 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT as a Monte Carlo Language Tree: A Probabilistic Perspective
Jan 13, 2025



Large Language Models (LLMs), such as GPT, are considered to learn the latent distributions within large-scale web-crawl datasets and accomplish natural language processing (NLP) tasks by predicting the next token. However, this mechanism of latent distribution modeling lacks quantitative understanding and analysis. In this paper, we propose a novel perspective that any language dataset can be represented by a Monte Carlo Language Tree (abbreviated as ``Data-Tree''), where each node denotes a token, each edge denotes a token transition probability, and each sequence has a unique path. Any GPT-like language model can also be flattened into another Monte Carlo Language Tree (abbreviated as ``GPT-Tree''). Our experiments show that different GPT models trained on the same dataset exhibit significant structural similarity in GPT-Tree visualization, and larger models converge more closely to the Data-Tree. More than 87\% GPT output tokens can be recalled by Data-Tree. These findings may confirm that the reasoning process of LLMs is more likely to be probabilistic pattern-matching rather than formal reasoning, as each model inference seems to find a context pattern with maximum probability from the Data-Tree. Furthermore, we provide deeper insights into issues such as hallucination, Chain-of-Thought (CoT) reasoning, and token bias in LLMs.
Sparse Orthogonal Parameters Tuning for Continual Learning
Nov 05, 2024



Continual learning methods based on pre-trained models (PTM) have recently gained attention which adapt to successive downstream tasks without catastrophic forgetting. These methods typically refrain from updating the pre-trained parameters and instead employ additional adapters, prompts, and classifiers. In this paper, we from a novel perspective investigate the benefit of sparse orthogonal parameters for continual learning. We found that merging sparse orthogonality of models learned from multiple streaming tasks has great potential in addressing catastrophic forgetting. Leveraging this insight, we propose a novel yet effective method called SoTU (Sparse Orthogonal Parameters TUning). We hypothesize that the effectiveness of SoTU lies in the transformation of knowledge learned from multiple domains into the fusion of orthogonal delta parameters. Experimental evaluations on diverse CL benchmarks demonstrate the effectiveness of the proposed approach. Notably, SoTU achieves optimal feature representation for streaming data without necessitating complex classifier designs, making it a Plug-and-Play solution.
Is Parameter Collision Hindering Continual Learning in LLMs?
Oct 14, 2024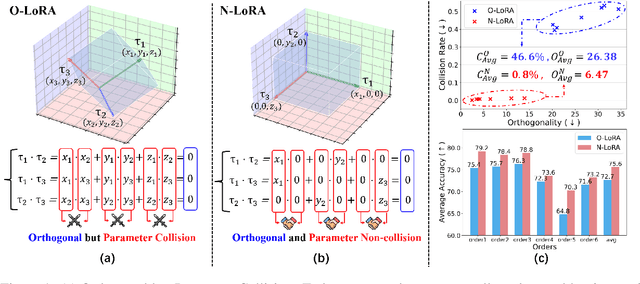
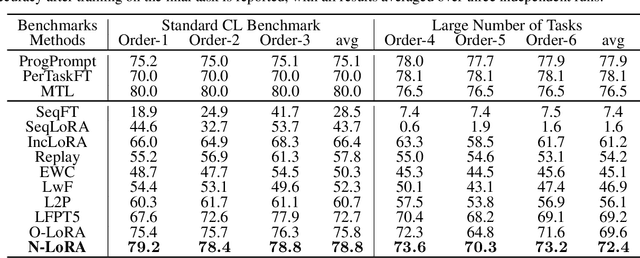
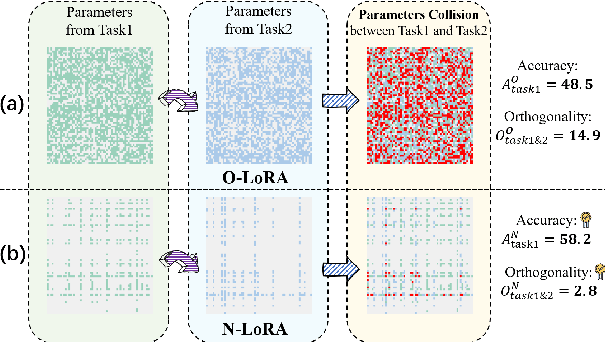

Large Language Models (LLMs) often suffer from catastrophic forgetting when learning multiple tasks sequentially, making continual learning (CL) essential for their dynamic deployment. Existing state-of-the-art (SOTA) methods, such as O-LoRA, typically focus on constructing orthogonality tasks to decouple parameter interdependence from various domains.In this paper, we reveal that building non-collision parameters is a more critical factor in addressing CL challenges. Our theoretical and experimental analyses demonstrate that non-collision parameters can provide better task orthogonality, which is a sufficient but unnecessary condition. Furthermore, knowledge from multiple domains will be preserved in non-collision parameter subspaces, making it more difficult to forget previously seen data. Leveraging this insight, we propose Non-collision Low-Rank Adaptation (N-LoRA), a simple yet effective approach leveraging low collision rates to enhance CL in LLMs. Experimental results on multiple CL benchmarks indicate that N-LoRA achieves superior performance (+2.9), higher task orthogonality (*4.1 times), and lower parameter collision (*58.1 times) than SOTA methods.
