 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT as a Monte Carlo Language Tree: A Probabilistic Perspective
Jan 13, 2025Large Language Models (LLMs), such as GPT, are considered to learn the latent distributions within large-scale web-crawl datasets and accomplish natural language processing (NLP) tasks by predicting the next token. However, this mechanism of latent distribution modeling lacks quantitative understanding and analysis. In this paper, we propose a novel perspective that any language dataset can be represented by a Monte Carlo Language Tree (abbreviated as ``Data-Tree''), where each node denotes a token, each edge denotes a token transition probability, and each sequence has a unique path. Any GPT-like language model can also be flattened into another Monte Carlo Language Tree (abbreviated as ``GPT-Tree''). Our experiments show that different GPT models trained on the same dataset exhibit significant structural similarity in GPT-Tree visualization, and larger models converge more closely to the Data-Tree. More than 87\% GPT output tokens can be recalled by Data-Tree. These findings may confirm that the reasoning process of LLMs is more likely to be probabilistic pattern-matching rather than formal reasoning, as each model inference seems to find a context pattern with maximum probability from the Data-Tree. Furthermore, we provide deeper insights into issues such as hallucination, Chain-of-Thought (CoT) reasoning, and token bias in LLMs.
Sparse Orthogonal Parameters Tuning for Continual Learning
Nov 05, 2024



Continual learning methods based on pre-trained models (PTM) have recently gained attention which adapt to successive downstream tasks without catastrophic forgetting. These methods typically refrain from updating the pre-trained parameters and instead employ additional adapters, prompts, and classifiers. In this paper, we from a novel perspective investigate the benefit of sparse orthogonal parameters for continual learning. We found that merging sparse orthogonality of models learned from multiple streaming tasks has great potential in addressing catastrophic forgetting. Leveraging this insight, we propose a novel yet effective method called SoTU (Sparse Orthogonal Parameters TUning). We hypothesize that the effectiveness of SoTU lies in the transformation of knowledge learned from multiple domains into the fusion of orthogonal delta parameters. Experimental evaluations on diverse CL benchmarks demonstrate the effectiveness of the proposed approach. Notably, SoTU achieves optimal feature representation for streaming data without necessitating complex classifier designs, making it a Plug-and-Play solution.
Is Parameter Collision Hindering Continual Learning in LLMs?
Oct 14, 2024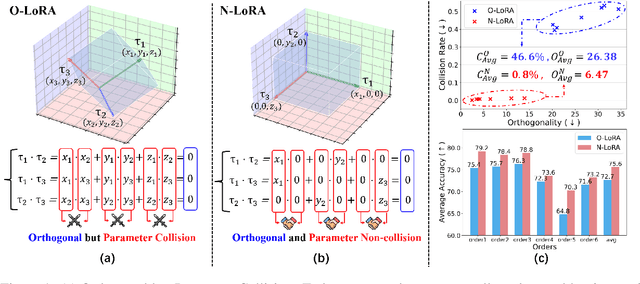
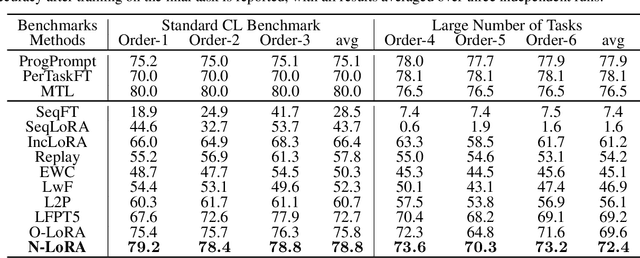
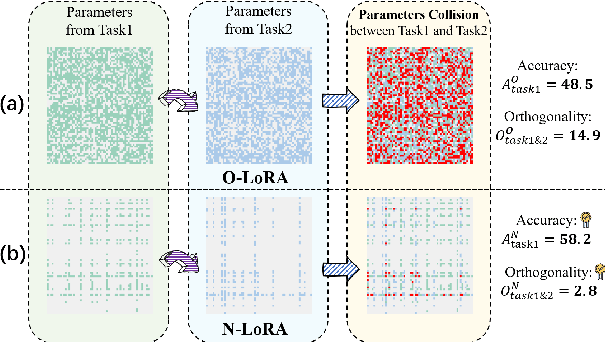

Large Language Models (LLMs) often suffer from catastrophic forgetting when learning multiple tasks sequentially, making continual learning (CL) essential for their dynamic deployment. Existing state-of-the-art (SOTA) methods, such as O-LoRA, typically focus on constructing orthogonality tasks to decouple parameter interdependence from various domains.In this paper, we reveal that building non-collision parameters is a more critical factor in addressing CL challenges. Our theoretical and experimental analyses demonstrate that non-collision parameters can provide better task orthogonality, which is a sufficient but unnecessary condition. Furthermore, knowledge from multiple domains will be preserved in non-collision parameter subspaces, making it more difficult to forget previously seen data. Leveraging this insight, we propose Non-collision Low-Rank Adaptation (N-LoRA), a simple yet effective approach leveraging low collision rates to enhance CL in LLMs. Experimental results on multiple CL benchmarks indicate that N-LoRA achieves superior performance (+2.9), higher task orthogonality (*4.1 times), and lower parameter collision (*58.1 times) than SOTA methods.
Peer-review-in-LLMs: Automatic Evaluation Method for LLMs in Open-environment
Feb 02, 2024



Existing large language models (LLMs) evaluation methods typically focus on testing the performance on some closed-environment and domain-specific benchmarks with human annotations. In this paper, we explore a novel unsupervised evaluation direction, utilizing peer-review mechanisms to measure LLMs automatically. In this setting, both open-source and closed-source LLMs lie in the same environment, capable of answering unlabeled questions and evaluating each other, where each LLM's response score is jointly determined by other anonymous ones. To obtain the ability hierarchy among these models, we assign each LLM a learnable capability parameter to adjust the final ranking. We formalize it as a constrained optimization problem, intending to maximize the consistency of each LLM's capabilities and scores. The key assumption behind is that high-level LLM can evaluate others' answers more accurately than low-level ones, while higher-level LLM can also achieve higher response scores. Moreover, we propose three metrics called PEN, CIN, and LIS to evaluate the gap in aligning human rankings. We perform experiments on multiple datasets with these metrics, validating the effectiveness of the proposed approach.
LLM Lies: Hallucinations are not Bugs, but Features as Adversarial Examples
Oct 04, 2023Large Language Models (LLMs), including GPT-3.5, LLaMA, and PaLM, seem to be knowledgeable and able to adapt to many tasks. However, we still can not completely trust their answer, since LLMs suffer from hallucination--fabricating non-existent facts to cheat users without perception. And the reasons for their existence and pervasiveness remain unclear. In this paper, we demonstrate that non-sense prompts composed of random tokens can also elicit the LLMs to respond with hallucinations. This phenomenon forces us to revisit that hallucination may be another view of adversarial examples, and it shares similar features with conventional adversarial examples as the basic feature of LLMs. Therefore, we formalize an automatic hallucination triggering method as the hallucination attack in an adversarial way. Finally, we explore basic feature of attacked adversarial prompts and propose a simple yet effective defense strategy. Our code is released on GitHub.