 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Active Learning Under Extreme Non-IID and Global Class Imbalance
Mar 11, 2026Federated active learning (FAL) seeks to reduce annotation cost under privacy constraints, yet its effectiveness degrades in realistic settings with severe global class imbalance and highly heterogeneous clients. We conduct a systematic study of query-model selection in FAL and uncover a central insight: the model that achieves more class-balanced sampling, especially for minority classes, consistently leads to better final performance. Moreover, global-model querying is beneficial only when the global distribution is highly imbalanced and client data are relatively homogeneous; otherwise, the local model is preferable. Based on these findings, we propose FairFAL, an adaptive class-fair FAL framework. FairFAL (1) infers global imbalance and local-global divergence via lightweight prediction discrepancy, enabling adaptive selection between global and local query models; (2) performs prototype-guided pseudo-labeling using global features to promote class-aware querying; and (3) applies a two-stage uncertainty-diversity balanced sampling strategy with k-center refinement. Experiments on five benchmarks show that FairFAL consistently outperforms state-of-the-art approaches under challenging long-tailed and non-IID settings. The code is available at https://github.com/chenchenzong/FairFAL.
Revisiting Unknowns: Towards Effective and Efficient Open-Set Active Learning
Mar 09, 2026Open-set active learning (OSAL) aims to identify informative samples for annotation when unlabeled data may contain previously unseen classes-a common challenge in safety-critical and open-world scenarios. Existing approaches typically rely on separately trained open-set detectors, introducing substantial training overhead and overlooking the supervisory value of labeled unknowns for improving known-class learning. In this paper, we propose E$^2$OAL (Effective and Efficient Open-set Active Learning), a unified and detector-free framework that fully exploits labeled unknowns for both stronger supervision and more reliable querying. E$^2$OAL first uncovers the latent class structure of unknowns through label-guided clustering in a frozen contrastively pre-trained feature space, optimized by a structure-aware F1-product objective. To leverage labeled unknowns, it employs a Dirichlet-calibrated auxiliary head that jointly models known and unknown categories, improving both confidence calibration and known-class discrimination. Building on this, a logit-margin purity score estimates the likelihood of known classes to construct a high-purity candidate pool, while an OSAL-specific informativeness metric prioritizes partially ambiguous yet reliable samples. These components together form a flexible two-stage query strategy with adaptive precision control and minimal hyperparameter sensitivity. Extensive experiments across multiple OSAL benchmarks demonstrate that E$^2$OAL consistently surpasses state-of-the-art methods in accuracy, efficiency, and query precision, highlighting its effectiveness and practicality for real-world applications. The code is available at github.com/chenchenzong/E2OAL.
Rethinking Epistemic and Aleatoric Uncertainty for Active Open-Set Annotation: An Energy-Based Approach
Feb 27, 2025



Active learning (AL), which iteratively queries the most informative examples from a large pool of unlabeled candidates for model training, faces significant challenges in the presence of open-set classes. Existing methods either prioritize query examples likely to belong to known classes, indicating low epistemic uncertainty (EU), or focus on querying those with highly uncertain predictions, reflecting high aleatoric uncertainty (AU). However, they both yield suboptimal performance, as low EU corresponds to limited useful information, and closed-set AU metrics for unknown class examples are less meaningful. In this paper, we propose an Energy-based Active Open-set Annotation (EAOA) framework, which effectively integrates EU and AU to achieve superior performance. EAOA features a $(C+1)$-class detector and a target classifier, incorporating an energy-based EU measure and a margin-based energy loss designed for the detector, alongside an energy-based AU measure for the target classifier. Another crucial component is the target-driven adaptive sampling strategy. It first forms a smaller candidate set with low EU scores to ensure closed-set properties, making AU metrics meaningful. Subsequently, examples with high AU scores are queried to form the final query set, with the candidate set size adjusted adaptively. Extensive experiments show that EAOA achieves state-of-the-art performance while maintaining high query precision and low training overhead. The code is available at https://github.com/chenchenzong/EAOA.