Bidirectional Uncertainty-Based Active Learning for Open Set Annotation
Feb 23, 2024Active learning (AL) in open set scenarios presents a novel challenge of identifying the most valuable examples in an unlabeled data pool that comprises data from both known and unknown classes. Traditional methods prioritize selecting informative examples with low confidence, with the risk of mistakenly selecting unknown-class examples with similarly low confidence. Recent methods favor the most probable known-class examples, with the risk of picking simple already mastered examples. In this paper, we attempt to query examples that are both likely from known classes and highly informative, and propose a \textit{Bidirectional Uncertainty-based Active Learning} (BUAL) framework. Specifically, we achieve this by first pushing the unknown class examples toward regions with high-confidence predictions with our proposed \textit{Random Label Negative Learning} method. Then, we propose a \textit{Bidirectional Uncertainty sampling} strategy by jointly estimating uncertainty posed by both positive and negative learning to perform consistent and stable sampling. BUAL successfully extends existing uncertainty-based AL methods to complex open-set scenarios. Extensive experiments on multiple datasets with varying openness demonstrate that BUAL achieves state-of-the-art performance.
Peer-review-in-LLMs: Automatic Evaluation Method for LLMs in Open-environment
Feb 02, 2024



Existing large language models (LLMs) evaluation methods typically focus on testing the performance on some closed-environment and domain-specific benchmarks with human annotations. In this paper, we explore a novel unsupervised evaluation direction, utilizing peer-review mechanisms to measure LLMs automatically. In this setting, both open-source and closed-source LLMs lie in the same environment, capable of answering unlabeled questions and evaluating each other, where each LLM's response score is jointly determined by other anonymous ones. To obtain the ability hierarchy among these models, we assign each LLM a learnable capability parameter to adjust the final ranking. We formalize it as a constrained optimization problem, intending to maximize the consistency of each LLM's capabilities and scores. The key assumption behind is that high-level LLM can evaluate others' answers more accurately than low-level ones, while higher-level LLM can also achieve higher response scores. Moreover, we propose three metrics called PEN, CIN, and LIS to evaluate the gap in aligning human rankings. We perform experiments on multiple datasets with these metrics, validating the effectiveness of the proposed approach.
LLM Lies: Hallucinations are not Bugs, but Features as Adversarial Examples
Oct 04, 2023



Large Language Models (LLMs), including GPT-3.5, LLaMA, and PaLM, seem to be knowledgeable and able to adapt to many tasks. However, we still can not completely trust their answer, since LLMs suffer from hallucination--fabricating non-existent facts to cheat users without perception. And the reasons for their existence and pervasiveness remain unclear. In this paper, we demonstrate that non-sense prompts composed of random tokens can also elicit the LLMs to respond with hallucinations. This phenomenon forces us to revisit that hallucination may be another view of adversarial examples, and it shares similar features with conventional adversarial examples as the basic feature of LLMs. Therefore, we formalize an automatic hallucination triggering method as the hallucination attack in an adversarial way. Finally, we explore basic feature of attacked adversarial prompts and propose a simple yet effective defense strategy. Our code is released on GitHub.
