 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpiBench: Benchmarking Multi-turn Research Workflows for Multimodal Agents
Apr 07, 2026Scientific research follows multi-turn, multi-step workflows that require proactively searching the literature, consulting figures and tables, and integrating evidence across papers to align experimental settings and support reproducible conclusions. This joint capability is not systematically assessed in existing benchmarks, which largely under-evaluate proactive search, multi-evidence integration and sustained evidence use over time. In this work, we introduce EpiBench, an episodic multi-turn multimodal benchmark that instantiates short research workflows. Given a research task, agents must navigate across papers over multiple turns, align evidence from figures and tables, and use the accumulated evidence in the memory to answer objective questions that require cross paper comparisons and multi-figure integration. EpiBench introduces a process-level evaluation framework for fine-grained testing and diagnosis of research agents. Our experiments show that even the leading model achieves an accuracy of only 29.23% on the hard split, indicating substantial room for improvement in multi-turn, multi-evidence research workflows, providing an evaluation platform for verifiable and reproducible research agents.
MiroFlow: Towards High-Performance and Robust Open-Source Agent Framework for General Deep Research Tasks
Feb 26, 2026Despite the remarkable progress of large language models (LLMs), the capabilities of standalone LLMs have begun to plateau when tackling real-world, complex tasks that require interaction with external tools and dynamic environments. Although recent agent frameworks aim to enhance model autonomy through tool integration and external interaction, they still suffer from naive workflows, unstable performance, limited support across diverse benchmarks and tasks, and heavy reliance on costly commercial APIs. In this work, we propose a high-performance and robust open-source agent framework, termed MiroFlow, which incorporates an agent graph for flexible orchestration, an optional deep reasoning mode to enhance performance, and a robust workflow execution to ensure stable and reproducible performance. Extensive experiments demonstrate that MiroFlow consistently achieves state-of-the-art performance across multiple agent benchmarks, including GAIA, BrowseComp-EN/ZH, HLE, xBench-DeepSearch, and notably FutureX. We hope it could serve as an easily accessible, reproducible, and comparable baseline for the deep research community.
MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
Nov 18, 2025We present MiroThinker v1.0, an open-source research agent designed to advance tool-augmented reasoning and information-seeking capabilities. Unlike previous agents that only scale up model size or context length, MiroThinker explores interaction scaling at the model level, systematically training the model to handle deeper and more frequent agent-environment interactions as a third dimension of performance improvement. Unlike LLM test-time scaling, which operates in isolation and risks degradation with longer reasoning chains, interactive scaling leverages environment feedback and external information acquisition to correct errors and refine trajectories. Through reinforcement learning, the model achieves efficient interaction scaling: with a 256K context window, it can perform up to 600 tool calls per task, enabling sustained multi-turn reasoning and complex real-world research workflows. Across four representative benchmarks-GAIA, HLE, BrowseComp, and BrowseComp-ZH-the 72B variant achieves up to 81.9%, 37.7%, 47.1%, and 55.6% accuracy respectively, surpassing previous open-source agents and approaching commercial counterparts such as GPT-5-high. Our analysis reveals that MiroThinker benefits from interactive scaling consistently: research performance improves predictably as the model engages in deeper and more frequent agent-environment interactions, demonstrating that interaction depth exhibits scaling behaviors analogous to model size and context length. These findings establish interaction scaling as a third critical dimension for building next-generation open research agents, complementing model capacity and context windows.
ZeroGUI: Automating Online GUI Learning at Zero Human Cost
May 29, 2025



The rapid advancement of large Vision-Language Models (VLMs) has propelled the development of pure-vision-based GUI Agents, capable of perceiving and operating Graphical User Interfaces (GUI) to autonomously fulfill user instructions. However, existing approaches usually adopt an offline learning framework, which faces two core limitations: (1) heavy reliance on high-quality manual annotations for element grounding and action supervision, and (2) limited adaptability to dynamic and interactive environments. To address these limitations, we propose ZeroGUI, a scalable, online learning framework for automating GUI Agent training at Zero human cost. Specifically, ZeroGUI integrates (i) VLM-based automatic task generation to produce diverse training goals from the current environment state, (ii) VLM-based automatic reward estimation to assess task success without hand-crafted evaluation functions, and (iii) two-stage online reinforcement learning to continuously interact with and learn from GUI environments. Experiments on two advanced GUI Agents (UI-TARS and Aguvis) demonstrate that ZeroGUI significantly boosts performance across OSWorld and AndroidLab environments. The code is available at https://github.com/OpenGVLab/ZeroGUI.
