 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerturbation-Induced Linearization: Constructing Unlearnable Data with Solely Linear Classifiers
Jan 29, 2026Collecting web data to train deep models has become increasingly common, raising concerns about unauthorized data usage. To mitigate this issue, unlearnable examples introduce imperceptible perturbations into data, preventing models from learning effectively. However, existing methods typically rely on deep neural networks as surrogate models for perturbation generation, resulting in significant computational costs. In this work, we propose Perturbation-Induced Linearization (PIL), a computationally efficient yet effective method that generates perturbations using only linear surrogate models. PIL achieves comparable or better performance than existing surrogate-based methods while reducing computational time dramatically. We further reveal a key mechanism underlying unlearnable examples: inducing linearization to deep models, which explains why PIL can achieve competitive results in a very short time. Beyond this, we provide an analysis about the property of unlearnable examples under percentage-based partial perturbation. Our work not only provides a practical approach for data protection but also offers insights into what makes unlearnable examples effective.
I4VGen: Image as Stepping Stone for Text-to-Video Generation
Jun 04, 2024



Text-to-video generation has lagged behind text-to-image synthesis in quality and diversity due to the complexity of spatio-temporal modeling and limited video-text datasets. This paper presents I4VGen, a training-free and plug-and-play video diffusion inference framework, which enhances text-to-video generation by leveraging robust image techniques. Specifically, following text-to-image-to-video, I4VGen decomposes the text-to-video generation into two stages: anchor image synthesis and anchor image-guided video synthesis. Correspondingly, a well-designed generation-selection pipeline is employed to achieve visually-realistic and semantically-faithful anchor image, and an innovative Noise-Invariant Video Score Distillation Sampling is incorporated to animate the image to a dynamic video, followed by a video regeneration process to refine the video. This inference strategy effectively mitigates the prevalent issue of non-zero terminal signal-to-noise ratio. Extensive evaluations show that I4VGen not only produces videos with higher visual realism and textual fidelity but also integrates seamlessly into existing image-to-video diffusion models, thereby improving overall video quality.
Disentangling Foreground and Background Motion for Enhanced Realism in Human Video Generation
May 28, 2024



Recent advancements in human video synthesis have enabled the generation of high-quality videos through the application of stable diffusion models. However, existing methods predominantly concentrate on animating solely the human element (the foreground) guided by pose information, while leaving the background entirely static. Contrary to this, in authentic, high-quality videos, backgrounds often dynamically adjust in harmony with foreground movements, eschewing stagnancy. We introduce a technique that concurrently learns both foreground and background dynamics by segregating their movements using distinct motion representations. Human figures are animated leveraging pose-based motion, capturing intricate actions. Conversely, for backgrounds, we employ sparse tracking points to model motion, thereby reflecting the natural interaction between foreground activity and environmental changes. Training on real-world videos enhanced with this innovative motion depiction approach, our model generates videos exhibiting coherent movement in both foreground subjects and their surrounding contexts. To further extend video generation to longer sequences without accumulating errors, we adopt a clip-by-clip generation strategy, introducing global features at each step. To ensure seamless continuity across these segments, we ingeniously link the final frame of a produced clip with input noise to spawn the succeeding one, maintaining narrative flow. Throughout the sequential generation process, we infuse the feature representation of the initial reference image into the network, effectively curtailing any cumulative color inconsistencies that may otherwise arise. Empirical evaluations attest to the superiority of our method in producing videos that exhibit harmonious interplay between foreground actions and responsive background dynamics, surpassing prior methodologies in this regard.
InitNO: Boosting Text-to-Image Diffusion Models via Initial Noise Optimization
Apr 06, 2024



