 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent Diffusion: Denoising Diffusion Model with Data-Consistent Training for Image Restoration
Dec 17, 2024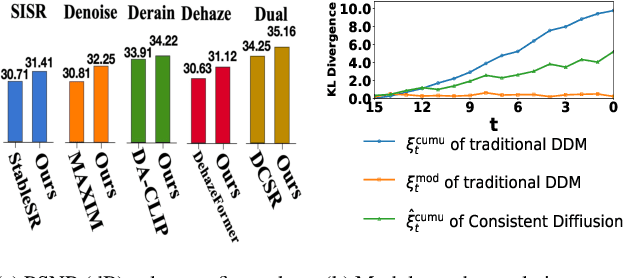
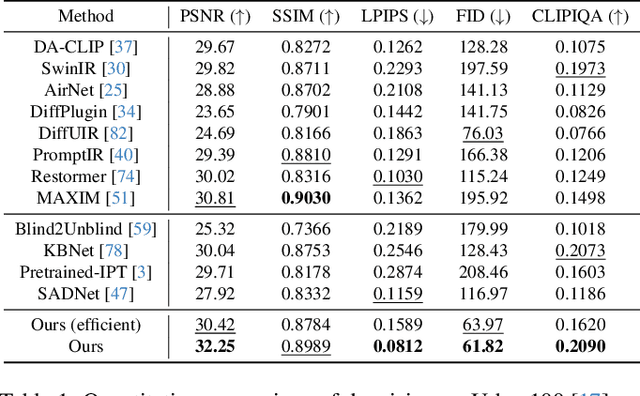


In this work, we address the limitations of denoising diffusion models (DDMs) in image restoration tasks, particularly the shape and color distortions that can compromise image quality. While DDMs have demonstrated a promising performance in many applications such as text-to-image synthesis, their effectiveness in image restoration is often hindered by shape and color distortions. We observe that these issues arise from inconsistencies between the training and testing data used by DDMs. Based on our observation, we propose a novel training method, named data-consistent training, which allows the DDMs to access images with accumulated errors during training, thereby ensuring the model to learn to correct these errors. Experimental results show that, across five image restoration tasks, our method has significant improvements over state-of-the-art methods while effectively minimizing distortions and preserving image fidelity.
Open 3D World in Autonomous Driving
Aug 20, 2024The capability for open vocabulary perception represents a significant advancement in autonomous driving systems, facilitating the comprehension and interpretation of a wide array of textual inputs in real-time. Despite extensive research in open vocabulary tasks within 2D computer vision, the application of such methodologies to 3D environments, particularly within large-scale outdoor contexts, remains relatively underdeveloped. This paper presents a novel approach that integrates 3D point cloud data, acquired from LIDAR sensors, with textual information. The primary focus is on the utilization of textual data to directly localize and identify objects within the autonomous driving context. We introduce an efficient framework for the fusion of bird's-eye view (BEV) region features with textual features, thereby enabling the system to seamlessly adapt to novel textual inputs and enhancing the robustness of open vocabulary detection tasks. The effectiveness of the proposed methodology is rigorously evaluated through extensive experimentation on the newly introduced NuScenes-T dataset, with additional validation of its zero-shot performance on the Lyft Level 5 dataset. This research makes a substantive contribution to the advancement of autonomous driving technologies by leveraging multimodal data to enhance open vocabulary perception in 3D environments, thereby pushing the boundaries of what is achievable in autonomous navigation and perception.