Investigating and Enhancing the Robustness of Large Multimodal Models Against Temporal Inconsistency
May 20, 2025Large Multimodal Models (LMMs) have recently demonstrated impressive performance on general video comprehension benchmarks. Nevertheless, for broader applications, the robustness of their temporal analysis capability needs to be thoroughly investigated yet predominantly ignored. Motivated by this, we propose a novel temporal robustness benchmark (TemRobBench), which introduces temporal inconsistency perturbations separately at the visual and textual modalities to assess the robustness of models. We evaluate 16 mainstream LMMs and find that they exhibit over-reliance on prior knowledge and textual context in adversarial environments, while ignoring the actual temporal dynamics in the video. To mitigate this issue, we design panoramic direct preference optimization (PanoDPO), which encourages LMMs to incorporate both visual and linguistic feature preferences simultaneously. Experimental results show that PanoDPO can effectively enhance the model's robustness and reliability in temporal analysis.
Multi-Grained Compositional Visual Clue Learning for Image Intent Recognition
Apr 25, 2025



In an era where social media platforms abound, individuals frequently share images that offer insights into their intents and interests, impacting individual life quality and societal stability. Traditional computer vision tasks, such as object detection and semantic segmentation, focus on concrete visual representations, while intent recognition relies more on implicit visual clues. This poses challenges due to the wide variation and subjectivity of such clues, compounded by the problem of intra-class variety in conveying abstract concepts, e.g. "enjoy life". Existing methods seek to solve the problem by manually designing representative features or building prototypes for each class from global features. However, these methods still struggle to deal with the large visual diversity of each intent category. In this paper, we introduce a novel approach named Multi-grained Compositional visual Clue Learning (MCCL) to address these challenges for image intent recognition. Our method leverages the systematic compositionality of human cognition by breaking down intent recognition into visual clue composition and integrating multi-grained features. We adopt class-specific prototypes to alleviate data imbalance. We treat intent recognition as a multi-label classification problem, using a graph convolutional network to infuse prior knowledge through label embedding correlations. Demonstrated by a state-of-the-art performance on the Intentonomy and MDID datasets, our approach advances the accuracy of existing methods while also possessing good interpretability. Our work provides an attempt for future explorations in understanding complex and miscellaneous forms of human expression.
Consistent Diffusion: Denoising Diffusion Model with Data-Consistent Training for Image Restoration
Dec 17, 2024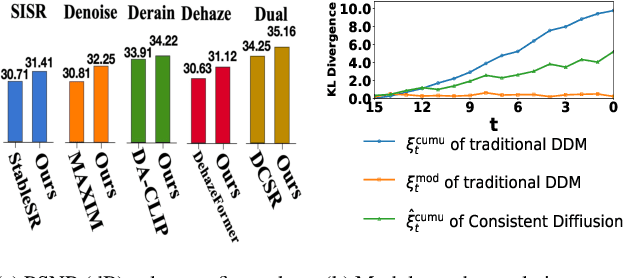
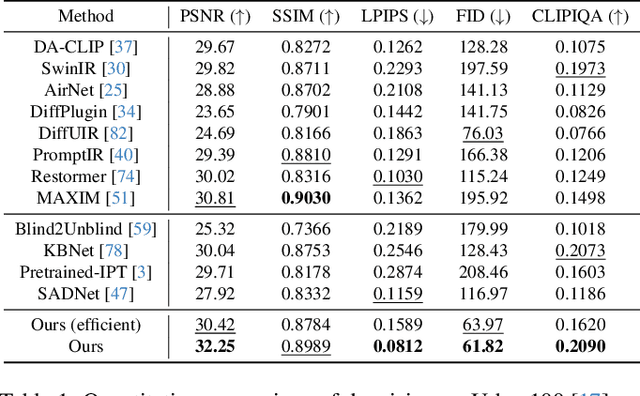


In this work, we address the limitations of denoising diffusion models (DDMs) in image restoration tasks, particularly the shape and color distortions that can compromise image quality. While DDMs have demonstrated a promising performance in many applications such as text-to-image synthesis, their effectiveness in image restoration is often hindered by shape and color distortions. We observe that these issues arise from inconsistencies between the training and testing data used by DDMs. Based on our observation, we propose a novel training method, named data-consistent training, which allows the DDMs to access images with accumulated errors during training, thereby ensuring the model to learn to correct these errors. Experimental results show that, across five image restoration tasks, our method has significant improvements over state-of-the-art methods while effectively minimizing distortions and preserving image fidelity.