Recent strides in the development of diffusion models, exemplified by advancements such as Stable Diffusion, have underscored their remarkable prowess in generating visually compelling images. However, the imperative of achieving a seamless alignment between the generated image and the provided prompt persists as a formidable challenge. This paper traces the root of these difficulties to invalid initial noise, and proposes a solution in the form of Initial Noise Optimization (InitNO), a paradigm that refines this noise. Considering text prompts, not all random noises are effective in synthesizing semantically-faithful images. We design the cross-attention response score and the self-attention conflict score to evaluate the initial noise, bifurcating the initial latent space into valid and invalid sectors. A strategically crafted noise optimization pipeline is developed to guide the initial noise towards valid regions. Our method, validated through rigorous experimentation, shows a commendable proficiency in generating images in strict accordance with text prompts. Our code is available at https://github.com/xiefan-guo/initno.
DreaMoving: A Human Video Generation Framework based on Diffusion Models
Dec 11, 2023



In this paper, we present DreaMoving, a diffusion-based controllable video generation framework to produce high-quality customized human videos. Specifically, given target identity and posture sequences, DreaMoving can generate a video of the target identity moving or dancing anywhere driven by the posture sequences. To this end, we propose a Video ControlNet for motion-controlling and a Content Guider for identity preserving. The proposed model is easy to use and can be adapted to most stylized diffusion models to generate diverse results. The project page is available at https://dreamoving.github.io/dreamoving
Diffusion360: Seamless 360 Degree Panoramic Image Generation based on Diffusion Models
Nov 22, 2023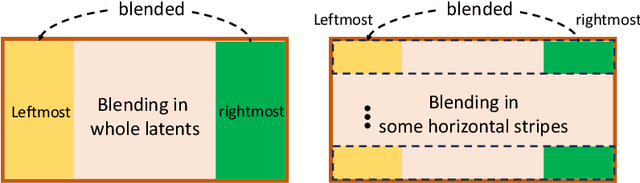



This is a technical report on the 360-degree panoramic image generation task based on diffusion models. Unlike ordinary 2D images, 360-degree panoramic images capture the entire $360^\circ\times 180^\circ$ field of view. So the rightmost and the leftmost sides of the 360 panoramic image should be continued, which is the main challenge in this field. However, the current diffusion pipeline is not appropriate for generating such a seamless 360-degree panoramic image. To this end, we propose a circular blending strategy on both the denoising and VAE decoding stages to maintain the geometry continuity. Based on this, we present two models for \textbf{Text-to-360-panoramas} and \textbf{Single-Image-to-360-panoramas} tasks. The code has been released as an open-source project at \href{https://github.com/ArcherFMY/SD-T2I-360PanoImage}{https://github.com/ArcherFMY/SD-T2I-360PanoImage} and \href{https://www.modelscope.cn/models/damo/cv_diffusion_text-to-360panorama-image_generation/summary}{ModelScope}
Boosting3D: High-Fidelity Image-to-3D by Boosting 2D Diffusion Prior to 3D Prior with Progressive Learning
Nov 22, 2023



