 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Wildland Fire Smoke Detection
Dec 29, 2022


Research has shown that climate change creates warmer temperatures and drier conditions, leading to longer wildfire seasons and increased wildfire risks in the United States. These factors have in turn led to increases in the frequency, extent, and severity of wildfires in recent years. Given the danger posed by wildland fires to people, property, wildlife, and the environment, there is an urgency to provide tools for effective wildfire management. Early detection of wildfires is essential to minimizing potentially catastrophic destruction. In this paper, we present our work on integrating multiple data sources in SmokeyNet, a deep learning model using spatio-temporal information to detect smoke from wildland fires. Camera image data is integrated with weather sensor measurements and processed by SmokeyNet to create a multimodal wildland fire smoke detection system. We present our results comparing performance in terms of both accuracy and time-to-detection for multimodal data vs. a single data source. With a time-to-detection of only a few minutes, SmokeyNet can serve as an automated early notification system, providing a useful tool in the fight against destructive wildfires.
Generating Rationales in Visual Question Answering
Apr 04, 2020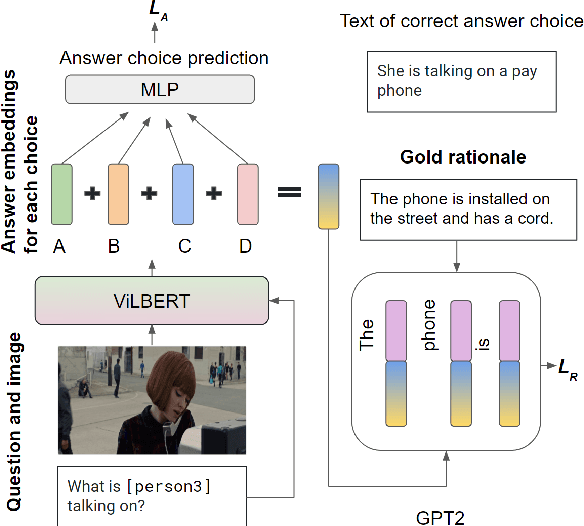
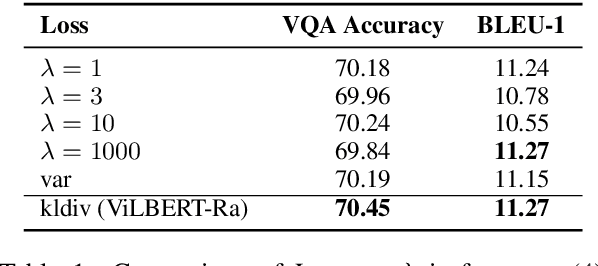


Despite recent advances in Visual QuestionAnswering (VQA), it remains a challenge todetermine how much success can be attributedto sound reasoning and comprehension ability.We seek to investigate this question by propos-ing a new task ofrationale generation. Es-sentially, we task a VQA model with generat-ing rationales for the answers it predicts. Weuse data from the Visual Commonsense Rea-soning (VCR) task, as it contains ground-truthrationales along with visual questions and an-swers. We first investigate commonsense un-derstanding in one of the leading VCR mod-els, ViLBERT, by generating rationales frompretrained weights using a state-of-the-art lan-guage model, GPT-2. Next, we seek to jointlytrain ViLBERT with GPT-2 in an end-to-endfashion with the dual task of predicting the an-swer in VQA and generating rationales. Weshow that this kind of training injects com-monsense understanding in the VQA modelthrough quantitative and qualitative evaluationmetrics