PVC: Progressive Visual Token Compression for Unified Image and Video Processing in Large Vision-Language Models
Dec 12, 2024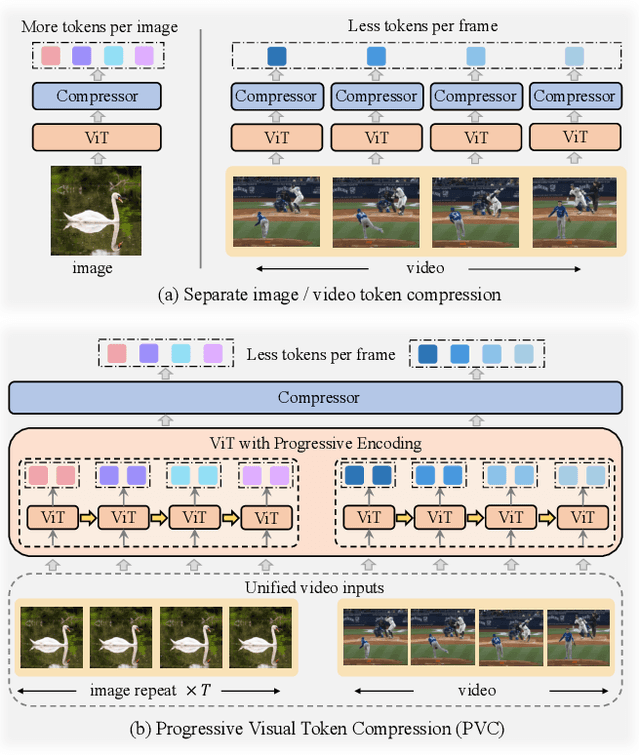
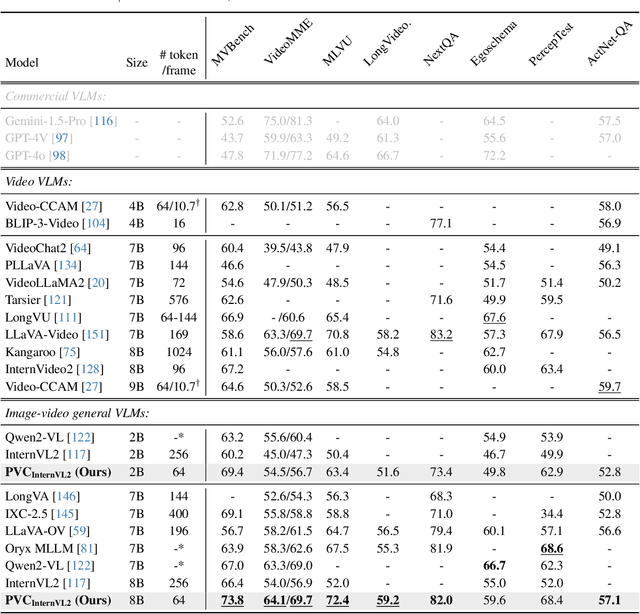
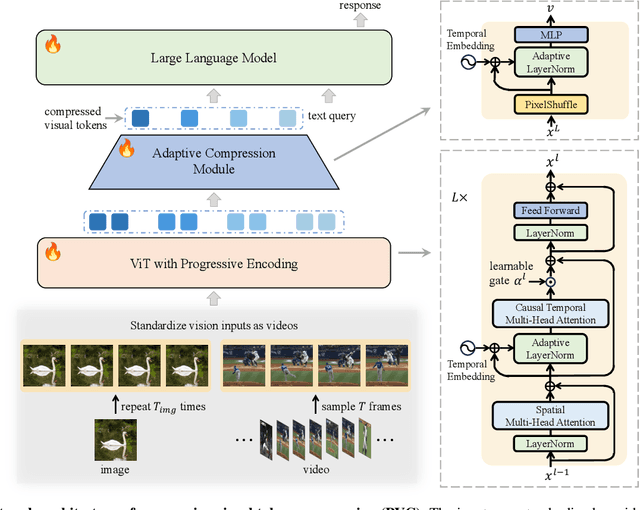
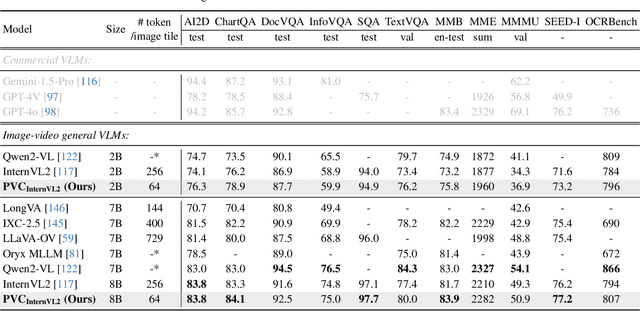
Large Vision-Language Models (VLMs) have been extended to understand both images and videos. Visual token compression is leveraged to reduce the considerable token length of visual inputs. To meet the needs of different tasks, existing high-performance models usually process images and videos separately with different token compression strategies, limiting the capabilities of combining images and videos. To this end, we extend each image into a "static" video and introduce a unified token compression strategy called Progressive Visual Token Compression (PVC), where the tokens of each frame are progressively encoded and adaptively compressed to supplement the information not extracted from previous frames. Video tokens are efficiently compressed with exploiting the inherent temporal redundancy. Images are repeated as static videos, and the spatial details can be gradually supplemented in multiple frames. PVC unifies the token compressing of images and videos. With a limited number of tokens per frame (64 tokens by default), spatial details and temporal changes can still be preserved. Experiments show that our model achieves state-of-the-art performance across various video understanding benchmarks, including long video tasks and fine-grained short video tasks. Meanwhile, our unified token compression strategy incurs no performance loss on image benchmarks, particularly in detail-sensitive tasks.
