 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurboEdit: Instant text-based image editing
Aug 14, 2024
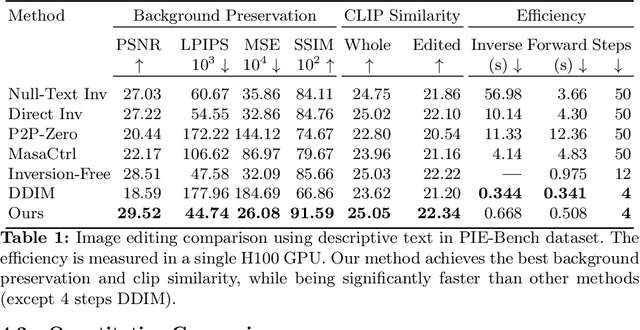
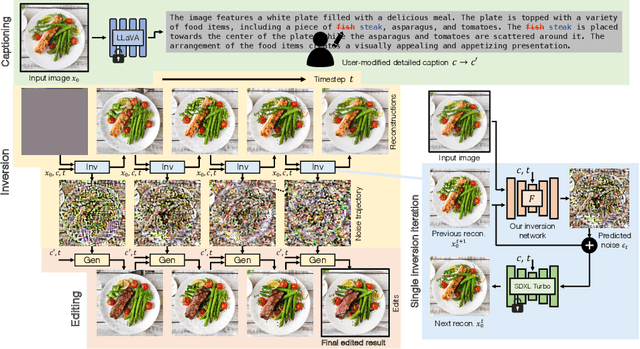

We address the challenges of precise image inversion and disentangled image editing in the context of few-step diffusion models. We introduce an encoder based iterative inversion technique. The inversion network is conditioned on the input image and the reconstructed image from the previous step, allowing for correction of the next reconstruction towards the input image. We demonstrate that disentangled controls can be easily achieved in the few-step diffusion model by conditioning on an (automatically generated) detailed text prompt. To manipulate the inverted image, we freeze the noise maps and modify one attribute in the text prompt (either manually or via instruction based editing driven by an LLM), resulting in the generation of a new image similar to the input image with only one attribute changed. It can further control the editing strength and accept instructive text prompt. Our approach facilitates realistic text-guided image edits in real-time, requiring only 8 number of functional evaluations (NFEs) in inversion (one-time cost) and 4 NFEs per edit. Our method is not only fast, but also significantly outperforms state-of-the-art multi-step diffusion editing techniques.
StreamHover: Livestream Transcript Summarization and Annotation
Sep 11, 2021
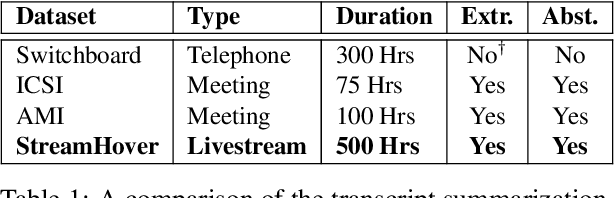


With the explosive growth of livestream broadcasting, there is an urgent need for new summarization technology that enables us to create a preview of streamed content and tap into this wealth of knowledge. However, the problem is nontrivial due to the informal nature of spoken language. Further, there has been a shortage of annotated datasets that are necessary for transcript summarization. In this paper, we present StreamHover, a framework for annotating and summarizing livestream transcripts. With a total of over 500 hours of videos annotated with both extractive and abstractive summaries, our benchmark dataset is significantly larger than currently existing annotated corpora. We explore a neural extractive summarization model that leverages vector-quantized variational autoencoder to learn latent vector representations of spoken utterances and identify salient utterances from the transcripts to form summaries. We show that our model generalizes better and improves performance over strong baselines. The results of this study provide an avenue for future research to improve summarization solutions for efficient browsing of livestreams.
LPaintB: Learning to Paint from Self-SupervisionLPaintB: Learning to Paint from Self-Supervision
Jun 17, 2019

