 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Routing and Model Pruning for Decentralized Federated Learning in Bandwidth-Constrained Multi-Hop Wireless Networks
Mar 16, 2026Decentralized federated learning (D-FL) enables privacy-preserving training without a central server, but multi-hop model exchanges and aggregation are often bottlenecked by communication resource constraints. To address this issue, we propose a joint routing-and-pruning framework that optimizes routing paths and pruning rates to maintain communication latency within prescribed limits. We analyze how the sum of model biases across all clients affects the convergence bound of D-FL and formulate an optimization problem that maximizes the model retention rate to minimize these biases under communication constraints. Further analysis reveals that each client's model retention rate is path-dependent, which reduces the original problem to a routing optimization. Leveraging this insight, we develop a routing algorithm that selects latency-efficient transmission paths, allowing more parameters to be delivered within the time budget and thereby improving D-FL convergence. Simulations demonstrate that, compared with unpruned systems, the proposed framework reduces average transmission latency by 27.8% and improves testing accuracy by approximately 12%. Furthermore, relative to standard benchmark routing algorithms, the proposed routing method improves accuracy by roughly 8%.
Projection-Free Evolution Strategies for Continuous Prompt Search
Mar 14, 2026Continuous prompt search offers a computationally efficient alternative to conventional parameter tuning in natural language processing tasks. Nevertheless, its practical effectiveness can be significantly hindered by the black-box nature and the inherent high-dimensionality of the objective landscapes. Existing methods typically mitigate these challenges by restricting the search to a randomly projected low-dimensional subspace. However, the effectiveness and underlying motivation of the projection mechanism remain ambiguous. In this paper, we first empirically demonstrate that despite the prompt space possessing a low-dimensional structure, random projections fail to adequately capture this essential structure. Motivated by this finding, we propose a projection-free prompt search method based on evolutionary strategies. By directly optimizing in the full prompt space with an adaptation mechanism calibrated to the intrinsic dimension, our method achieves competitive search capabilities without additional computational overhead. Furthermore, to bridge the generalization gap in few-shot scenarios, we introduce a confidence-based regularization mechanism that systematically enhances the model's confidence in the target verbalizers. Experimental results on seven natural language understanding tasks from the GLUE benchmark demonstrate that our proposed approach significantly outperforms existing baselines.
NECromancer: Breathing Life into Skeletons via BVH Animation
Feb 06, 2026Motion tokenization is a key component of generalizable motion models, yet most existing approaches are restricted to species-specific skeletons, limiting their applicability across diverse morphologies. We propose NECromancer (NEC), a universal motion tokenizer that operates directly on arbitrary BVH skeletons. NEC consists of three components: (1) an Ontology-aware Skeletal Graph Encoder (OwO) that encodes structural priors from BVH files, including joint semantics, rest-pose offsets, and skeletal topology, into skeletal embeddings; (2) a Topology-Agnostic Tokenizer (TAT) that compresses motion sequences into a universal, topology-invariant discrete representation; and (3) the Unified BVH Universe (UvU), a large-scale dataset aggregating BVH motions across heterogeneous skeletons. Experiments show that NEC achieves high-fidelity reconstruction under substantial compression and effectively disentangles motion from skeletal structure. The resulting token space supports cross-species motion transfer, composition, denoising, generation with token-based models, and text-motion retrieval, establishing a unified framework for motion analysis and synthesis across diverse morphologies. Demo page: https://animotionlab.github.io/NECromancer/
DiMo: Discrete Diffusion Modeling for Motion Generation and Understanding
Feb 04, 2026Prior masked modeling motion generation methods predominantly study text-to-motion. We present DiMo, a discrete diffusion-style framework, which extends masked modeling to bidirectional text--motion understanding and generation. Unlike GPT-style autoregressive approaches that tokenize motion and decode sequentially, DiMo performs iterative masked token refinement, unifying Text-to-Motion (T2M), Motion-to-Text (M2T), and text-free Motion-to-Motion (M2M) within a single model. This decoding paradigm naturally enables a quality-latency trade-off at inference via the number of refinement steps.We further improve motion token fidelity with residual vector quantization (RVQ) and enhance alignment and controllability with Group Relative Policy Optimization (GRPO). Experiments on HumanML3D and KIT-ML show strong motion quality and competitive bidirectional understanding under a unified framework. In addition, we demonstrate model ability in text-free motion completion, text-guided motion prediction and motion caption correction without architectural change.Additional qualitative results are available on our project page: https://animotionlab.github.io/DiMo/.
