 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Space as a Scratchpad for Editable Text-to-Image Generation
Jan 21, 2026Recent progress in large language models (LLMs) has shown that reasoning improves when intermediate thoughts are externalized into explicit workspaces, such as chain-of-thought traces or tool-augmented reasoning. Yet, visual language models (VLMs) lack an analogous mechanism for spatial reasoning, limiting their ability to generate images that accurately reflect geometric relations, object identities, and compositional intent. We introduce the concept of a spatial scratchpad -- a 3D reasoning substrate that bridges linguistic intent and image synthesis. Given a text prompt, our framework parses subjects and background elements, instantiates them as editable 3D meshes, and employs agentic scene planning for placement, orientation, and viewpoint selection. The resulting 3D arrangement is rendered back into the image domain with identity-preserving cues, enabling the VLM to generate spatially consistent and visually coherent outputs. Unlike prior 2D layout-based methods, our approach supports intuitive 3D edits that propagate reliably into final images. Empirically, it achieves a 32% improvement in text alignment on GenAI-Bench, demonstrating the benefit of explicit 3D reasoning for precise, controllable image generation. Our results highlight a new paradigm for vision-language models that deliberate not only in language, but also in space. Code and visualizations at https://oindrilasaha.github.io/3DScratchpad/
Learning Continuous 3D Words for Text-to-Image Generation
Feb 13, 2024Current controls over diffusion models (e.g., through text or ControlNet) for image generation fall short in recognizing abstract, continuous attributes like illumination direction or non-rigid shape change. In this paper, we present an approach for allowing users of text-to-image models to have fine-grained control of several attributes in an image. We do this by engineering special sets of input tokens that can be transformed in a continuous manner -- we call them Continuous 3D Words. These attributes can, for example, be represented as sliders and applied jointly with text prompts for fine-grained control over image generation. Given only a single mesh and a rendering engine, we show that our approach can be adopted to provide continuous user control over several 3D-aware attributes, including time-of-day illumination, bird wing orientation, dollyzoom effect, and object poses. Our method is capable of conditioning image creation with multiple Continuous 3D Words and text descriptions simultaneously while adding no overhead to the generative process. Project Page: https://ttchengab.github.io/continuous_3d_words