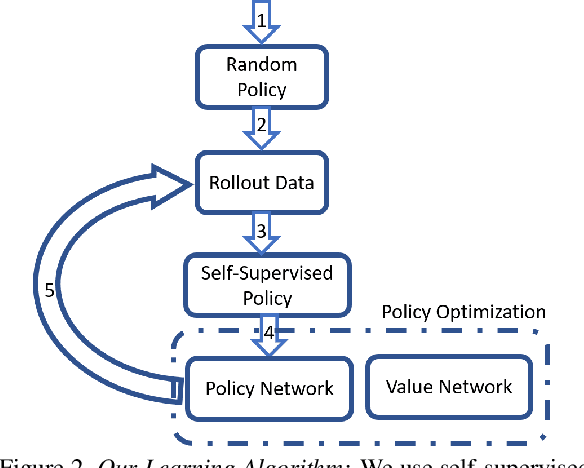

We present a novel reinforcement learning-based natural media painting algorithm. Our goal is to reproduce a reference image using brush strokes and we encode the objective through observations. Our formulation takes into account that the distribution of the reward in the action space is sparse and training a reinforcement learning algorithm from scratch can be difficult. We present an approach that combines self-supervised learning and reinforcement learning to effectively transfer negative samples into positive ones and change the reward distribution. We demonstrate the benefits of our painting agent to reproduce reference images with brush strokes. The training phase takes about one hour and the runtime algorithm takes about 30 seconds on a GTX1080 GPU reproducing a 1000x800 image with 20,000 strokes.
PaintBot: A Reinforcement Learning Approach for Natural Media Painting
Apr 03, 2019


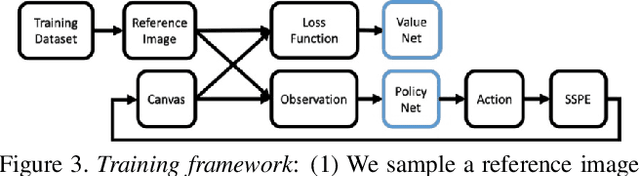
We propose a new automated digital painting framework, based on a painting agent trained through reinforcement learning. To synthesize an image, the agent selects a sequence of continuous-valued actions representing primitive painting strokes, which are accumulated on a digital canvas. Action selection is guided by a given reference image, which the agent attempts to replicate subject to the limitations of the action space and the agent's learned policy. The painting agent policy is determined using a variant of proximal policy optimization reinforcement learning. During training, our agent is presented with patches sampled from an ensemble of reference images. To accelerate training convergence, we adopt a curriculum learning strategy, whereby reference patches are sampled according to how challenging they are using the current policy. We experiment with differing loss functions, including pixel-wise and perceptual loss, which have consequent differing effects on the learned policy. We demonstrate that our painting agent can learn an effective policy with a high dimensional continuous action space comprising pen pressure, width, tilt, and color, for a variety of painting styles. Through a coarse-to-fine refinement process our agent can paint arbitrarily complex images in the desired style.
Hotels-50K: A Global Hotel Recognition Dataset
Jan 26, 2019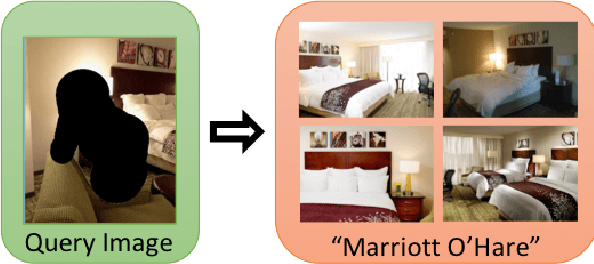
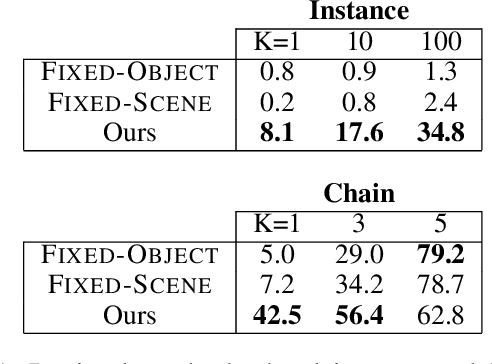