ReZero is All You Need: Fast Convergence at Large Depth
Mar 10, 2020
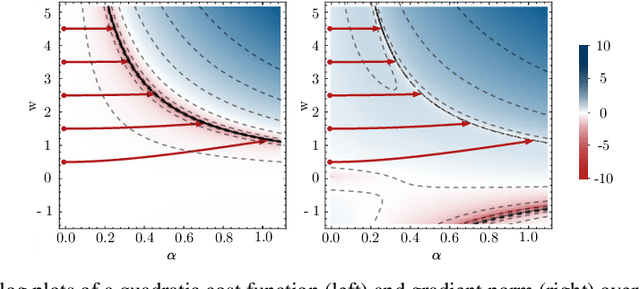

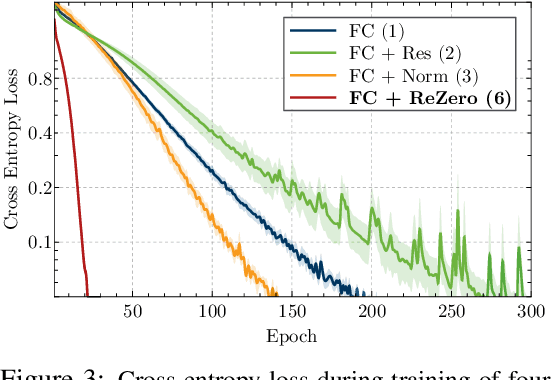
Deep networks have enabled significant performance gains across domains, but they often suffer from vanishing/exploding gradients. This is especially true for Transformer architectures where depth beyond 12 layers is difficult to train without large datasets and computational budgets. In general, we find that inefficient signal propagation impedes learning in deep networks. In Transformers, multi-head self-attention is the main cause of this poor signal propagation. To facilitate deep signal propagation, we propose ReZero, a simple change to the architecture that initializes an arbitrary layer as the identity map, using a single additional learned parameter per layer. We apply this technique to language modeling and find that we can easily train ReZero-Transformer networks over a hundred layers. When applied to 12 layer Transformers, ReZero converges 56% faster on enwiki8. ReZero applies beyond Transformers to other residual networks, enabling 1,500% faster convergence for deep fully connected networks and 32% faster convergence for a ResNet-56 trained on CIFAR 10.
Improving Neural Story Generation by Targeted Common Sense Grounding
Aug 26, 2019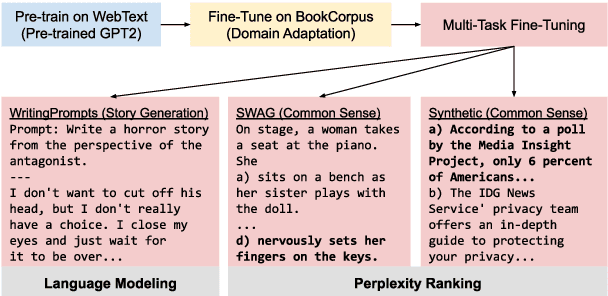
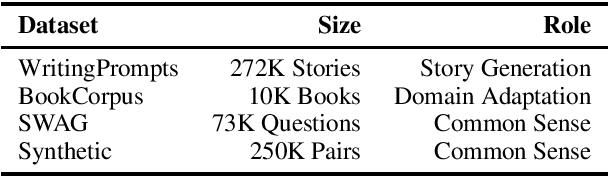

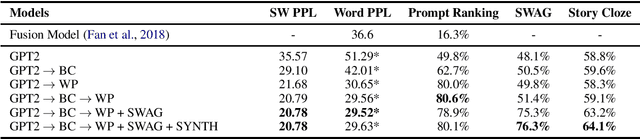
Stories generated with neural language models have shown promise in grammatical and stylistic consistency. However, the generated stories are still lacking in common sense reasoning, e.g., they often contain sentences deprived of world knowledge. We propose a simple multi-task learning scheme to achieve quantitatively better common sense reasoning in language models by leveraging auxiliary training signals from datasets designed to provide common sense grounding. When combined with our two-stage fine-tuning pipeline, our method achieves improved common sense reasoning and state-of-the-art perplexity on the Writing Prompts (Fan et al., 2018) story generation dataset.