Towards Better Query Classification with Multi-Expert Knowledge Condensation in JD Ads Search
Aug 02, 2023
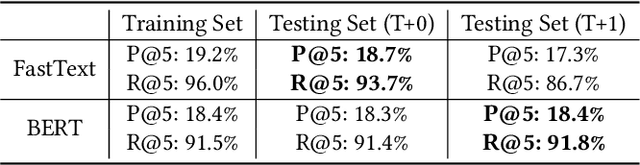
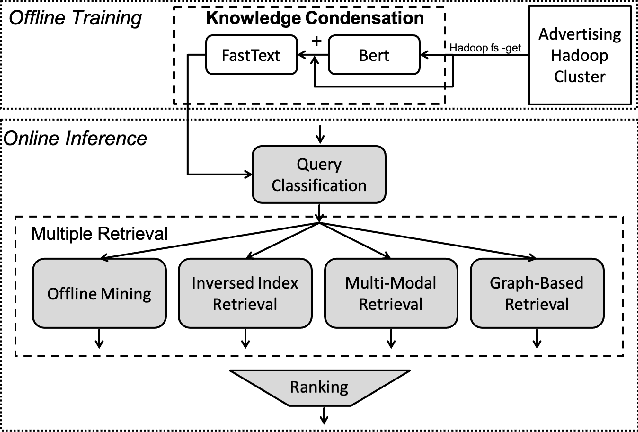

Search query classification, as an effective way to understand user intents, is of great importance in real-world online ads systems. To ensure a lower latency, a shallow model (e.g. FastText) is widely used for efficient online inference. However, the representation ability of the FastText model is insufficient, resulting in poor classification performance, especially on some low-frequency queries and tailed categories. Using a deeper and more complex model (e.g. BERT) is an effective solution, but it will cause a higher online inference latency and more expensive computing costs. Thus, how to juggle both inference efficiency and classification performance is obviously of great practical importance. To overcome this challenge, in this paper, we propose knowledge condensation (KC), a simple yet effective knowledge distillation framework to boost the classification performance of the online FastText model under strict low latency constraints. Specifically, we propose to train an offline BERT model to retrieve more potentially relevant data. Benefiting from its powerful semantic representation, more relevant labels not exposed in the historical data will be added into the training set for better FastText model training. Moreover, a novel distribution-diverse multi-expert learning strategy is proposed to further improve the mining ability of relevant data. By training multiple BERT models from different data distributions, it can respectively perform better at high, middle, and low-frequency search queries. The model ensemble from multi-distribution makes its retrieval ability more powerful. We have deployed two versions of this framework in JD search, and both offline experiments and online A/B testing from multiple datasets have validated the effectiveness of the proposed approach.