Recognizing a hotel from an image of a hotel room is important for human trafficking investigations. Images directly link victims to places and can help verify where victims have been trafficked, and where their traffickers might move them or others in the future. Recognizing the hotel from images is challenging because of low image quality, uncommon camera perspectives, large occlusions (often the victim), and the similarity of objects (e.g., furniture, art, bedding) across different hotel rooms. To support efforts towards this hotel recognition task, we have curated a dataset of over 1 million annotated hotel room images from 50,000 hotels. These images include professionally captured photographs from travel websites and crowd-sourced images from a mobile application, which are more similar to the types of images analyzed in real-world investigations. We present a baseline approach based on a standard network architecture and a collection of data-augmentation approaches tuned to this problem domain.
Learning to Sketch with Deep Q Networks and Demonstrated Strokes
Oct 14, 2018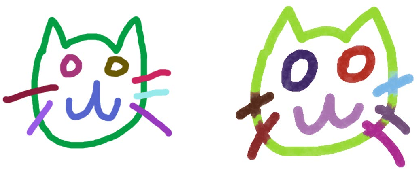


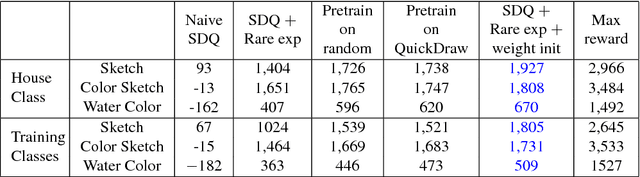
Doodling is a useful and common intelligent skill that people can learn and master. In this work, we propose a two-stage learning framework to teach a machine to doodle in a simulated painting environment via Stroke Demonstration and deep Q-learning (SDQ). The developed system, Doodle-SDQ, generates a sequence of pen actions to reproduce a reference drawing and mimics the behavior of human painters. In the first stage, it learns to draw simple strokes by imitating in supervised fashion from a set of strokeaction pairs collected from artist paintings. In the second stage, it is challenged to draw real and more complex doodles without ground truth actions; thus, it is trained with Qlearning. Our experiments confirm that (1) doodling can be learned without direct stepby- step action supervision and (2) pretraining with stroke demonstration via supervised learning is important to improve performance. We further show that Doodle-SDQ is effective at producing plausible drawings in different media types, including sketch and watercolor.
Top-down Neural Attention by Excitation Backprop
Aug 01, 2016
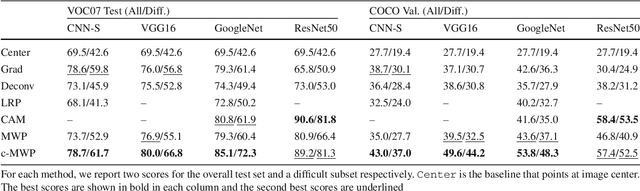
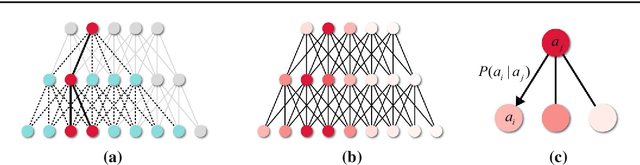