LakhNES: Improving multi-instrumental music generation with cross-domain pre-training
Jul 10, 2019
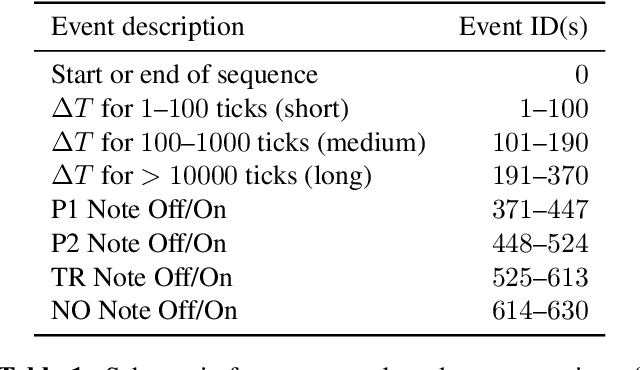
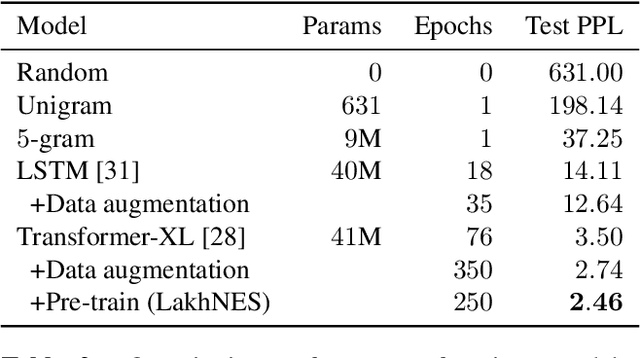
We are interested in the task of generating multi-instrumental music scores. The Transformer architecture has recently shown great promise for the task of piano score generation; here we adapt it to the multi-instrumental setting. Transformers are complex, high-dimensional language models which are capable of capturing long-term structure in sequence data, but require large amounts of data to fit. Their success on piano score generation is partially explained by the large volumes of symbolic data readily available for that domain. We leverage the recently-introduced NES-MDB dataset of four-instrument scores from an early video game sound synthesis chip (the NES), which we find to be well-suited to training with the Transformer architecture. To further improve the performance of our model, we propose a pre-training technique to leverage the information in a large collection of heterogeneous music, namely the Lakh MIDI dataset. Despite differences between the two corpora, we find that this transfer learning procedure improves both quantitative and qualitative performance for our primary task.
Deep-ESN: A Multiple Projection-encoding Hierarchical Reservoir Computing Framework
Nov 13, 2017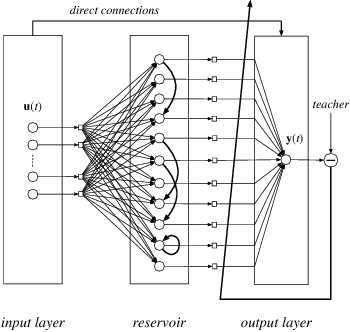
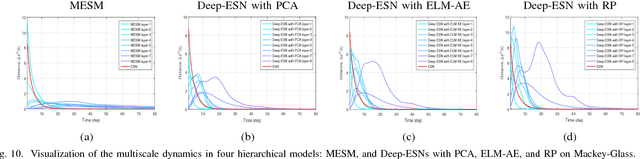
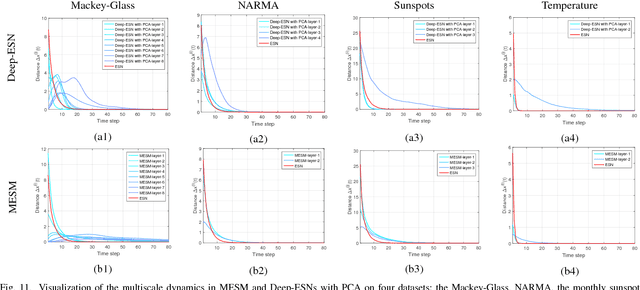
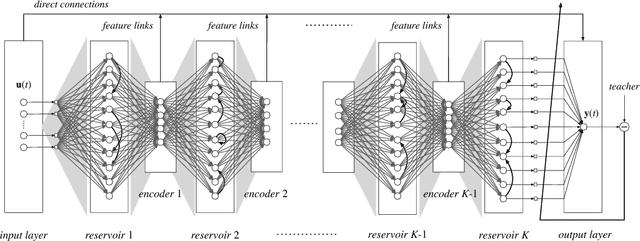
As an efficient recurrent neural network (RNN) model, reservoir computing (RC) models, such as Echo State Networks, have attracted widespread attention in the last decade. However, while they have had great success with time series data [1], [2], many time series have a multiscale structure, which a single-hidden-layer RC model may have difficulty capturing. In this paper, we propose a novel hierarchical reservoir computing framework we call Deep Echo State Networks (Deep-ESNs). The most distinctive feature of a Deep-ESN is its ability to deal with time series through hierarchical projections. Specifically, when an input time series is projected into the high-dimensional echo-state space of a reservoir, a subsequent encoding layer (e.g., a PCA, autoencoder, or a random projection) can project the echo-state representations into a lower-dimensional space. These low-dimensional representations can then be processed by another ESN. By using projection layers and encoding layers alternately in the hierarchical framework, a Deep-ESN can not only attenuate the effects of the collinearity problem in ESNs, but also fully take advantage of the temporal kernel property of ESNs to explore multiscale dynamics of time series. To fuse the multiscale representations obtained by each reservoir, we add connections from each encoding layer to the last output layer. Theoretical analyses prove that stability of a Deep-ESN is guaranteed by the echo state property (ESP), and the time complexity is equivalent to a conventional ESN. Experimental results on some artificial and real world time series demonstrate that Deep-ESNs can capture multiscale dynamics, and outperform both standard ESNs and previous hierarchical ESN-based models.
