 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-objective Aligned Bidword Generation Model for E-commerce Search Advertising
Jun 04, 2025

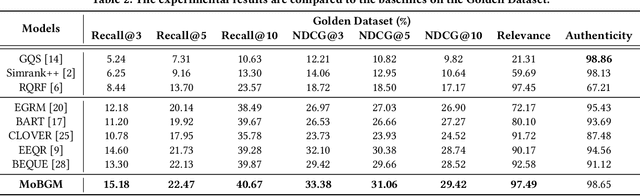

Retrieval systems primarily address the challenge of matching user queries with the most relevant advertisements, playing a crucial role in e-commerce search advertising. The diversity of user needs and expressions often produces massive long-tail queries that cannot be matched with merchant bidwords or product titles, which results in some advertisements not being recalled, ultimately harming user experience and search efficiency. Existing query rewriting research focuses on various methods such as query log mining, query-bidword vector matching, or generation-based rewriting. However, these methods often fail to simultaneously optimize the relevance and authenticity of the user's original query and rewrite and maximize the revenue potential of recalled ads. In this paper, we propose a Multi-objective aligned Bidword Generation Model (MoBGM), which is composed of a discriminator, generator, and preference alignment module, to address these challenges. To simultaneously improve the relevance and authenticity of the query and rewrite and maximize the platform revenue, we design a discriminator to optimize these key objectives. Using the feedback signal of the discriminator, we train a multi-objective aligned bidword generator that aims to maximize the combined effect of the three objectives. Extensive offline and online experiments show that our proposed algorithm significantly outperforms the state of the art. After deployment, the algorithm has created huge commercial value for the platform, further verifying its feasibility and robustness.
Generative Retrieval and Alignment Model: A New Paradigm for E-commerce Retrieval
Apr 02, 2025Traditional sparse and dense retrieval methods struggle to leverage general world knowledge and often fail to capture the nuanced features of queries and products. With the advent of large language models (LLMs), industrial search systems have started to employ LLMs to generate identifiers for product retrieval. Commonly used identifiers include (1) static/semantic IDs and (2) product term sets. The first approach requires creating a product ID system from scratch, missing out on the world knowledge embedded within LLMs. While the second approach leverages this general knowledge, the significant difference in word distribution between queries and products means that product-based identifiers often do not align well with user search queries, leading to missed product recalls. Furthermore, when queries contain numerous attributes, these algorithms generate a large number of identifiers, making it difficult to assess their quality, which results in low overall recall efficiency. To address these challenges, this paper introduces a novel e-commerce retrieval paradigm: the Generative Retrieval and Alignment Model (GRAM). GRAM employs joint training on text information from both queries and products to generate shared text identifier codes, effectively bridging the gap between queries and products. This approach not only enhances the connection between queries and products but also improves inference efficiency. The model uses a co-alignment strategy to generate codes optimized for maximizing retrieval efficiency. Additionally, it introduces a query-product scoring mechanism to compare product values across different codes, further boosting retrieval efficiency. Extensive offline and online A/B testing demonstrates that GRAM significantly outperforms traditional models and the latest generative retrieval models, confirming its effectiveness and practicality.
A Semi-supervised Multi-channel Graph Convolutional Network for Query Classification in E-commerce
Aug 04, 2024


Query intent classification is an essential module for customers to find desired products on the e-commerce application quickly. Most existing query intent classification methods rely on the users' click behavior as a supervised signal to construct training samples. However, these methods based entirely on posterior labels may lead to serious category imbalance problems because of the Matthew effect in click samples. Compared with popular categories, it is difficult for products under long-tail categories to obtain traffic and user clicks, which makes the models unable to detect users' intent for products under long-tail categories. This in turn aggravates the problem that long-tail categories cannot obtain traffic, forming a vicious circle. In addition, due to the randomness of the user's click, the posterior label is unstable for the query with similar semantics, which makes the model very sensitive to the input, leading to an unstable and incomplete recall of categories. In this paper, we propose a novel Semi-supervised Multi-channel Graph Convolutional Network (SMGCN) to address the above problems from the perspective of label association and semi-supervised learning. SMGCN extends category information and enhances the posterior label by utilizing the similarity score between the query and categories. Furthermore, it leverages the co-occurrence and semantic similarity graph of categories to strengthen the relations among labels and weaken the influence of posterior label instability. We conduct extensive offline and online A/B experiments, and the experimental results show that SMGCN significantly outperforms the strong baselines, which shows its effectiveness and practicality.
Peer-review-in-LLMs: Automatic Evaluation Method for LLMs in Open-environment
Feb 02, 2024