A Provable Expressiveness Hierarchy in Hybrid Linear-Full Attention
Feb 02, 2026Transformers serve as the foundation of most modern large language models. To mitigate the quadratic complexity of standard full attention, various efficient attention mechanisms, such as linear and hybrid attention, have been developed. A fundamental gap remains: their expressive power relative to full attention lacks a rigorous theoretical characterization. In this work, we theoretically characterize the performance differences among these attention mechanisms. Our theory applies to all linear attention variants that can be formulated as a recurrence, including Mamba, DeltaNet, etc. Specifically, we establish an expressiveness hierarchy: for the sequential function composition-a multi-step reasoning task that must occur within a model's forward pass, an ($L+1$)-layer full attention network is sufficient, whereas any hybrid network interleaving $L-1$ layers of full attention with a substantially larger number ($2^{3L^2}$) of linear attention layers cannot solve it. This result demonstrates a clear separation in expressive power between the two types of attention. Our work provides the first provable separation between hybrid attention and standard full attention, offering a theoretical perspective for understanding the fundamental capabilities and limitations of different attention mechanisms.
BAPS: A Fine-Grained Low-Precision Scheme for Softmax in Attention via Block-Aware Precision reScaling
Feb 02, 2026As the performance gains from accelerating quantized matrix multiplication plateau, the softmax operation becomes the critical bottleneck in Transformer inference. This bottleneck stems from two hardware limitations: (1) limited data bandwidth between matrix and vector compute cores, and (2) the significant area cost of high-precision (FP32/16) exponentiation units (EXP2). To address these issues, we introduce a novel low-precision workflow that employs a specific 8-bit floating-point format (HiF8) and block-aware precision rescaling for softmax. Crucially, our algorithmic innovations make low-precision softmax feasible without the significant model accuracy loss that hampers direct low-precision approaches. Specifically, our design (i) halves the required data movement bandwidth by enabling matrix multiplication outputs constrained to 8-bit, and (ii) substantially reduces the EXP2 unit area by computing exponentiations in low (8-bit) precision. Extensive evaluation on language models and multi-modal models confirms the validity of our method. By alleviating the vector computation bottleneck, our work paves the way for doubling end-to-end inference throughput without increasing chip area, and offers a concrete co-design path for future low-precision hardware and software.
Alada: Alternating Adaptation of Momentum Method for Memory-Efficient Matrix Optimization
Dec 15, 2025This work proposes Alada, an adaptive momentum method for stochastic optimization over large-scale matrices. Alada employs a rank-one factorization approach to estimate the second moment of gradients, where factors are updated alternatively to minimize the estimation error. Alada achieves sublinear memory overheads and can be readily extended to optimizing tensor-shaped variables.We also equip Alada with a first moment estimation rule, which enhances the algorithm's robustness without incurring additional memory overheads. The theoretical performance of Alada aligns with that of traditional methods such as Adam. Numerical studies conducted on several natural language processing tasks demonstrate the reduction in memory overheads and the robustness in training large models relative to Adam and its variants.
MoCapAnything: Unified 3D Motion Capture for Arbitrary Skeletons from Monocular Videos
Dec 11, 2025Motion capture now underpins content creation far beyond digital humans, yet most existing pipelines remain species- or template-specific. We formalize this gap as Category-Agnostic Motion Capture (CAMoCap): given a monocular video and an arbitrary rigged 3D asset as a prompt, the goal is to reconstruct a rotation-based animation such as BVH that directly drives the specific asset. We present MoCapAnything, a reference-guided, factorized framework that first predicts 3D joint trajectories and then recovers asset-specific rotations via constraint-aware inverse kinematics. The system contains three learnable modules and a lightweight IK stage: (1) a Reference Prompt Encoder that extracts per-joint queries from the asset's