Belief Tree Search for Active Object Recognition
Aug 13, 2017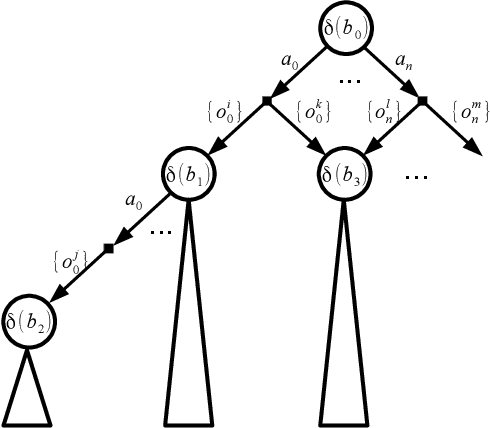
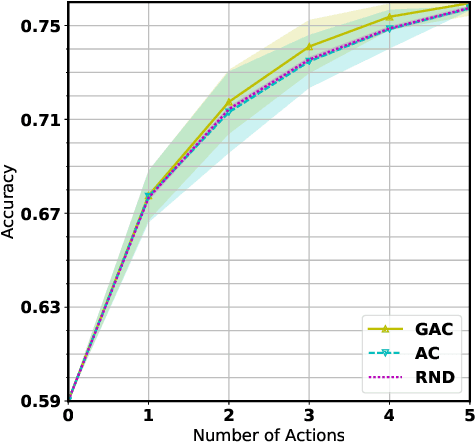
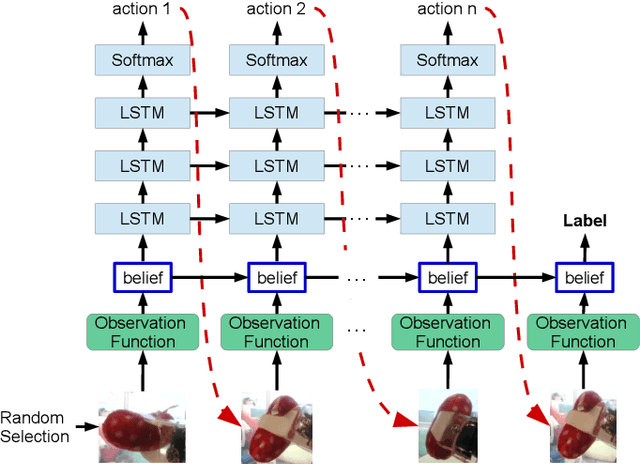
Active Object Recognition (AOR) has been approached as an unsupervised learning problem, in which optimal trajectories for object inspection are not known and are to be discovered by reducing label uncertainty measures or training with reinforcement learning. Such approaches have no guarantees of the quality of their solution. In this paper, we treat AOR as a Partially Observable Markov Decision Process (POMDP) and find near-optimal policies on training data using Belief Tree Search (BTS) on the corresponding belief Markov Decision Process (MDP). AOR then reduces to the problem of knowledge transfer from near-optimal policies on training set to the test set. We train a Long Short Term Memory (LSTM) network to predict the best next action on the training set rollouts. We sho that the proposed AOR method generalizes well to novel views of familiar objects and also to novel objects. We compare this supervised scheme against guided policy search, and find that the LSTM network reaches higher recognition accuracy compared to the guided policy method. We further look into optimizing the observation function to increase the total collected reward of optimal policy. In AOR, the observation function is known only approximately. We propose a gradient-based method update to this approximate observation function to increase the total reward of any policy. We show that by optimizing the observation function and retraining the supervised LSTM network, the AOR performance on the test set improves significantly.