Dual-Head Knowledge Distillation: Enhancing Logits Utilization with an Auxiliary Head
Nov 13, 2024



Traditional knowledge distillation focuses on aligning the student's predicted probabilities with both ground-truth labels and the teacher's predicted probabilities. However, the transition to predicted probabilities from logits would obscure certain indispensable information. To address this issue, it is intuitive to additionally introduce a logit-level loss function as a supplement to the widely used probability-level loss function, for exploiting the latent information of logits. Unfortunately, we empirically find that the amalgamation of the newly introduced logit-level loss and the previous probability-level loss will lead to performance degeneration, even trailing behind the performance of employing either loss in isolation. We attribute this phenomenon to the collapse of the classification head, which is verified by our theoretical analysis based on the neural collapse theory. Specifically, the gradients of the two loss functions exhibit contradictions in the linear classifier yet display no such conflict within the backbone. Drawing from the theoretical analysis, we propose a novel method called dual-head knowledge distillation, which partitions the linear classifier into two classification heads responsible for different losses, thereby preserving the beneficial effects of both losses on the backbone while eliminating adverse influences on the classification head. Extensive experiments validate that our method can effectively exploit the information inside the logits and achieve superior performance against state-of-the-art counterparts.
Dirichlet-Based Coarse-to-Fine Example Selection For Open-Set Annotation
Sep 26, 2024



Active learning (AL) has achieved great success by selecting the most valuable examples from unlabeled data. However, they usually deteriorate in real scenarios where open-set noise gets involved, which is studied as open-set annotation (OSA). In this paper, we owe the deterioration to the unreliable predictions arising from softmax-based translation invariance and propose a Dirichlet-based Coarse-to-Fine Example Selection (DCFS) strategy accordingly. Our method introduces simplex-based evidential deep learning (EDL) to break translation invariance and distinguish known and unknown classes by considering evidence-based data and distribution uncertainty simultaneously. Furthermore, hard known-class examples are identified by model discrepancy generated from two classifier heads, where we amplify and alleviate the model discrepancy respectively for unknown and known classes. Finally, we combine the discrepancy with uncertainties to form a two-stage strategy, selecting the most informative examples from known classes. Extensive experiments on various openness ratio datasets demonstrate that DCFS achieves state-of-art performance.
Bidirectional Uncertainty-Based Active Learning for Open Set Annotation
Feb 23, 2024Active learning (AL) in open set scenarios presents a novel challenge of identifying the most valuable examples in an unlabeled data pool that comprises data from both known and unknown classes. Traditional methods prioritize selecting informative examples with low confidence, with the risk of mistakenly selecting unknown-class examples with similarly low confidence. Recent methods favor the most probable known-class examples, with the risk of picking simple already mastered examples. In this paper, we attempt to query examples that are both likely from known classes and highly informative, and propose a \textit{Bidirectional Uncertainty-based Active Learning} (BUAL) framework. Specifically, we achieve this by first pushing the unknown class examples toward regions with high-confidence predictions with our proposed \textit{Random Label Negative Learning} method. Then, we propose a \textit{Bidirectional Uncertainty sampling} strategy by jointly estimating uncertainty posed by both positive and negative learning to perform consistent and stable sampling. BUAL successfully extends existing uncertainty-based AL methods to complex open-set scenarios. Extensive experiments on multiple datasets with varying openness demonstrate that BUAL achieves state-of-the-art performance.
Dirichlet-Based Prediction Calibration for Learning with Noisy Labels
Jan 13, 2024Learning with noisy labels can significantly hinder the generalization performance of deep neural networks (DNNs). Existing approaches address this issue through loss correction or example selection methods. However, these methods often rely on the model's predictions obtained from the softmax function, which can be over-confident and unreliable. In this study, we identify the translation invariance of the softmax function as the underlying cause of this problem and propose the \textit{Dirichlet-based Prediction Calibration} (DPC) method as a solution. Our method introduces a calibrated softmax function that breaks the translation invariance by incorporating a suitable constant in the exponent term, enabling more reliable model predictions. To ensure stable model training, we leverage a Dirichlet distribution to assign probabilities to predicted labels and introduce a novel evidence deep learning (EDL) loss. The proposed loss function encourages positive and sufficiently large logits for the given label, while penalizing negative and small logits for other labels, leading to more distinct logits and facilitating better example selection based on a large-margin criterion. Through extensive experiments on diverse benchmark datasets, we demonstrate that DPC achieves state-of-the-art performance. The code is available at https://github.com/chenchenzong/DPC.