skeleton, mesh, and rendered images; (2) a Video Feature Extractor that computes dense visual descriptors and reconstructs a coarse 4D deforming mesh to bridge the gap between video and joint space; and (3) a Unified Motion Decoder that fuses these cues to produce temporally coherent trajectories. We also curate Truebones Zoo with 1038 motion clips, each providing a standardized skeleton-mesh-render triad. Experiments on both in-domain benchmarks and in-the-wild videos show that MoCapAnything delivers high-quality skeletal animations and exhibits meaningful cross-species retargeting across heterogeneous rigs, enabling scalable, prompt-driven 3D motion capture for arbitrary assets. Project page: https://animotionlab.github.io/MoCapAnything/
SWiT-4D: Sliding-Window Transformer for Lossless and Parameter-Free Temporal 4D Generation
Dec 11, 2025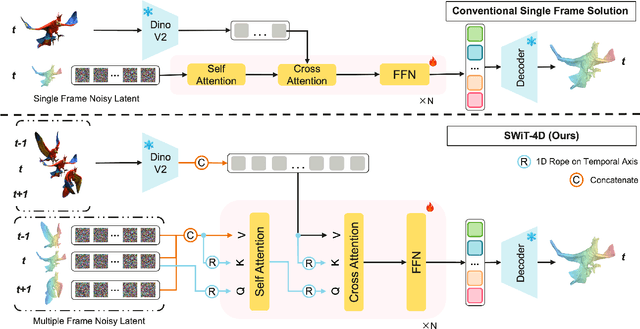
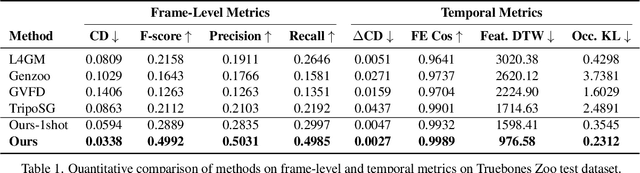
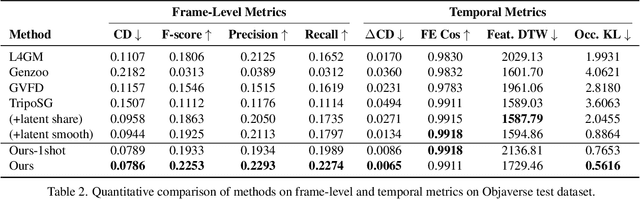

Despite significant progress in 4D content generation, the conversion of monocular videos into high-quality animated 3D assets with explicit 4D meshes remains considerably challenging. The scarcity of large-scale, naturally captured 4D mesh datasets further limits the ability to train generalizable video-to-4D models from scratch in a purely data-driven manner. Meanwhile, advances in image-to-3D generation, supported by extensive datasets, offer powerful prior models that can be leveraged. To better utilize these priors while minimizing reliance on 4D supervision, we introduce SWiT-4D, a Sliding-Window Transformer for lossless, parameter-free temporal 4D mesh generation. SWiT-4D integrates seamlessly with any Diffusion Transformer (DiT)-based image-to-3D generator, adding spatial-temporal modeling across video frames while preserving the original single-image forward process, enabling 4D mesh reconstruction from videos of arbitrary length. To recover global translation, we further introduce an optimization-based trajectory module tailored for static-camera monocular videos. SWiT-4D demonstrates strong data efficiency: with only a single short (<10s) video for fine-tuning, it achieves high-fidelity geometry and stable temporal consistency, indicating practical deployability under extremely limited 4D supervision. Comprehensive experiments on both in-domain zoo-test sets and challenging out-of-domain benchmarks (C4D, Objaverse, and in-the-wild videos) show that SWiT-4D consistently outperforms existing baselines in temporal smoothness. Project page: https://animotionlab.github.io/SWIT4D/
Generative Retrieval and Alignment Model: A New Paradigm for E-commerce Retrieval
Apr 02, 2025Traditional sparse and dense retrieval methods struggle to leverage general world knowledge and often fail to capture the nuanced features of queries and products. With the advent of large language models (LLMs), industrial search systems have started to employ LLMs to generate identifiers for product retrieval. Commonly used identifiers include (1) static/semantic IDs and (2) product term sets. The first approach requires creating a product ID system from scratch, missing out on the world knowledge embedded within LLMs. While the second approach leverages this general knowledge, the significant difference in word distribution between queries and products means that product-based identifiers often do not align well with user search queries, leading to missed product recalls. Furthermore, when queries contain numerous attributes, these algorithms generate a large number of identifiers, making it difficult to assess their quality, which results in low overall recall efficiency. To address these challenges, this paper introduces a novel e-commerce retrieval paradigm: the Generative Retrieval and Alignment Model (GRAM). GRAM employs joint training on text information from both queries and products to generate shared text identifier codes, effectively bridging the gap between queries and products. This approach not only enhances the connection between queries and products but also improves inference efficiency. The model uses a co-alignment strategy to generate codes optimized for maximizing retrieval efficiency. Additionally, it introduces a query-product scoring mechanism to compare product values across different codes, further boosting retrieval efficiency. Extensive offline and online A/B testing demonstrates that GRAM significantly outperforms traditional models and the latest generative retrieval models, confirming its effectiveness and practicality.