Recognizing and Curating Photo Albums via Event-Specific Image Importance
Jul 19, 2017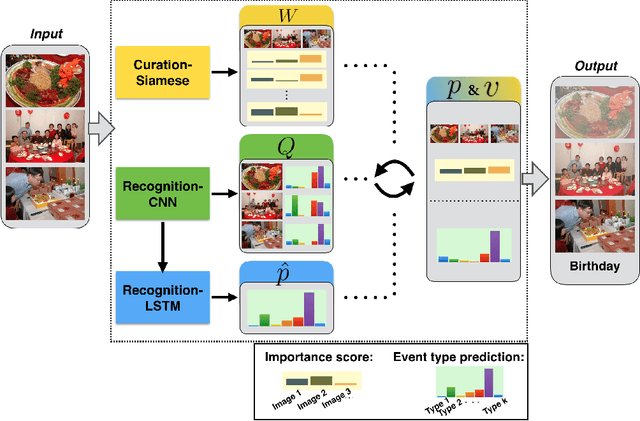
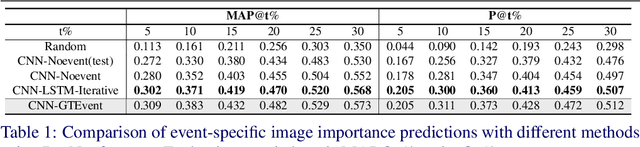
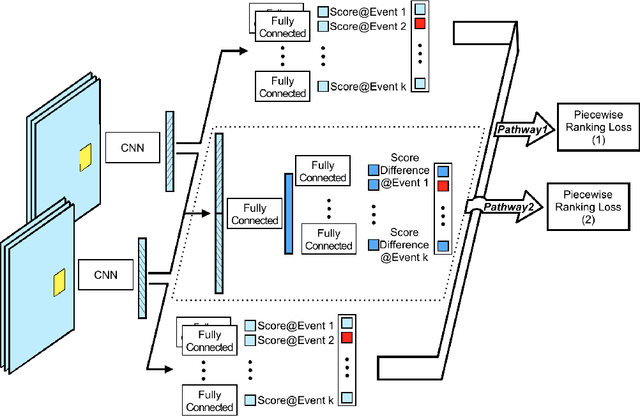
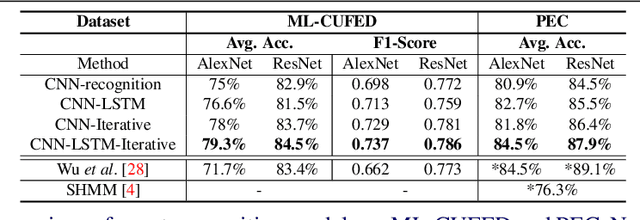
Automatic organization of personal photos is a problem with many real world ap- plications, and can be divided into two main tasks: recognizing the event type of the photo collection, and selecting interesting images from the collection. In this paper, we attempt to simultaneously solve both tasks: album-wise event recognition and image- wise importance prediction. We collected an album dataset with both event type labels and image importance labels, refined from an existing CUFED dataset. We propose a hybrid system consisting of three parts: A siamese network-based event-specific image importance prediction, a Convolutional Neural Network (CNN) that recognizes the event type, and a Long Short-Term Memory (LSTM)-based sequence level event recognizer. We propose an iterative updating procedure for event type and image importance score prediction. We experimentally verified that image importance score prediction and event type recognition can each help the performance of the other.