We present Boosting3D, a multi-stage single image-to-3D generation method that can robustly generate reasonable 3D objects in different data domains. The point of this work is to solve the view consistency problem in single image-guided 3D generation by modeling a reasonable geometric structure. For this purpose, we propose to utilize better 3D prior to training the NeRF. More specifically, we train an object-level LoRA for the target object using original image and the rendering output of NeRF. And then we train the LoRA and NeRF using a progressive training strategy. The LoRA and NeRF will boost each other while training. After the progressive training, the LoRA learns the 3D information of the generated object and eventually turns to an object-level 3D prior. In the final stage, we extract the mesh from the trained NeRF and use the trained LoRA to optimize the structure and appearance of the mesh. The experiments demonstrate the effectiveness of the proposed method. Boosting3D learns object-specific 3D prior which is beyond the ability of pre-trained diffusion priors and achieves state-of-the-art performance in the single image-to-3d generation task.
Adaptive Background Matting Using Background Matching
Mar 14, 2022
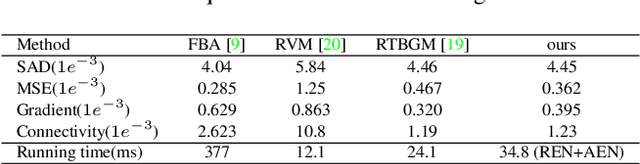
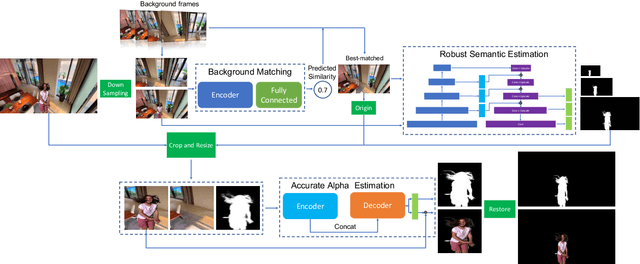
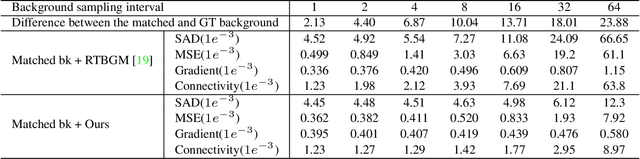
Due to the difficulty of solving the matting problem, lots of methods use some kinds of assistance to acquire high quality alpha matte. Green screen matting methods rely on physical equipment. Trimap-based methods take manual interactions as external input. Background-based methods require a pre-captured, static background. The methods are not flexible and convenient enough to use widely. Trimap-free methods are flexible but not stable in complicated video applications. To be stable and flexible in real applications, we propose an adaptive background matting method. The user first captures their videos freely, moving the cameras. Then the user captures the background video afterwards, roughly covering the previous captured regions. We use dynamic background video instead of static background for accurate matting. The proposed method is convenient to use in any scenes as the static camera and background is no more the limitation. To achieve this goal, we use background matching network to find the best-matched background frame by frame from dynamic backgrounds. Then, robust semantic estimation network is used to estimate the coarse alpha matte. Finally, we crop and zoom the target region according to the coarse alpha matte, and estimate the final accurate alpha matte. In experiments, the proposed method is able to perform comparably against the state-of-the-art matting methods.
Active Boundary Loss for Semantic Segmentation
Feb 04, 2021
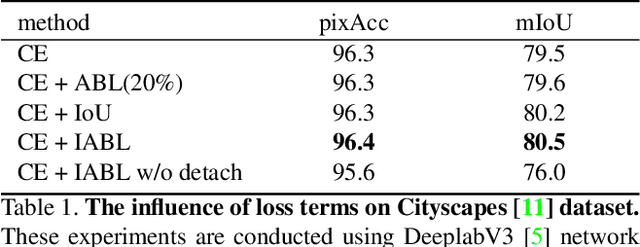