3DMiner: Discovering Shapes from Large-Scale Unannotated Image Datasets
Oct 29, 2023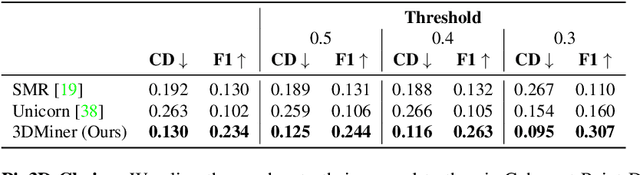
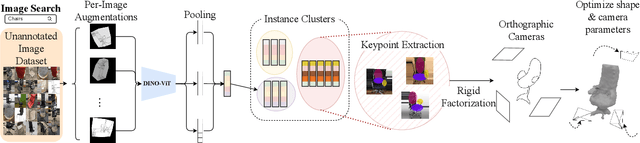
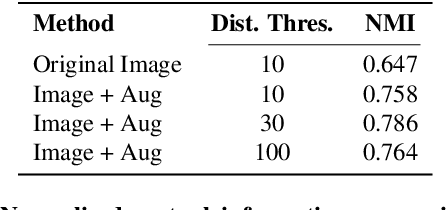

We present 3DMiner -- a pipeline for mining 3D shapes from challenging large-scale unannotated image datasets. Unlike other unsupervised 3D reconstruction methods, we assume that, within a large-enough dataset, there must exist images of objects with similar shapes but varying backgrounds, textures, and viewpoints. Our approach leverages the recent advances in learning self-supervised image representations to cluster images with geometrically similar shapes and find common image correspondences between them. We then exploit these correspondences to obtain rough camera estimates as initialization for bundle-adjustment. Finally, for every image cluster, we apply a progressive bundle-adjusting reconstruction method to learn a neural occupancy field representing the underlying shape. We show that this procedure is robust to several types of errors introduced in previous steps (e.g., wrong camera poses, images containing dissimilar shapes, etc.), allowing us to obtain shape and pose annotations for images in-the-wild. When using images from Pix3D chairs, our method is capable of producing significantly better results than state-of-the-art unsupervised 3D reconstruction techniques, both quantitatively and qualitatively. Furthermore, we show how 3DMiner can be applied to in-the-wild data by reconstructing shapes present in images from the LAION-5B dataset. Project Page: https://ttchengab.github.io/3dminerOfficial
Leveraging Monocular Disparity Estimation for Single-View Reconstruction
Jul 01, 2022
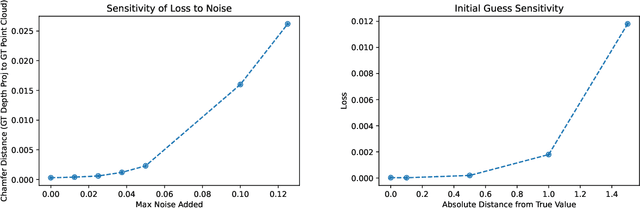
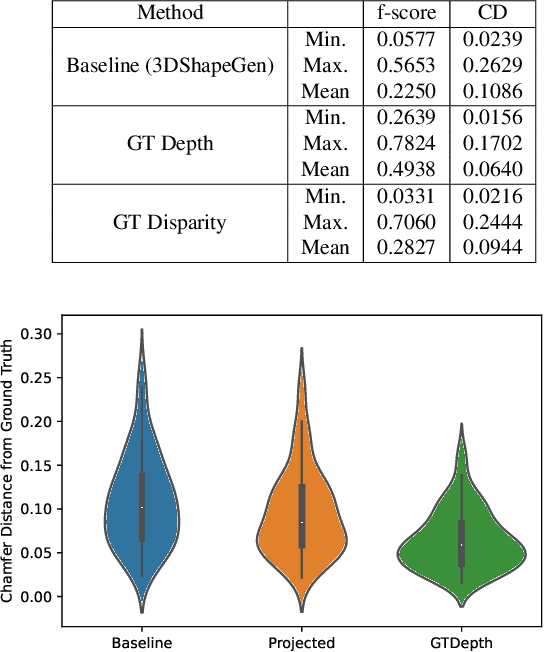
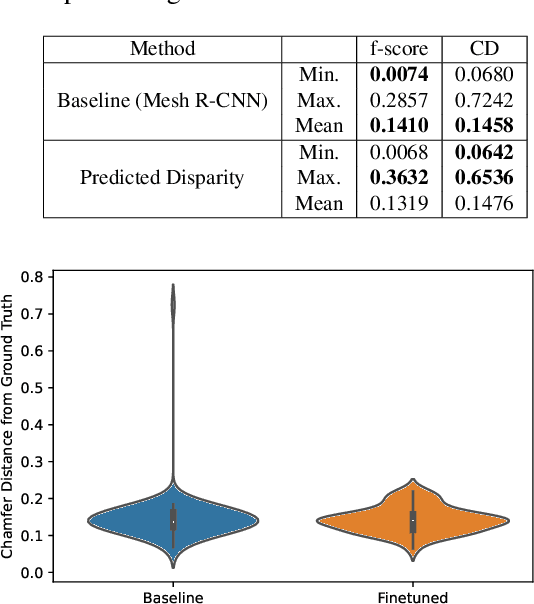
We present a fine-tuning method to improve the appearance of 3D geometries reconstructed from single images. We leverage advances in monocular depth estimation to obtain disparity maps and present a novel approach to transforming 2D normalized disparity maps into 3D point clouds by solving an optimization on the relevant camera parameters, After creating a 3D point cloud from disparity, we introduce a method to combine the new point cloud with existing information to form a more faithful and detailed final geometry. We demonstrate the efficacy of our approach with multiple experiments on both synthetic and real images.