Active Learning for Open-set Annotation
Jan 18, 2022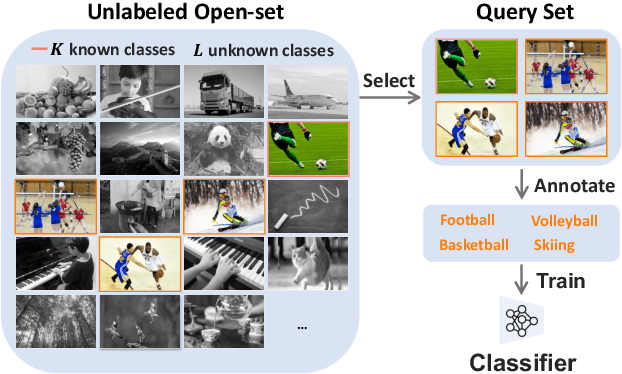
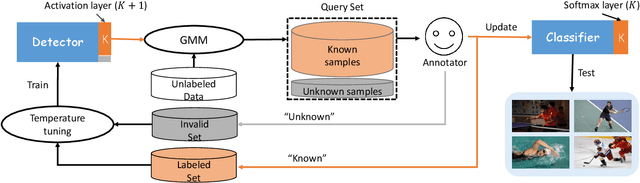
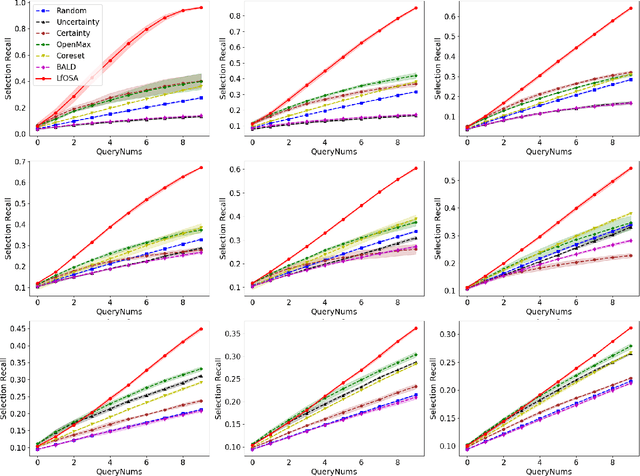
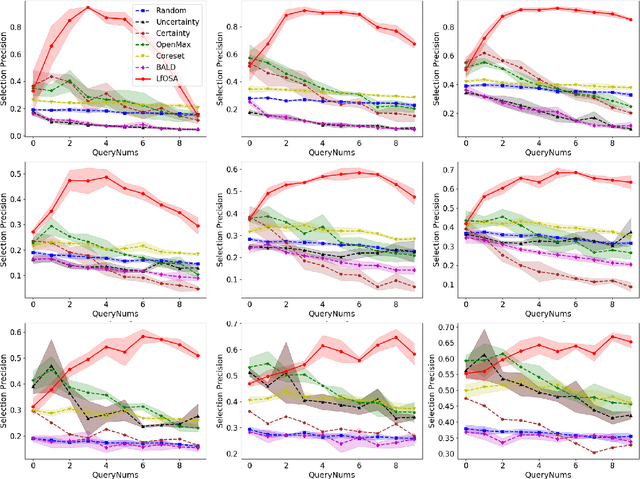
Existing active learning studies typically work in the closed-set setting by assuming that all data examples to be labeled are drawn from known classes. However, in real annotation tasks, the unlabeled data usually contains a large amount of examples from unknown classes, resulting in the failure of most active learning methods. To tackle this open-set annotation (OSA) problem, we propose a new active learning framework called LfOSA, which boosts the classification performance with an effective sampling strategy to precisely detect examples from known classes for annotation. The LfOSA framework introduces an auxiliary network to model the per-example max activation value (MAV) distribution with a Gaussian Mixture Model, which can dynamically select the examples with highest probability from known classes in the unlabeled set. Moreover, by reducing the temperature $T$ of the loss function, the detection model will be further optimized by exploiting both known and unknown supervision. The experimental results show that the proposed method can significantly improve the selection quality of known classes, and achieve higher classification accuracy with lower annotation cost than state-of-the-art active learning methods. To the best of our knowledge, this is the first work of active learning for open-set annotation.