Vision Model Pre-training on Interleaved Image-Text Data via Latent Compression Learning
Jun 11, 2024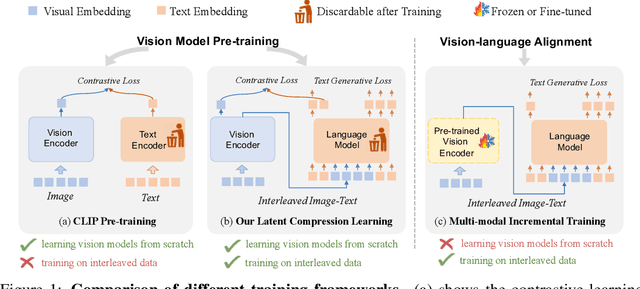

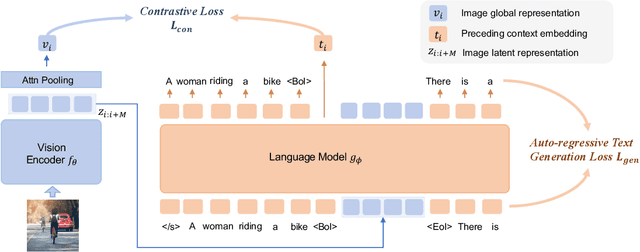

Recently, vision model pre-training has evolved from relying on manually annotated datasets to leveraging large-scale, web-crawled image-text data. Despite these advances, there is no pre-training method that effectively exploits the interleaved image-text data, which is very prevalent on the Internet. Inspired by the recent success of compression learning in natural language processing, we propose a novel vision model pre-training method called Latent Compression Learning (LCL) for interleaved image-text data. This method performs latent compression learning by maximizing the mutual information between the inputs and outputs of a causal attention model. The training objective can be decomposed into two basic tasks: 1) contrastive learning between visual representation and preceding context, and 2) generating subsequent text based on visual representation. Our experiments demonstrate that our method not only matches the performance of CLIP on paired pre-training datasets (e.g., LAION), but can also leverage interleaved pre-training data (e.g., MMC4) to learn robust visual representation from scratch, showcasing the potential of vision model pre-training with interleaved image-text data. Code is released at https://github.com/OpenGVLab/LCL.
