 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecise Representation Model of SAR Saturated Interference: Mechanism and Verification
Jul 09, 2025Synthetic Aperture Radar (SAR) is highly susceptible to Radio Frequency Interference (RFI). Due to the performance limitations of components such as gain controllers and analog-to-digital converters in SAR receivers, high-power interference can easily cause saturation of the SAR receiver, resulting in nonlinear distortion of the interfered echoes, which are distorted in both the time domain and frequency domain. Some scholars have analyzed the impact of SAR receiver saturation on target echoes through simulations. However, the saturation function has non-smooth characteristics, making it difficult to conduct accurate analysis using traditional analytical methods. Current related studies have approximated and analyzed the saturation function based on the hyperbolic tangent function, but there are approximation errors. Therefore, this paper proposes a saturation interference analysis model based on Bessel functions, and verifies the accuracy of the proposed saturation interference analysis model by simulating and comparing it with the traditional saturation model based on smooth function approximation. This model can provide certain guidance for further work such as saturation interference suppression.
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Jun 10, 2025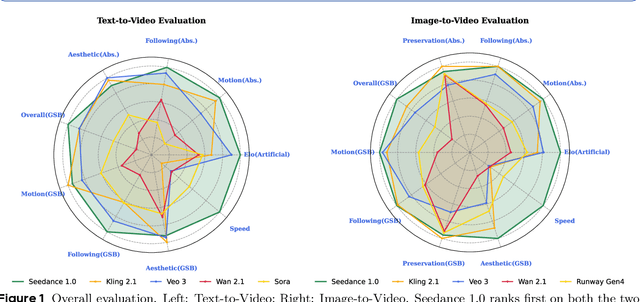
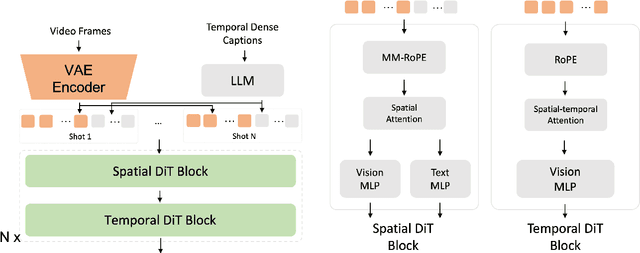
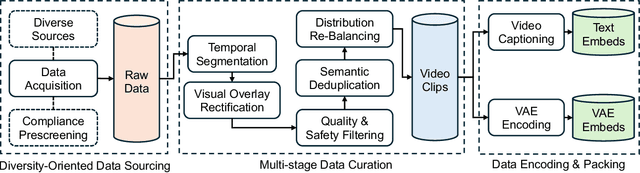
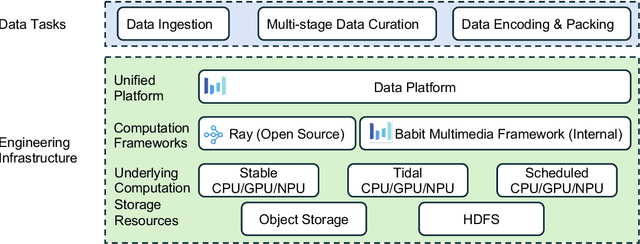
Notable breakthroughs in diffusion modeling have propelled rapid improvements in video generation, yet current foundational model still face critical challenges in simultaneously balancing prompt following, motion plausibility, and visual quality. In this report, we introduce Seedance 1.0, a high-performance and inference-efficient video foundation generation model that integrates several core technical improvements: (i) multi-source data curation augmented with precision and meaningful video captioning, enabling comprehensive learning across diverse scenarios; (ii) an efficient architecture design with proposed training paradigm, which allows for natively supporting multi-shot generation and jointly learning of both text-to-video and image-to-video tasks. (iii) carefully-optimized post-training approaches leveraging fine-grained supervised fine-tuning, and video-specific RLHF with multi-dimensional reward mechanisms for comprehensive performance improvements; (iv) excellent model acceleration achieving ~10x inference speedup through multi-stage distillation strategies and system-level optimizations. Seedance 1.0 can generate a 5-second video at 1080p resolution only with 41.4 seconds (NVIDIA-L20). Compared to state-of-the-art video generation models, Seedance 1.0 stands out with high-quality and fast video generation having superior spatiotemporal fluidity with structural stability, precise instruction adherence in complex multi-subject contexts, native multi-shot narrative coherence with consistent subject representation.