Hierarchical Cellular Automata for Visual Saliency
May 26, 2017
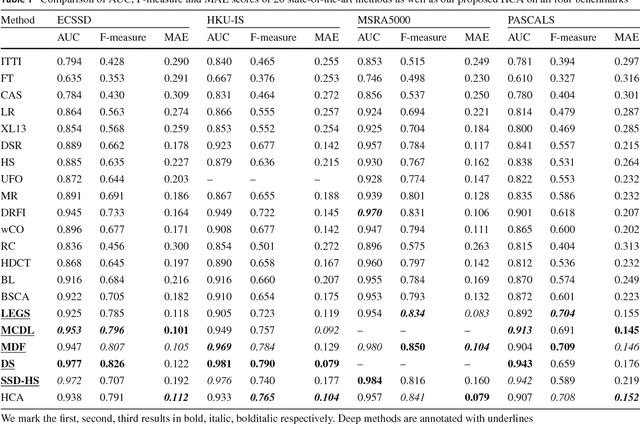
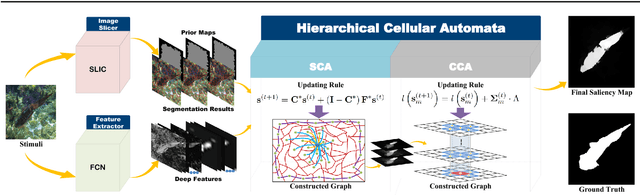

Saliency detection, finding the most important parts of an image, has become increasingly popular in computer vision. In this paper, we introduce Hierarchical Cellular Automata (HCA) -- a temporally evolving model to intelligently detect salient objects. HCA consists of two main components: Single-layer Cellular Automata (SCA) and Cuboid Cellular Automata (CCA). As an unsupervised propagation mechanism, Single-layer Cellular Automata can exploit the intrinsic relevance of similar regions through interactions with neighbors. Low-level image features as well as high-level semantic information extracted from deep neural networks are incorporated into the SCA to measure the correlation between different image patches. With these hierarchical deep features, an impact factor matrix and a coherence matrix are constructed to balance the influences on each cell's next state. The saliency values of all cells are iteratively updated according to a well-defined update rule. Furthermore, we propose CCA to integrate multiple saliency maps generated by SCA at different scales in a Bayesian framework. Therefore, single-layer propagation and multi-layer integration are jointly modeled in our unified HCA. Surprisingly, we find that the SCA can improve all existing methods that we applied it to, resulting in a similar precision level regardless of the original results. The CCA can act as an efficient pixel-wise aggregation algorithm that can integrate state-of-the-art methods, resulting in even better results. Extensive experiments on four challenging datasets demonstrate that the proposed algorithm outperforms state-of-the-art conventional methods and is competitive with deep learning based approaches.
Skeleton Key: Image Captioning by Skeleton-Attribute Decomposition
Apr 23, 2017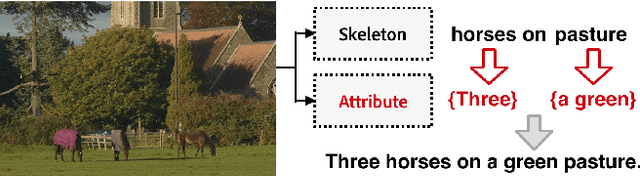

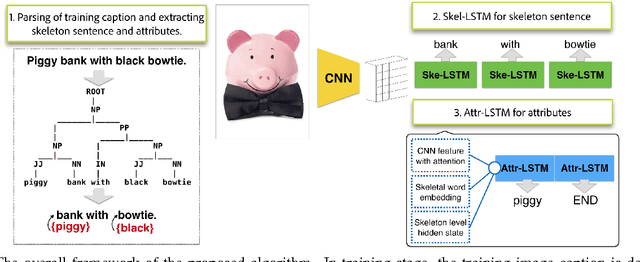
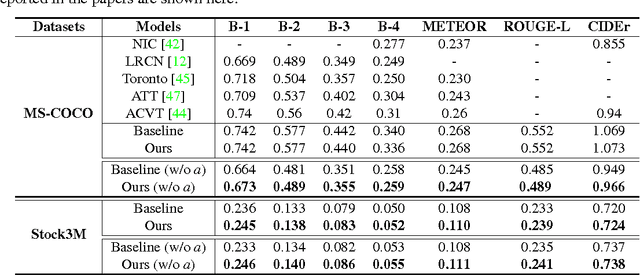
Recently, there has been a lot of interest in automatically generating descriptions for an image. Most existing language-model based approaches for this task learn to generate an image description word by word in its original word order. However, for humans, it is more natural to locate the objects and their relationships first, and then elaborate on each object, describing notable attributes. We present a coarse-to-fine method that decomposes the original image description into a skeleton sentence and its attributes, and generates the skeleton sentence and attribute phrases separately. By this decomposition, our method can generate more accurate and novel descriptions than the previous state-of-the-art. Experimental results on the MS-COCO and a larger scale Stock3M datasets show that our algorithm yields consistent improvements across different evaluation metrics, especially on the SPICE metric, which has much higher correlation with human ratings than the conventional metrics. Furthermore, our algorithm can generate descriptions with varied length, benefiting from the separate control of the skeleton and attributes. This enables image description generation that better accommodates user preferences.