 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Grained Compositional Visual Clue Learning for Image Intent Recognition
Apr 25, 2025In an era where social media platforms abound, individuals frequently share images that offer insights into their intents and interests, impacting individual life quality and societal stability. Traditional computer vision tasks, such as object detection and semantic segmentation, focus on concrete visual representations, while intent recognition relies more on implicit visual clues. This poses challenges due to the wide variation and subjectivity of such clues, compounded by the problem of intra-class variety in conveying abstract concepts, e.g. "enjoy life". Existing methods seek to solve the problem by manually designing representative features or building prototypes for each class from global features. However, these methods still struggle to deal with the large visual diversity of each intent category. In this paper, we introduce a novel approach named Multi-grained Compositional visual Clue Learning (MCCL) to address these challenges for image intent recognition. Our method leverages the systematic compositionality of human cognition by breaking down intent recognition into visual clue composition and integrating multi-grained features. We adopt class-specific prototypes to alleviate data imbalance. We treat intent recognition as a multi-label classification problem, using a graph convolutional network to infuse prior knowledge through label embedding correlations. Demonstrated by a state-of-the-art performance on the Intentonomy and MDID datasets, our approach advances the accuracy of existing methods while also possessing good interpretability. Our work provides an attempt for future explorations in understanding complex and miscellaneous forms of human expression.
Leveraging Predicate and Triplet Learning for Scene Graph Generation
Jun 04, 2024

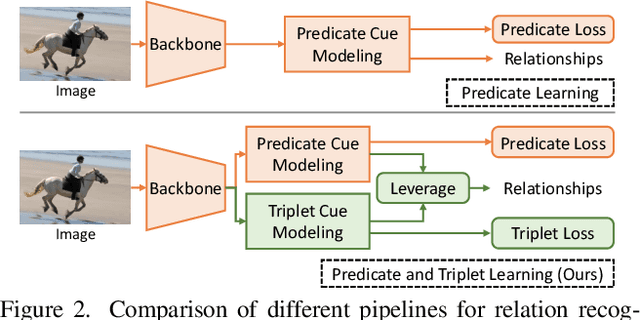

Scene Graph Generation (SGG) aims to identify entities and predict the relationship triplets \textit{\textless subject, predicate, object\textgreater } in visual scenes. Given the prevalence of large visual variations of subject-object pairs even in the same predicate, it can be quite challenging to model and refine predicate representations directly across such pairs, which is however a common strategy adopted by most existing SGG methods. We observe that visual variations within the identical triplet are relatively small and certain relation cues are shared in the same type of triplet, which can potentially facilitate the relation learning in SGG. Moreover, for the long-tail problem widely studied in SGG task, it is also crucial to deal with the limited types and quantity of triplets in tail predicates. Accordingly, in this paper, we propose a Dual-granularity Relation Modeling (DRM) network to leverage fine-grained triplet cues besides the coarse-grained predicate ones. DRM utilizes contexts and semantics of predicate and triplet with Dual-granularity Constraints, generating compact and balanced representations from two perspectives to facilitate relation recognition. Furthermore, a Dual-granularity Knowledge Transfer (DKT) strategy is introduced to transfer variation from head predicates/triplets to tail ones, aiming to enrich the pattern diversity of tail classes to alleviate the long-tail problem. Extensive experiments demonstrate the effectiveness of our method, which establishes new state-of-the-art performance on Visual Genome, Open Image, and GQA datasets. Our code is available at \url{https://github.com/jkli1998/DRM}
InitNO: Boosting Text-to-Image Diffusion Models via Initial Noise Optimization
Apr 06, 2024



Recent strides in the development of diffusion models, exemplified by advancements such as Stable Diffusion, have underscored their remarkable prowess in generating visually compelling images. However, the imperative of achieving a seamless alignment between the generated image and the provided prompt persists as a formidable challenge. This paper traces the root of these difficulties to invalid initial noise, and proposes a solution in the form of Initial Noise Optimization (InitNO), a paradigm that refines this noise. Considering text prompts, not all random noises are effective in synthesizing semantically-faithful images. We design the cross-attention response score and the self-attention conflict score to evaluate the initial noise, bifurcating the initial latent space into valid and invalid sectors. A strategically crafted noise optimization pipeline is developed to guide the initial noise towards valid regions. Our method, validated through rigorous experimentation, shows a commendable proficiency in generating images in strict accordance with text prompts. Our code is available at https://github.com/xiefan-guo/initno.
Zero-Shot Scene Graph Generation via Triplet Calibration and Reduction
Sep 07, 2023



Scene Graph Generation (SGG) plays a pivotal role in downstream vision-language tasks. Existing SGG methods typically suffer from poor compositional generalizations on unseen triplets. They are generally trained on incompletely annotated scene graphs that contain dominant triplets and tend to bias toward these seen triplets during inference. To address this issue, we propose a Triplet Calibration and Reduction (T-CAR) framework in this paper. In our framework, a triplet calibration loss is first presented to regularize the representations of diverse triplets and to simultaneously excavate the unseen triplets in incompletely annotated training scene graphs. Moreover, the unseen space of scene graphs is usually several times larger than the seen space since it contains a huge number of unrealistic compositions. Thus, we propose an unseen space reduction loss to shift the attention of excavation to reasonable unseen compositions to facilitate the model training. Finally, we propose a contextual encoder to improve the compositional generalizations of unseen triplets by explicitly modeling the relative spatial relations between subjects and objects. Extensive experiments show that our approach achieves consistent improvements for zero-shot SGG over state-of-the-art methods. The code is available at https://github.com/jkli1998/T-CAR.