SeedEdit 3.0: Fast and High-Quality Generative Image Editing
Jun 06, 2025We introduce SeedEdit 3.0, in companion with our T2I model Seedream 3.0, which significantly improves over our previous SeedEdit versions in both aspects of edit instruction following and image content (e.g., ID/IP) preservation on real image inputs. Additional to model upgrading with T2I, in this report, we present several key improvements. First, we develop an enhanced data curation pipeline with a meta-info paradigm and meta-info embedding strategy that help mix images from multiple data sources. This allows us to scale editing data effectively, and meta information is helpfult to connect VLM with diffusion model more closely. Second, we introduce a joint learning pipeline for computing a diffusion loss and reward losses. Finally, we evaluate SeedEdit 3.0 on our testing benchmarks, for real/synthetic image editing, where it achieves a best trade-off between multiple aspects, yielding a high usability rate of 56.1%, compared to SeedEdit 1.6 (38.4%), GPT4o (37.1%) and Gemini 2.0 (30.3%).
Seedream 3.0 Technical Report
Apr 16, 2025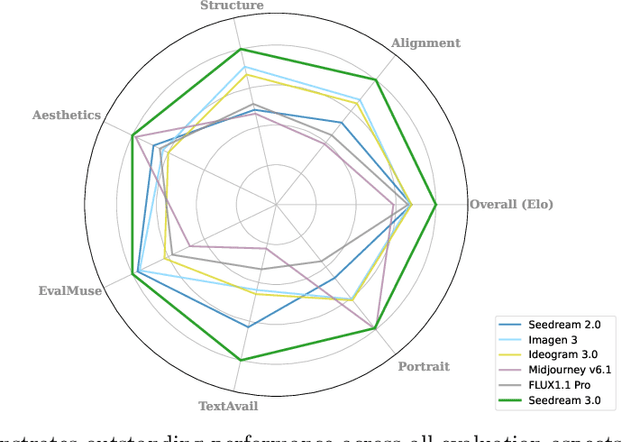


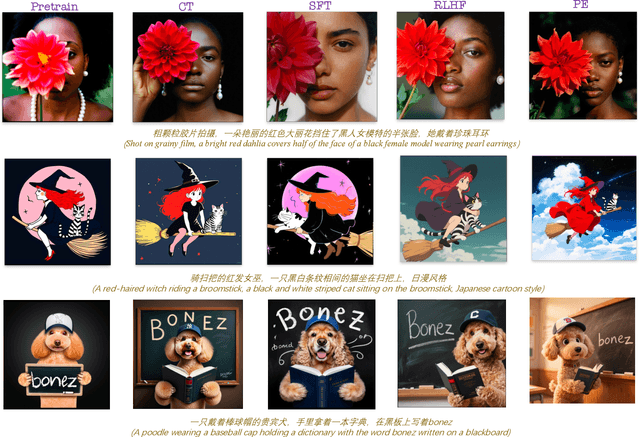
We present Seedream 3.0, a high-performance Chinese-English bilingual image generation foundation model. We develop several technical improvements to address existing challenges in Seedream 2.0, including alignment with complicated prompts, fine-grained typography generation, suboptimal visual aesthetics and fidelity, and limited image resolutions. Specifically, the advancements of Seedream 3.0 stem from improvements across the entire pipeline, from data construction to model deployment. At the data stratum, we double the dataset using a defect-aware training paradigm and a dual-axis collaborative data-sampling framework. Furthermore, we adopt several effective techniques such as mixed-resolution training, cross-modality RoPE, representation alignment loss, and resolution-aware timestep sampling in the pre-training phase. During the post-training stage, we utilize diversified aesthetic captions in SFT, and a VLM-based reward model with scaling, thereby achieving outputs that well align with human preferences. Furthermore, Seedream 3.0 pioneers a novel acceleration paradigm. By employing consistent noise expectation and importance-aware timestep sampling, we achieve a 4 to 8 times speedup while maintaining image quality. Seedream 3.0 demonstrates significant improvements over Seedream 2.0: it enhances overall capabilities, in particular for text-rendering in complicated Chinese characters which is important to professional typography generation. In addition, it provides native high-resolution output (up to 2K), allowing it to generate images with high visual quality.