We aim to model the top-down attention of a Convolutional Neural Network (CNN) classifier for generating task-specific attention maps. Inspired by a top-down human visual attention model, we propose a new backpropagation scheme, called Excitation Backprop, to pass along top-down signals downwards in the network hierarchy via a probabilistic Winner-Take-All process. Furthermore, we introduce the concept of contrastive attention to make the top-down attention maps more discriminative. In experiments, we demonstrate the accuracy and generalizability of our method in weakly supervised localization tasks on the MS COCO, PASCAL VOC07 and ImageNet datasets. The usefulness of our method is further validated in the text-to-region association task. On the Flickr30k Entities dataset, we achieve promising performance in phrase localization by leveraging the top-down attention of a CNN model that has been trained on weakly labeled web images.
DeepFont: Identify Your Font from An Image
Jul 12, 2015
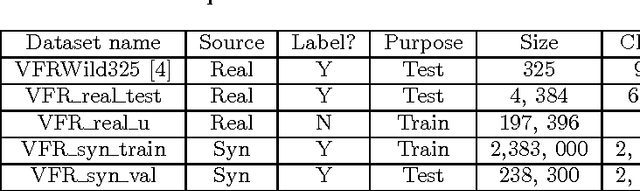


As font is one of the core design concepts, automatic font identification and similar font suggestion from an image or photo has been on the wish list of many designers. We study the Visual Font Recognition (VFR) problem, and advance the state-of-the-art remarkably by developing the DeepFont system. First of all, we build up the first available large-scale VFR dataset, named AdobeVFR, consisting of both labeled synthetic data and partially labeled real-world data. Next, to combat the domain mismatch between available training and testing data, we introduce a Convolutional Neural Network (CNN) decomposition approach, using a domain adaptation technique based on a Stacked Convolutional Auto-Encoder (SCAE) that exploits a large corpus of unlabeled real-world text images combined with synthetic data preprocessed in a specific way. Moreover, we study a novel learning-based model compression approach, in order to reduce the DeepFont model size without sacrificing its performance. The DeepFont system achieves an accuracy of higher than 80% (top-5) on our collected dataset, and also produces a good font similarity measure for font selection and suggestion. We also achieve around 6 times compression of the model without any visible loss of recognition accuracy.
Decomposition-Based Domain Adaptation for Real-World Font Recognition
Apr 01, 2015

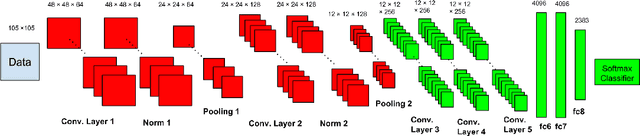

We present a domain adaption framework to address a domain mismatch between synthetic training and real-world testing data. We demonstrate our method on a challenging fine-grain classification problem: recognizing a font style from an image of text. In this task, it is very easy to generate lots of rendered font examples but very hard to obtain real-world labeled images. This real-to-synthetic domain gap caused poor generalization to new real data in previous font recognition methods (Chen et al. (2014)). In this paper, we introduce a Convolutional Neural Network decomposition approach, leveraging a large training corpus of synthetic data to obtain effective features for classification. This is done using an adaptation technique based on a Stacked Convolutional Auto-Encoder that exploits a large collection of unlabeled real-world text images combined with synthetic data preprocessed in a specific way. The proposed DeepFont method achieves an accuracy of higher than 80% (top-5) on a new large labeled real-world dataset we collected.
Real-World Font Recognition Using Deep Network and Domain Adaptation
Mar 31, 2015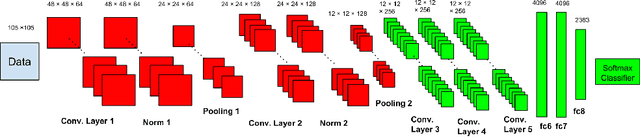
We address a challenging fine-grain classification problem: recognizing a font style from an image of text. In this task, it is very easy to generate lots of rendered font examples but very hard to obtain real-world labeled images. This real-to-synthetic domain gap caused poor generalization to new real data in previous methods (Chen et al. (2014)). In this paper, we refer to Convolutional Neural Networks, and use an adaptation technique based on a Stacked Convolutional Auto-Encoder that exploits unlabeled real-world images combined with synthetic data. The proposed method achieves an accuracy of higher than 80% (top-5) on a real-world dataset.