Multi-Label Knowledge Distillation
Aug 12, 2023
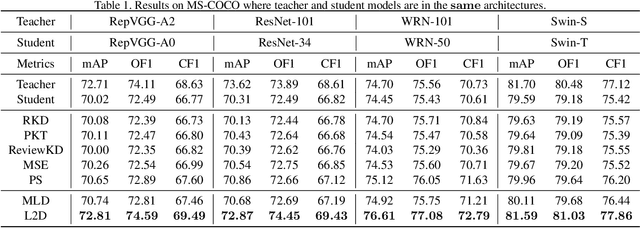
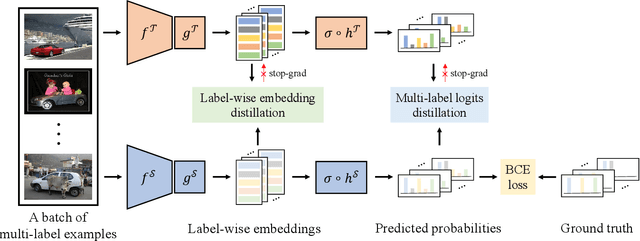
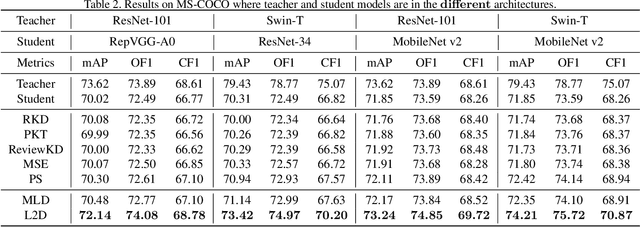
Existing knowledge distillation methods typically work by imparting the knowledge of output logits or intermediate feature maps from the teacher network to the student network, which is very successful in multi-class single-label learning. However, these methods can hardly be extended to the multi-label learning scenario, where each instance is associated with multiple semantic labels, because the prediction probabilities do not sum to one and feature maps of the whole example may ignore minor classes in such a scenario. In this paper, we propose a novel multi-label knowledge distillation method. On one hand, it exploits the informative semantic knowledge from the logits by dividing the multi-label learning problem into a set of binary classification problems; on the other hand, it enhances the distinctiveness of the learned feature representations by leveraging the structural information of label-wise embeddings. Experimental results on multiple benchmark datasets validate that the proposed method can avoid knowledge counteraction among labels, thus achieving superior performance against diverse comparing methods. Our code is available at: https://github.com/penghui-yang/L2D
Noise-Robust Bidirectional Learning with Dynamic Sample Reweighting
Sep 03, 2022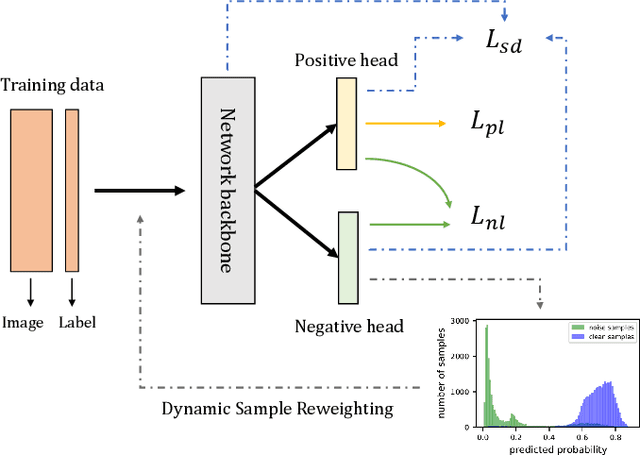

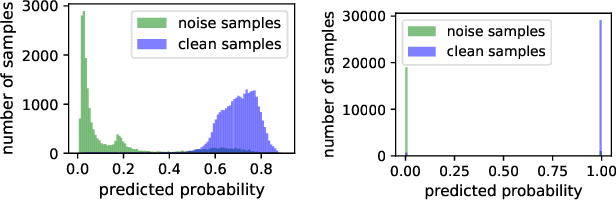
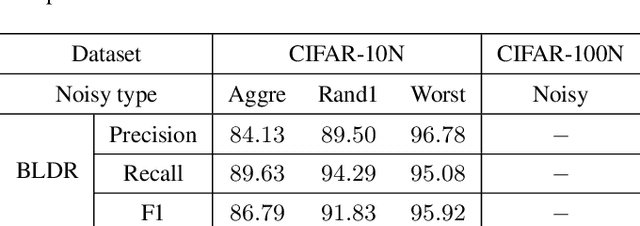
Deep neural networks trained with standard cross-entropy loss are more prone to memorize noisy labels, which degrades their performance. Negative learning using complementary labels is more robust when noisy labels intervene but with an extremely slow model convergence speed. In this paper, we first introduce a bidirectional learning scheme, where positive learning ensures convergence speed while negative learning robustly copes with label noise. Further, a dynamic sample reweighting strategy is proposed to globally weaken the effect of noise-labeled samples by exploiting the excellent discriminatory ability of negative learning on the sample probability distribution. In addition, we combine self-distillation to further improve the model performance. The code is available at \url{https://github.com/chenchenzong/BLDR}.