ANISE: Assembly-based Neural Implicit Surface rEconstruction
May 27, 2022
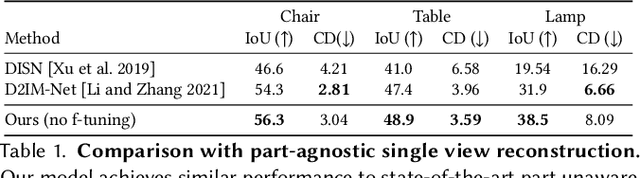

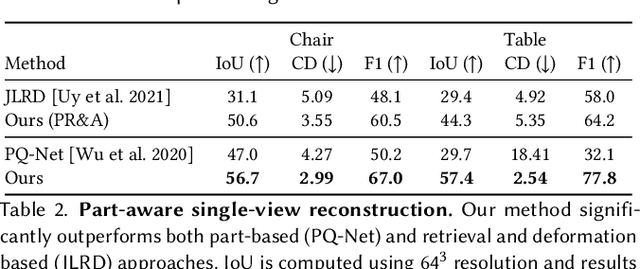
We present ANISE, a method that reconstructs a 3D shape from partial observations (images or sparse point clouds) using a part-aware neural implicit shape representation. It is formulated as an assembly of neural implicit functions, each representing a different shape part. In contrast to previous approaches, the prediction of this representation proceeds in a coarse-to-fine manner. Our network first predicts part transformations which are associated with part neural implicit functions conditioned on those transformations. The part implicit functions can then be combined into a single, coherent shape, enabling part-aware shape reconstructions from images and point clouds. Those reconstructions can be obtained in two ways: (i) by directly decoding combining the refined part implicit functions; or (ii) by using part latents to query similar parts in a part database and assembling them in a single shape. We demonstrate that, when performing reconstruction by decoding part representations into implicit functions, our method achieves state-of-the-art part-aware reconstruction results from both images and sparse point clouds. When reconstructing shapes by assembling parts queried from a dataset, our approach significantly outperforms traditional shape retrieval methods even when significantly restricting the size of the shape database. We present our results in well-known sparse point cloud reconstruction and single-view reconstruction benchmarks.
CPFN: Cascaded Primitive Fitting Networks for High-Resolution Point Clouds
Sep 06, 2021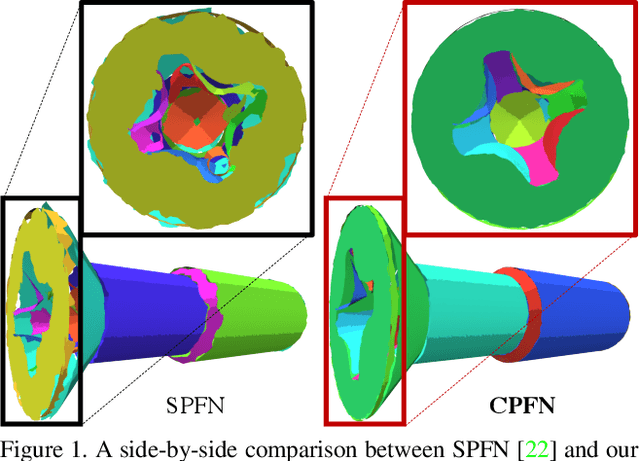
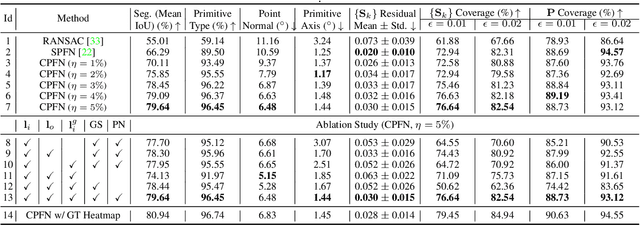
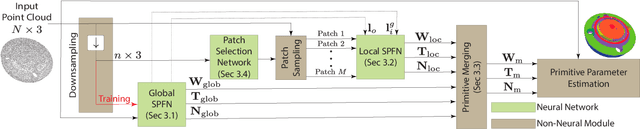
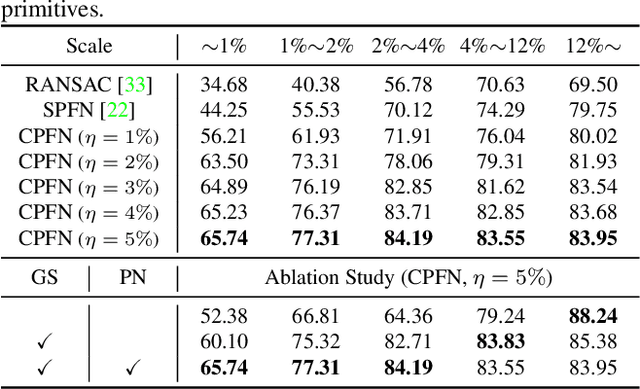
Representing human-made objects as a collection of base primitives has a long history in computer vision and reverse engineering. In the case of high-resolution point cloud scans, the challenge is to be able to detect both large primitives as well as those explaining the detailed parts. While the classical RANSAC approach requires case-specific parameter tuning, state-of-the-art networks are limited by memory consumption of their backbone modules such as PointNet++, and hence fail to detect the fine-scale primitives. We present Cascaded Primitive Fitting Networks (CPFN) that relies on an adaptive patch sampling network to assemble detection results of global and local primitive detection networks. As a key enabler, we present a merging formulation that dynamically aggregates the primitives across global and local scales. Our evaluation demonstrates that CPFN improves the state-of-the-art SPFN performance by 13-14% on high-resolution point cloud datasets and specifically improves the detection of fine-scale primitives by 20-22%.
