 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
Disentangling Foreground and Background Motion for Enhanced Realism in Human Video Generation
May 28, 2024



Recent advancements in human video synthesis have enabled the generation of high-quality videos through the application of stable diffusion models. However, existing methods predominantly concentrate on animating solely the human element (the foreground) guided by pose information, while leaving the background entirely static. Contrary to this, in authentic, high-quality videos, backgrounds often dynamically adjust in harmony with foreground movements, eschewing stagnancy. We introduce a technique that concurrently learns both foreground and background dynamics by segregating their movements using distinct motion representations. Human figures are animated leveraging pose-based motion, capturing intricate actions. Conversely, for backgrounds, we employ sparse tracking points to model motion, thereby reflecting the natural interaction between foreground activity and environmental changes. Training on real-world videos enhanced with this innovative motion depiction approach, our model generates videos exhibiting coherent movement in both foreground subjects and their surrounding contexts. To further extend video generation to longer sequences without accumulating errors, we adopt a clip-by-clip generation strategy, introducing global features at each step. To ensure seamless continuity across these segments, we ingeniously link the final frame of a produced clip with input noise to spawn the succeeding one, maintaining narrative flow. Throughout the sequential generation process, we infuse the feature representation of the initial reference image into the network, effectively curtailing any cumulative color inconsistencies that may otherwise arise. Empirical evaluations attest to the superiority of our method in producing videos that exhibit harmonious interplay between foreground actions and responsive background dynamics, surpassing prior methodologies in this regard.
DiffusionGAN3D: Boosting Text-guided 3D Generation and Domain Adaption by Combining 3D GANs and Diffusion Priors
Dec 29, 2023



Text-guided domain adaption and generation of 3D-aware portraits find many applications in various fields. However, due to the lack of training data and the challenges in handling the high variety of geometry and appearance, the existing methods for these tasks suffer from issues like inflexibility, instability, and low fidelity. In this paper, we propose a novel framework DiffusionGAN3D, which boosts text-guided 3D domain adaption and generation by combining 3D GANs and diffusion priors. Specifically, we integrate the pre-trained 3D generative models (e.g., EG3D) and text-to-image diffusion models. The former provides a strong foundation for stable and high-quality avatar generation from text. And the diffusion models in turn offer powerful priors and guide the 3D generator finetuning with informative direction to achieve flexible and efficient text-guided domain adaption. To enhance the diversity in domain adaption and the generation capability in text-to-avatar, we introduce the relative distance loss and case-specific learnable triplane respectively. Besides, we design a progressive texture refinement module to improve the texture quality for both tasks above. Extensive experiments demonstrate that the proposed framework achieves excellent results in both domain adaption and text-to-avatar tasks, outperforming existing methods in terms of generation quality and efficiency. The project homepage is at https://younglbw.github.io/DiffusionGAN3D-homepage/.
DreaMoving: A Human Video Generation Framework based on Diffusion Models
Dec 11, 2023



In this paper, we present DreaMoving, a diffusion-based controllable video generation framework to produce high-quality customized human videos. Specifically, given target identity and posture sequences, DreaMoving can generate a video of the target identity moving or dancing anywhere driven by the posture sequences. To this end, we propose a Video ControlNet for motion-controlling and a Content Guider for identity preserving. The proposed model is easy to use and can be adapted to most stylized diffusion models to generate diverse results. The project page is available at https://dreamoving.github.io/dreamoving
Boosting3D: High-Fidelity Image-to-3D by Boosting 2D Diffusion Prior to 3D Prior with Progressive Learning
Nov 22, 2023