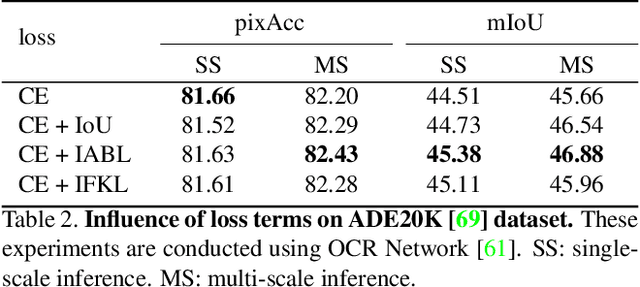
This paper proposes a novel active boundary loss for semantic segmentation. It can progressively encourage the alignment between predicted boundaries and ground-truth boundaries during end-to-end training, which is not explicitly enforced in commonly used cross-entropy loss. Based on the predicted boundaries detected from the segmentation results using current network parameters, we formulate the boundary alignment problem as a differentiable direction vector prediction problem to guide the movement of predicted boundaries in each iteration. Our loss is model-agnostic and can be plugged into the training of segmentation networks to improve the boundary details. Experimental results show that training with the active boundary loss can effectively improve the boundary F-score and mean Intersection-over-Union on challenging image and video object segmentation datasets.
Boosting Semantic Human Matting with Coarse Annotations
Apr 10, 2020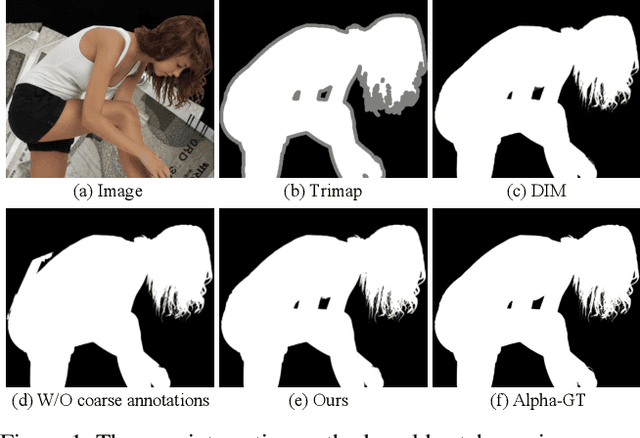
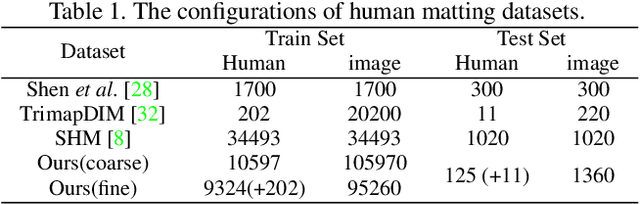
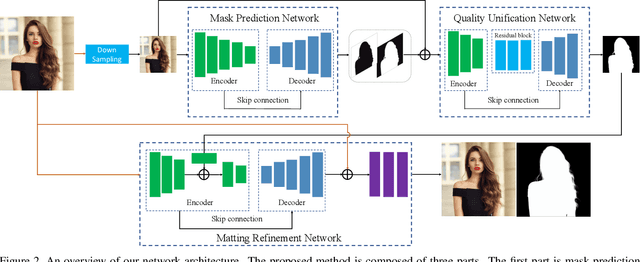
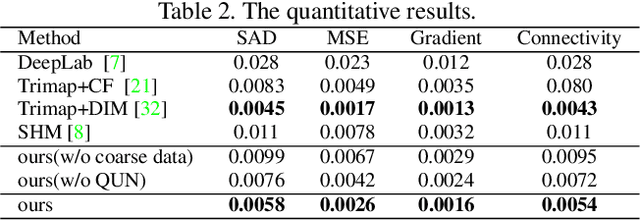
Semantic human matting aims to estimate the per-pixel opacity of the foreground human regions. It is quite challenging and usually requires user interactive trimaps and plenty of high quality annotated data. Annotating such kind of data is labor intensive and requires great skills beyond normal users, especially considering the very detailed hair part of humans. In contrast, coarse annotated human dataset is much easier to acquire and collect from the public dataset. In this paper, we propose to use coarse annotated data coupled with fine annotated data to boost end-to-end semantic human matting without trimaps as extra input. Specifically, we train a mask prediction network to estimate the coarse semantic mask using the hybrid data, and then propose a quality unification network to unify the quality of the previous coarse mask outputs. A matting refinement network takes in the unified mask and the input image to predict the final alpha matte. The collected coarse annotated dataset enriches our dataset significantly, allows generating high quality alpha matte for real images. Experimental results show that the proposed method performs comparably against state-of-the-art methods. Moreover, the proposed method can be used for refining coarse annotated public dataset, as well as semantic segmentation methods, which reduces the cost of annotating high quality human data to a great extent.