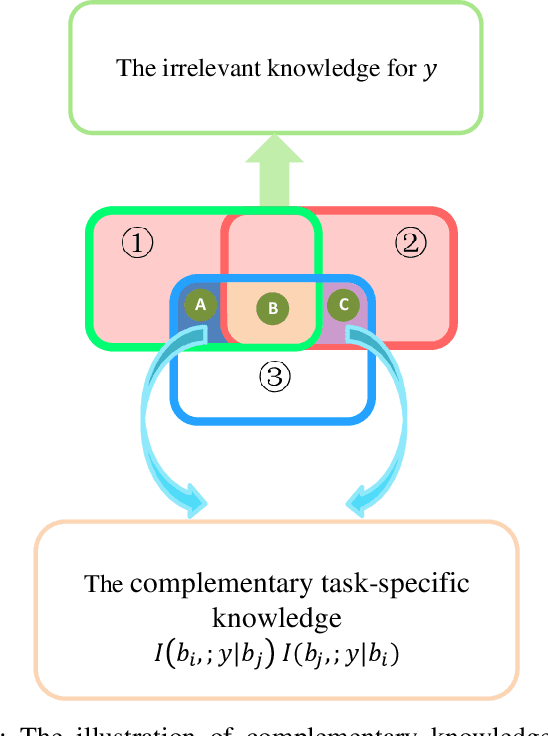
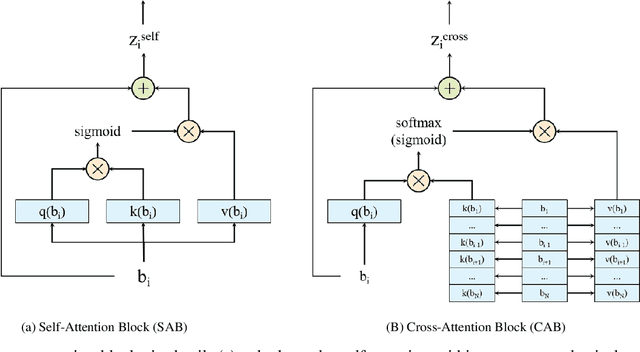
Self-supervised learning (SSL), as a newly emerging unsupervised representation learning paradigm, generally follows a two-stage learning pipeline: 1) learning invariant and discriminative representations with auto-annotation pretext(s), then 2) transferring the representations to assist downstream task(s). Such two stages are usually implemented separately, making the learned representation learned agnostic to the downstream tasks. Currently, most works are devoted to exploring the first stage. Whereas, it is less studied on how to learn downstream tasks with limited labeled data using the already learned representations. Especially, it is crucial and challenging to selectively utilize the complementary representations from diverse pretexts for a downstream task. In this paper, we technically propose a novel solution by leveraging the attention mechanism to adaptively squeeze suitable representations for the tasks. Meanwhile, resorting to information theory, we theoretically prove that gathering representation from diverse pretexts is more effective than a single one. Extensive experiments validate that our scheme significantly exceeds current popular pretext-matching based methods in gathering knowledge and relieving negative transfer in downstream tasks.
Learning Multi-Tasks with Inconsistent Labels by using Auxiliary Big Task
Jan 07, 2022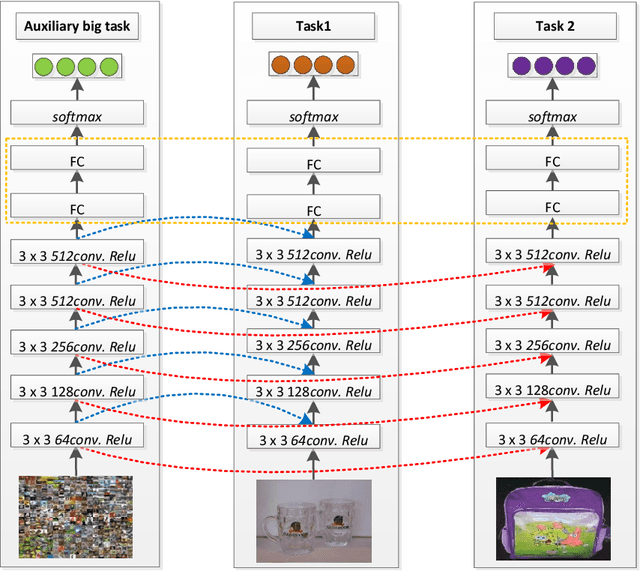

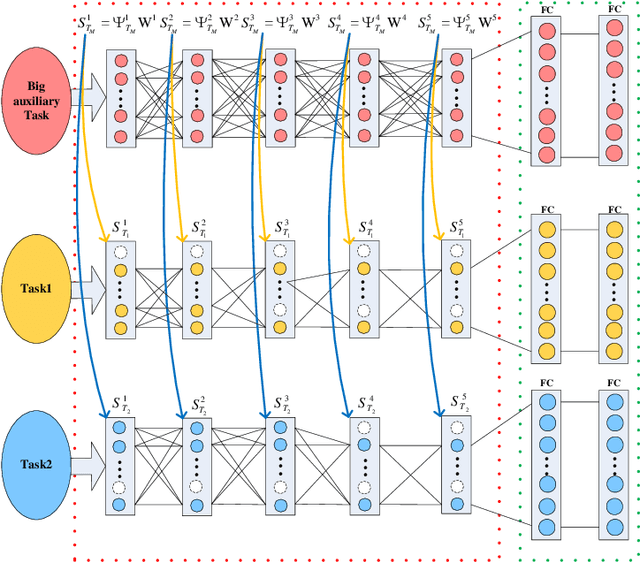
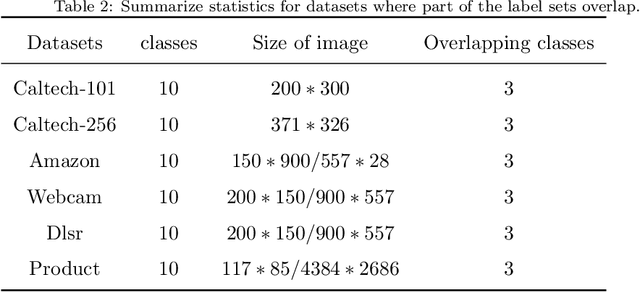
Multi-task learning is to improve the performance of the model by transferring and exploiting common knowledge among tasks. Existing MTL works mainly focus on the scenario where label sets among multiple tasks (MTs) are usually the same, thus they can be utilized for learning across the tasks. While almost rare works explore the scenario where each task only has a small amount of training samples, and their label sets are just partially overlapped or even not. Learning such MTs is more challenging because of less correlation information available among these tasks. For this, we propose a framework to learn these tasks by jointly leveraging both abundant information from