Improving Model Robustness by Adaptively Correcting Perturbation Levels with Active Queries
Mar 27, 2021
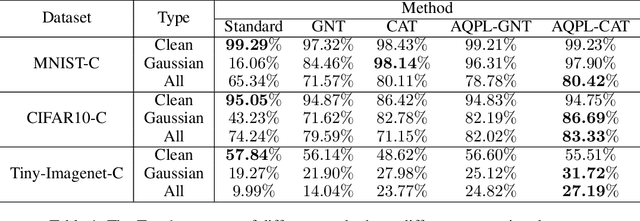
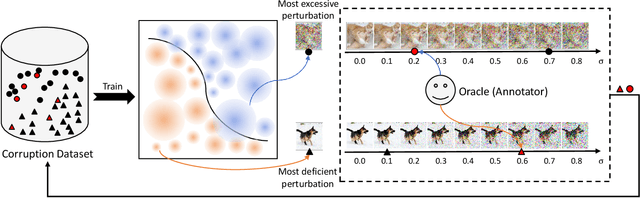
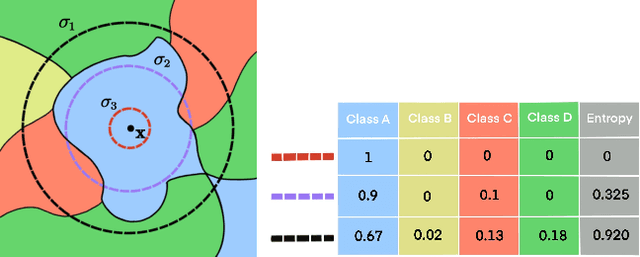
In addition to high accuracy, robustness is becoming increasingly important for machine learning models in various applications. Recently, much research has been devoted to improving the model robustness by training with noise perturbations. Most existing studies assume a fixed perturbation level for all training examples, which however hardly holds in real tasks. In fact, excessive perturbations may destroy the discriminative content of an example, while deficient perturbations may fail to provide helpful information for improving the robustness. Motivated by this observation, we propose to adaptively adjust the perturbation levels for each example in the training process. Specifically, a novel active learning framework is proposed to allow the model to interactively query the correct perturbation level from human experts. By designing a cost-effective sampling strategy along with a new query type, the robustness can be significantly improved with a few queries. Both theoretical analysis and experimental studies validate the effectiveness of the proposed approach.
Co-Imitation Learning without Expert Demonstration
Mar 27, 2021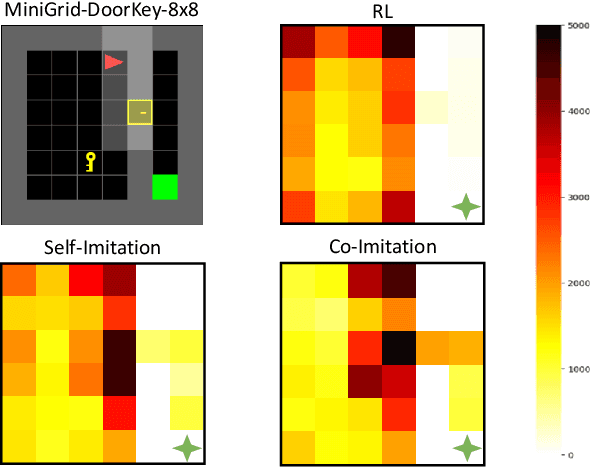
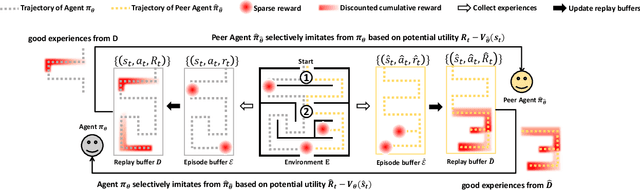
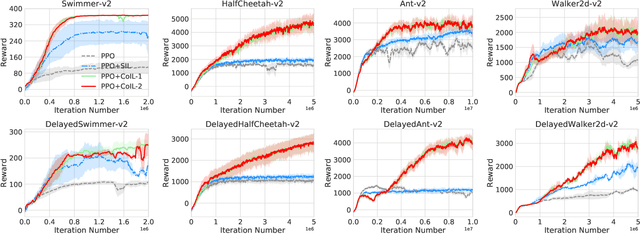

Imitation learning is a primary approach to improve the efficiency of reinforcement learning by exploiting the expert demonstrations. However, in many real scenarios, obtaining expert demonstrations could be extremely expensive or even impossible. To overcome this challenge, in this paper, we propose a novel learning framework called Co-Imitation Learning (CoIL) to exploit the past good experiences of the agents themselves without expert demonstration. Specifically, we train two different agents via letting each of them alternately explore the environment and exploit the peer agent's experience. While the experiences could be valuable or misleading, we propose to estimate the potential utility of each piece of experience with the expected gain of the value function. Thus the agents can selectively imitate from each other by emphasizing the more useful experiences while filtering out noisy ones. Experimental results on various tasks show significant superiority of the proposed Co-Imitation Learning framework, validating that the agents can benefit from each other without external supervision.