Existing large language models (LLMs) evaluation methods typically focus on testing the performance on some closed-environment and domain-specific benchmarks with human annotations. In this paper, we explore a novel unsupervised evaluation direction, utilizing peer-review mechanisms to measure LLMs automatically. In this setting, both open-source and closed-source LLMs lie in the same environment, capable of answering unlabeled questions and evaluating each other, where each LLM's response score is jointly determined by other anonymous ones. To obtain the ability hierarchy among these models, we assign each LLM a learnable capability parameter to adjust the final ranking. We formalize it as a constrained optimization problem, intending to maximize the consistency of each LLM's capabilities and scores. The key assumption behind is that high-level LLM can evaluate others' answers more accurately than low-level ones, while higher-level LLM can also achieve higher response scores. Moreover, we propose three metrics called PEN, CIN, and LIS to evaluate the gap in aligning human rankings. We perform experiments on multiple datasets with these metrics, validating the effectiveness of the proposed approach.
Towards Better Query Classification with Multi-Expert Knowledge Condensation in JD Ads Search
Aug 02, 2023Search query classification, as an effective way to understand user intents, is of great importance in real-world online ads systems. To ensure a lower latency, a shallow model (e.g. FastText) is widely used for efficient online inference. However, the representation ability of the FastText model is insufficient, resulting in poor classification performance, especially on some low-frequency queries and tailed categories. Using a deeper and more complex model (e.g. BERT) is an effective solution, but it will cause a higher online inference latency and more expensive computing costs. Thus, how to juggle both inference efficiency and classification performance is obviously of great practical importance. To overcome this challenge, in this paper, we propose knowledge condensation (KC), a simple yet effective knowledge distillation framework to boost the classification performance of the online FastText model under strict low latency constraints. Specifically, we propose to train an offline BERT model to retrieve more potentially relevant data. Benefiting from its powerful semantic representation, more relevant labels not exposed in the historical data will be added into the training set for better FastText model training. Moreover, a novel distribution-diverse multi-expert learning strategy is proposed to further improve the mining ability of relevant data. By training multiple BERT models from different data distributions, it can respectively perform better at high, middle, and low-frequency search queries. The model ensemble from multi-distribution makes its retrieval ability more powerful. We have deployed two versions of this framework in JD search, and both offline experiments and online A/B testing from multiple datasets have validated the effectiveness of the proposed approach.
Data Provenance via Differential Auditing
Sep 04, 2022



Auditing Data Provenance (ADP), i.e., auditing if a certain piece of data has been used to train a machine learning model, is an important problem in data provenance. The feasibility of the task has been demonstrated by existing auditing techniques, e.g., shadow auditing methods, under certain conditions such as the availability of label information and the knowledge of training protocols for the target model. Unfortunately, both of these conditions are often unavailable in real applications. In this paper, we introduce Data Provenance via Differential Auditing (DPDA), a practical framework for auditing data provenance with a different approach based on statistically significant differentials, i.e., after carefully designed transformation, perturbed input data from the target model's training set would result in much more drastic changes in the output than those from the model's non-training set. This framework allows auditors to distinguish training data from non-training ones without the need of training any shadow models with the help of labeled output data. Furthermore, we propose two effective auditing function implementations, an additive one and a multiplicative one. We report evaluations on real-world data sets demonstrating the effectiveness of our proposed auditing technique.
Unorganized Malicious Attacks Detection
Feb 18, 2018
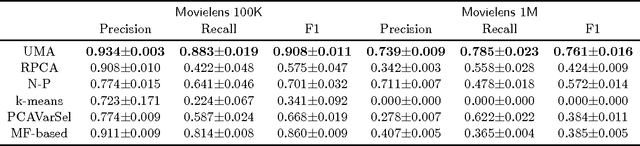
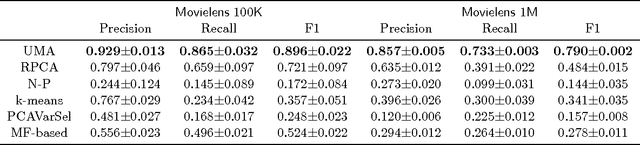

Recommender system has attracted much attention during the past decade. Many attack detection algorithms have been developed for better recommendations, mostly focusing on shilling attacks, where an attack organizer produces a large number of user profiles by the same strategy to promote or demote an item. This work considers a different attack style: unorganized malicious attacks, where attackers individually utilize a small number of user profiles to attack different items without any organizer. This attack style occurs in many real applications, yet relevant study remains open. We first formulate the unorganized malicious attacks detection as a matrix completion problem, and propose the Unorganized Malicious Attacks detection (UMA) approach, a proximal alternating splitting augmented Lagrangian method. We verify, both theoretically and empirically, the effectiveness of our proposed approach.