a learnt auxiliary big task with sufficiently many classes to cover those of all these tasks and the information shared among those partially-overlapped tasks. In our implementation of using the same neural network architecture of the learnt auxiliary task to learn individual tasks, the key idea is to utilize available label information to adaptively prune the hidden layer neurons of the auxiliary network to construct corresponding network for each task, while accompanying a joint learning across individual tasks. Our experimental results demonstrate its effectiveness in comparison with the state-of-the-art approaches.
Learning Twofold Heterogeneous Multi-Task by Sharing Similar Convolution Kernel Pairs
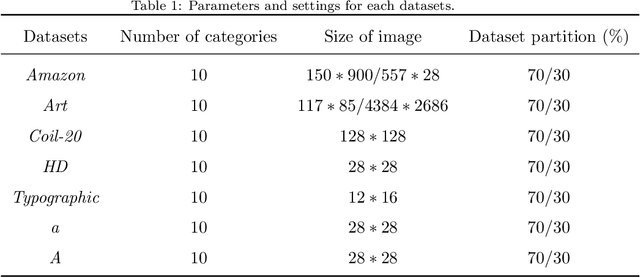
Jan 29, 2021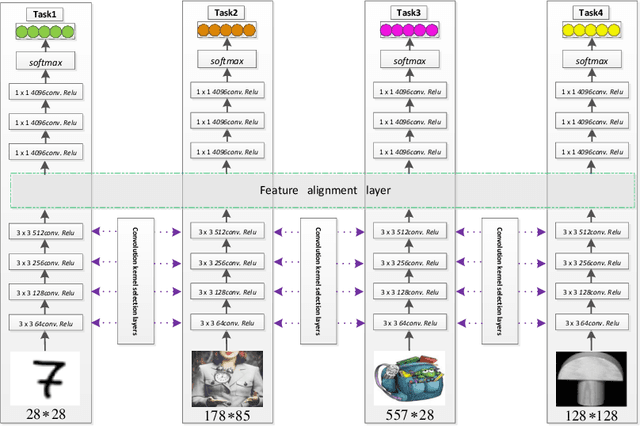
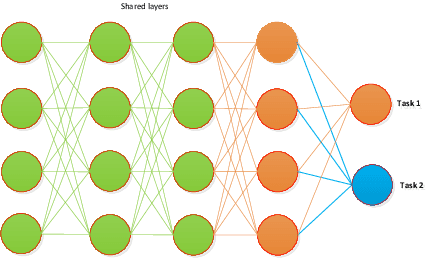
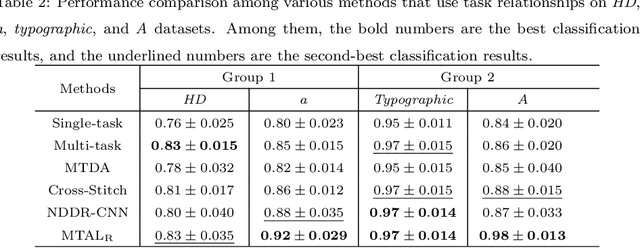
Heterogeneous multi-task learning (HMTL) is an important topic in multi-task learning (MTL). Most existing HMTL methods usually solve either scenario where all tasks reside in the same input (feature) space yet unnecessarily the consistent output (label) space or scenario where their input (feature) spaces are heterogeneous while the output (label) space is consistent. However, to the best of our knowledge, there is limited study on twofold heterogeneous MTL (THMTL) scenario where the input and the output spaces are both inconsistent or heterogeneous. In order to handle this complicated scenario, in this paper, we design a simple and effective multi-task adaptive learning (MTAL) network to learn multiple tasks in such THMTL setting. Specifically, we explore and utilize the inherent relationship between tasks for knowledge sharing from similar convolution kernels in individual layers of the MTAL network. Then in order to realize the sharing, we weightedly aggregate any pair of convolutional kernels with their similarity greater than some threshold $\rho$, consequently, our model effectively performs cross-task learning while suppresses the intra-redundancy of the entire network. Finally, we conduct end-to-end training. Our experimental results demonstrate the effectiveness of our method in comparison with the state-of-the-art counterparts.