 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Rationales in Visual Question Answering
Paper and Code
Apr 04, 2020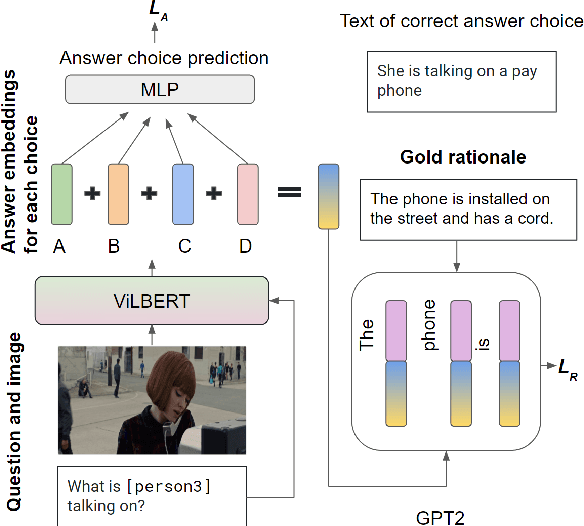
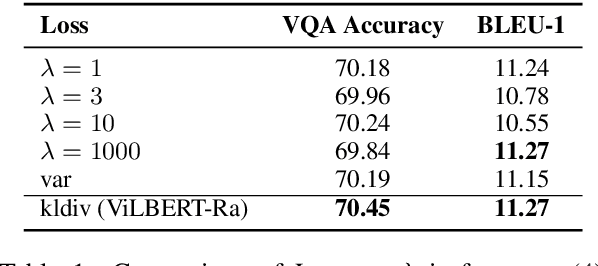


Despite recent advances in Visual QuestionAnswering (VQA), it remains a challenge todetermine how much success can be attributedto sound reasoning and comprehension ability.We seek to investigate this question by propos-ing a new task ofrationale generation. Es-sentially, we task a VQA model with generat-ing rationales for the answers it predicts. Weuse data from the Visual Commonsense Rea-soning (VCR) task, as it contains ground-truthrationales along with visual questions and an-swers. We first investigate commonsense un-derstanding in one of the leading VCR mod-els, ViLBERT, by generating rationales frompretrained weights using a state-of-the-art lan-guage model, GPT-2. Next, we seek to jointlytrain ViLBERT with GPT-2 in an end-to-endfashion with the dual task of predicting the an-swer in VQA and generating rationales. Weshow that this kind of training injects com-monsense understanding in the VQA modelthrough quantitative and qualitative evaluationmetrics