We present Boosting3D, a multi-stage single image-to-3D generation method that can robustly generate reasonable 3D objects in different data domains. The point of this work is to solve the view consistency problem in single image-guided 3D generation by modeling a reasonable geometric structure. For this purpose, we propose to utilize better 3D prior to training the NeRF. More specifically, we train an object-level LoRA for the target object using original image and the rendering output of NeRF. And then we train the LoRA and NeRF using a progressive training strategy. The LoRA and NeRF will boost each other while training. After the progressive training, the LoRA learns the 3D information of the generated object and eventually turns to an object-level 3D prior. In the final stage, we extract the mesh from the trained NeRF and use the trained LoRA to optimize the structure and appearance of the mesh. The experiments demonstrate the effectiveness of the proposed method. Boosting3D learns object-specific 3D prior which is beyond the ability of pre-trained diffusion priors and achieves state-of-the-art performance in the single image-to-3d generation task.
Diffusion360: Seamless 360 Degree Panoramic Image Generation based on Diffusion Models
Nov 22, 2023This is a technical report on the 360-degree panoramic image generation task based on diffusion models. Unlike ordinary 2D images, 360-degree panoramic images capture the entire $360^\circ\times 180^\circ$ field of view. So the rightmost and the leftmost sides of the 360 panoramic image should be continued, which is the main challenge in this field. However, the current diffusion pipeline is not appropriate for generating such a seamless 360-degree panoramic image. To this end, we propose a circular blending strategy on both the denoising and VAE decoding stages to maintain the geometry continuity. Based on this, we present two models for \textbf{Text-to-360-panoramas} and \textbf{Single-Image-to-360-panoramas} tasks. The code has been released as an open-source project at \href{https://github.com/ArcherFMY/SD-T2I-360PanoImage}{https://github.com/ArcherFMY/SD-T2I-360PanoImage} and \href{https://www.modelscope.cn/models/damo/cv_diffusion_text-to-360panorama-image_generation/summary}{ModelScope}
A Hierarchical Representation Network for Accurate and Detailed Face Reconstruction from In-The-Wild Images
Feb 28, 2023Limited by the nature of the low-dimensional representational capacity of 3DMM, most of the 3DMM-based face reconstruction (FR) methods fail to recover high-frequency facial details, such as wrinkles, dimples, etc. Some attempt to solve the problem by introducing detail maps or non-linear operations, however, the results are still not vivid. To this end, we in this paper present a novel hierarchical representation network (HRN) to achieve accurate and detailed face reconstruction from a single image. Specifically, we implement the geometry disentanglement and introduce the hierarchical representation to fulfill detailed face modeling. Meanwhile, 3D priors of facial details are incorporated to enhance the accuracy and authenticity of the reconstruction results. We also propose a de-retouching module to achieve better decoupling of the geometry and appearance. It is noteworthy that our framework can be extended to a multi-view fashion by considering detail consistency of different views. Extensive experiments on two single-view and two multi-view FR benchmarks demonstrate that our method outperforms the existing methods in both reconstruction accuracy and visual effects. Finally, we introduce a high-quality 3D face dataset FaceHD-100 to boost the research of high-fidelity face reconstruction.
An Unsupervised Game-Theoretic Approach to Saliency Detection
Aug 08, 2017
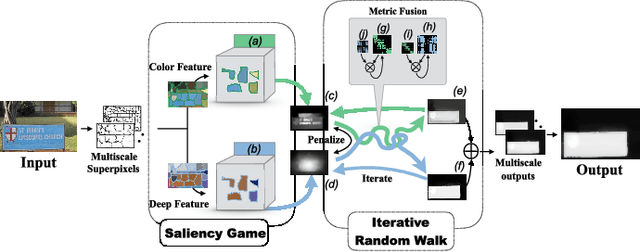