* ICCV 2021: 15 pages, 8 figures
DeepMetaHandles: Learning Deformation Meta-Handles of 3D Meshes with Biharmonic Coordinates
Feb 18, 2021



We propose DeepMetaHandles, a 3D conditional generative model based on mesh deformation. Given a collection of 3D meshes of a category and their deformation handles (control points), our method learns a set of meta-handles for each shape, which are represented as combinations of the given handles. The disentangled meta-handles factorize all the plausible deformations of the shape, while each of them corresponds to an intuitive deformation. A new deformation can then be generated by sampling the coefficients of the meta-handles in a specific range. We employ biharmonic coordinates as the deformation function, which can smoothly propagate the control points' translations to the entire mesh. To avoid learning zero deformation as meta-handles, we incorporate a target-fitting module which deforms the input mesh to match a random target. To enhance deformations' plausibility, we employ a soft-rasterizer-based discriminator that projects the meshes to a 2D space. Our experiments demonstrate the superiority of the generated deformations as well as the interpretability and consistency of the learned meta-handles.
Learning Generative Models of Shape Handles
Apr 06, 2020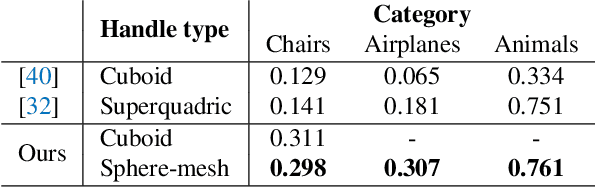
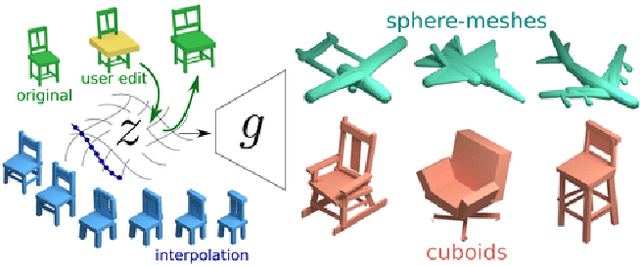

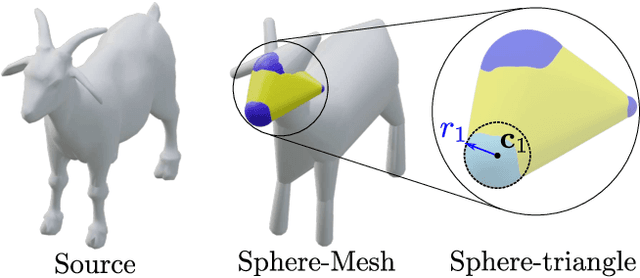
We present a generative model to synthesize 3D shapes as sets of handles -- lightweight proxies that approximate the original 3D shape -- for applications in interactive editing, shape parsing, and building compact 3D representations. Our model can generate handle sets with varying cardinality and different types of handles (Figure 1). Key to our approach is a deep architecture that predicts both the parameters and existence of shape handles, and a novel similarity measure that can easily accommodate different types of handles, such as cuboids or sphere-meshes. We leverage the recent advances in semantic 3D annotation as well as automatic shape summarizing techniques to supervise our approach. We show that the resulting shape representations are intuitive and achieve superior quality than previous state-of-the-art. Finally, we demonstrate how our method can be used in applications such as interactive shape editing, completion, and interpolation, leveraging the latent space learned by our model to guide these tasks. Project page: http://mgadelha.me/shapehandles.