ReWiTe: Realistic Wide-angle and Telephoto Dual Camera Fusion Dataset via Beam Splitter Camera Rig
Apr 16, 2024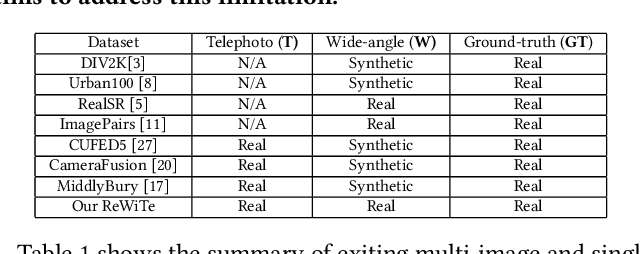
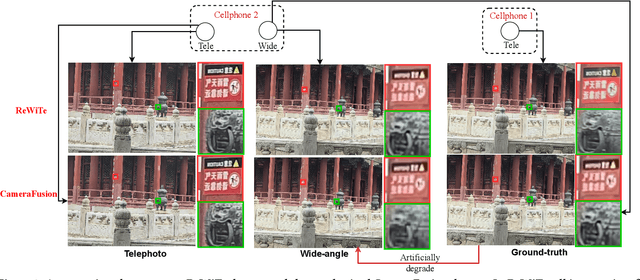
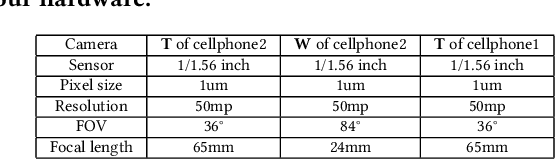

The fusion of images from dual camera systems featuring a wide-angle and a telephoto camera has become a hotspot problem recently. By integrating simultaneously captured wide-angle and telephoto images from these systems, the resulting fused image achieves a wide field of view (FOV) coupled with high-definition quality. Existing approaches are mostly deep learning methods, and predominantly rely on supervised learning, where the training dataset plays a pivotal role. However, current datasets typically adopt a data synthesis approach generate input pairs of wide-angle and telephoto images alongside ground-truth images. Notably, the wide-angle inputs are synthesized rather than captured using real wide-angle cameras, and the ground-truth image is captured by wide-angle camera whose quality is substantially lower than that of input telephoto images captured by telephoto cameras. To address these limitations, we introduce a novel hardware setup utilizing a beam splitter to simultaneously capture three images, i.e. input pairs and ground-truth images, from two authentic cellphones equipped with wide-angle and telephoto dual cameras. Specifically, the wide-angle and telephoto images captured by cellphone 2 serve as the input pair, while the telephoto image captured by cellphone 1, which is calibrated to match the optical path of the wide-angle image from cellphone 2, serves as the ground-truth image, maintaining quality on par with the input telephoto image. Experiments validate the efficacy of our newly introduced dataset, named ReWiTe, significantly enhances the performance of various existing methods for real-world wide-angle and telephoto dual image fusion tasks.