We propose a novel unsupervised game-theoretic salient object detection algorithm that does not require labeled training data. First, saliency detection problem is formulated as a non-cooperative game, hereinafter referred to as Saliency Game, in which image regions are players who choose to be "background" or "foreground" as their pure strategies. A payoff function is constructed by exploiting multiple cues and combining complementary features. Saliency maps are generated according to each region's strategy in the Nash equilibrium of the proposed Saliency Game. Second, we explore the complementary relationship between color and deep features and propose an Iterative Random Walk algorithm to combine saliency maps produced by the Saliency Game using different features. Iterative random walk allows sharing information across feature spaces, and detecting objects that are otherwise very hard to detect. Extensive experiments over 6 challenging datasets demonstrate the superiority of our proposed unsupervised algorithm compared to several state of the art supervised algorithms.
Hierarchical Cellular Automata for Visual Saliency
May 26, 2017
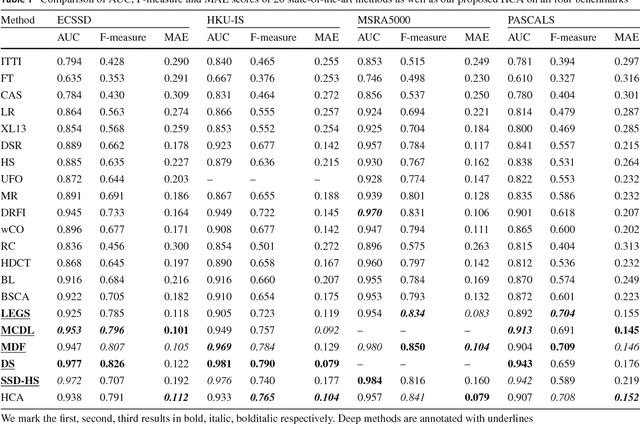
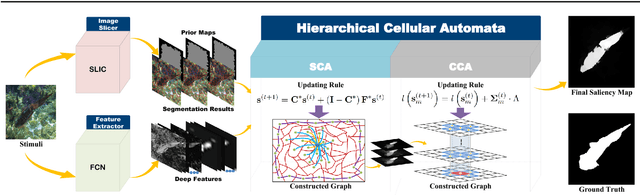

Saliency detection, finding the most important parts of an image, has become increasingly popular in computer vision. In this paper, we introduce Hierarchical Cellular Automata (HCA) -- a temporally evolving model to intelligently detect salient objects. HCA consists of two main components: Single-layer Cellular Automata (SCA) and Cuboid Cellular Automata (CCA). As an unsupervised propagation mechanism, Single-layer Cellular Automata can exploit the intrinsic relevance of similar regions through interactions with neighbors. Low-level image features as well as high-level semantic information extracted from deep neural networks are incorporated into the SCA to measure the correlation between different image patches. With these hierarchical deep features, an impact factor matrix and a coherence matrix are constructed to balance the influences on each cell's next state. The saliency values of all cells are iteratively updated according to a well-defined update rule. Furthermore, we propose CCA to integrate multiple saliency maps generated by SCA at different scales in a Bayesian framework. Therefore, single-layer propagation and multi-layer integration are jointly modeled in our unified HCA. Surprisingly, we find that the SCA can improve all existing methods that we applied it to, resulting in a similar precision level regardless of the original results. The CCA can act as an efficient pixel-wise aggregation algorithm that can integrate state-of-the-art methods, resulting in even better results. Extensive experiments on four challenging datasets demonstrate that the proposed algorithm outperforms state-of-the-art conventional methods and is competitive with deep learning based approaches.
Vanishing point attracts gaze in free-viewing and visual search tasks
Sep 06, 2016



To investigate whether the vanishing point (VP) plays a significant role in gaze guidance, we ran two experiments. In the first one, we recorded fixations of 10 observers (4 female; mean age 22; SD=0.84) freely viewing 532 images, out of which 319 had VP (shuffled presentation; each image for 4 secs). We found that the average number of fixations at a local region (80x80 pixels) centered at the VP is significantly higher than the average fixations at random locations (t-test; n=319; p=1.8e-35). To address the confounding factor of saliency, we learned a combined model of bottom-up saliency and VP. AUC score of our model (0.85; SD=0.01) is significantly higher than the original saliency model (e.g., 0.8 using AIM model by Bruce & Tsotsos (2009), t-test; p= 3.14e-16) and the VP-only model (0.64, t-test; p= 4.02e-22). In the second experiment, we asked 14 subjects (4 female, mean age 23.07, SD=1.26) to search for a target character (T or L) placed randomly on a 3x3 imaginary grid overlaid on top of an image. Subjects reported their answers by pressing one of two keys. Stimuli consisted of 270 color images (180 with a single VP, 90 without). The target happened with equal probability inside each cell (15 times L, 15 times T). We found that subjects were significantly faster (and more accurate) when target happened inside the cell containing the VP compared to cells without VP (median across 14 subjects 1.34 sec vs. 1.96; Wilcoxon rank-sum test; p = 0.0014). Response time at VP cells were also significantly lower than response time on images without VP (median 2.37; p= 4.77e-05). These findings support the hypothesis that vanishing point, similar to face and text (Cerf et al., 2009) as well as gaze direction (Borji et al., 2014) attracts attention in free-viewing and visual search.