LPaintB: Learning to Paint from Self-SupervisionLPaintB: Learning to Paint from Self-Supervision
Jun 17, 2019

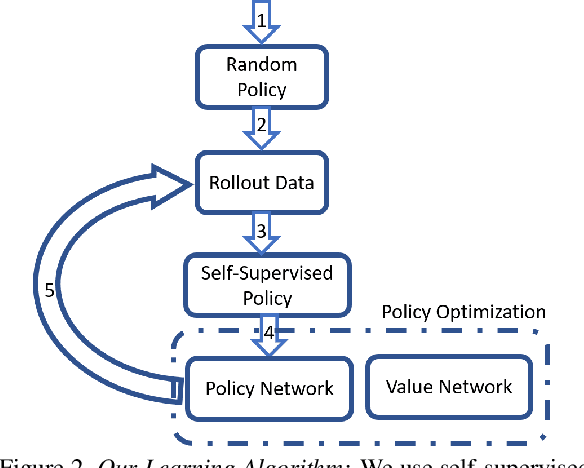

We present a novel reinforcement learning-based natural media painting algorithm. Our goal is to reproduce a reference image using brush strokes and we encode the objective through observations. Our formulation takes into account that the distribution of the reward in the action space is sparse and training a reinforcement learning algorithm from scratch can be difficult. We present an approach that combines self-supervised learning and reinforcement learning to effectively transfer negative samples into positive ones and change the reward distribution. We demonstrate the benefits of our painting agent to reproduce reference images with brush strokes. The training phase takes about one hour and the runtime algorithm takes about 30 seconds on a GTX1080 GPU reproducing a 1000x800 image with 20,000 strokes.
DISN: Deep Implicit Surface Network for High-quality Single-view 3D Reconstruction
May 26, 2019
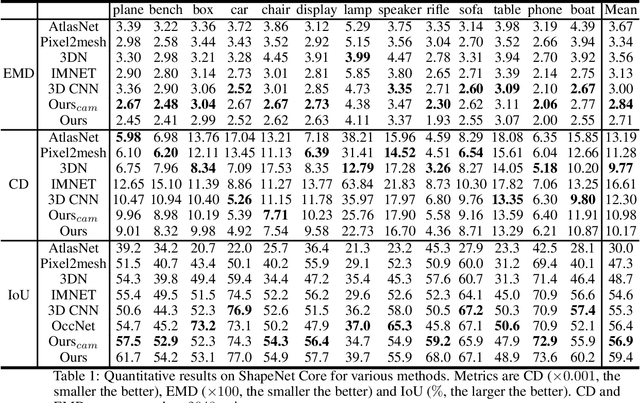


Reconstructing 3D shapes from single-view images has been a long-standing research problem and has attracted a lot of attention. In this paper, we present DISN, a Deep Implicit Surface Network that generates a high-quality 3D shape given an input image by predicting the underlying signed distance field. In addition to utilizing global image features, DISN also predicts the local image patch each 3D point sample projects onto and extracts local features from the patch. Combining global and local features significantly improves the accuracy of the predicted signed distance field. To the best of our knowledge, DISN is the first method that constantly captures details such as holes and thin structures present in 3D shapes from single-view images. DISN achieves state-of-the-art single-view reconstruction performance on a variety of shape categories reconstructed from both synthetic and real images. Code is available at github.com/laughtervv/DISN.