Seaweed-7B: Cost-Effective Training of Video Generation Foundation Model
Apr 11, 2025
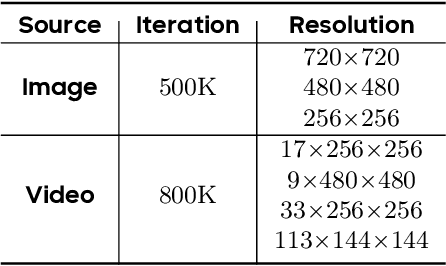
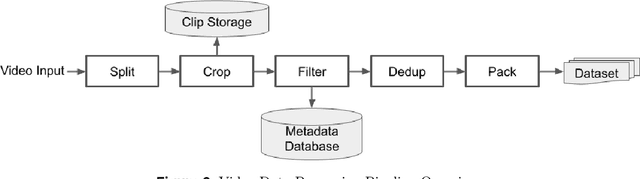

This technical report presents a cost-efficient strategy for training a video generation foundation model. We present a mid-sized research model with approximately 7 billion parameters (7B) called Seaweed-7B trained from scratch using 665,000 H100 GPU hours. Despite being trained with moderate computational resources, Seaweed-7B demonstrates highly competitive performance compared to contemporary video generation models of much larger size. Design choices are especially crucial in a resource-constrained setting. This technical report highlights the key design decisions that enhance the performance of the medium-sized diffusion model. Empirically, we make two observations: (1) Seaweed-7B achieves performance comparable to, or even surpasses, larger models trained on substantially greater GPU resources, and (2) our model, which exhibits strong generalization ability, can be effectively adapted across a wide range of downstream applications either by lightweight fine-tuning or continue training. See the project page at https://seaweed.video/
Seedream 2.0: A Native Chinese-English Bilingual Image Generation Foundation Model
Mar 10, 2025Rapid advancement of diffusion models has catalyzed remarkable progress in the field of image generation. However, prevalent models such as Flux, SD3.5 and Midjourney, still grapple with issues like model bias, limited text rendering capabilities, and insufficient understanding of Chinese cultural nuances. To address these limitations, we present Seedream 2.0, a native Chinese-English bilingual image generation foundation model that excels across diverse dimensions, which adeptly manages text prompt in both Chinese and English, supporting bilingual image generation and text rendering. We develop a powerful data system that facilitates knowledge integration, and a caption system that balances the accuracy and richness for image description. Particularly, Seedream is integrated with a self-developed bilingual large language model as a text encoder, allowing it to learn native knowledge directly from massive data. This enable it to generate high-fidelity images with accurate cultural nuances and aesthetic expressions described in either Chinese or English. Beside, Glyph-Aligned ByT5 is applied for flexible character-level text rendering, while a Scaled ROPE generalizes well to untrained resolutions. Multi-phase post-training optimizations, including SFT and RLHF iterations, further improve the overall capability. Through extensive experimentation, we demonstrate that Seedream 2.0 achieves state-of-the-art performance across multiple aspects, including prompt-following, aesthetics, text rendering, and structural correctness. Furthermore, Seedream 2.0 has been optimized through multiple RLHF iterations to closely align its output with human preferences, as revealed by its outstanding ELO score. In addition, it can be readily adapted to an instruction-based image editing model, such as SeedEdit, with strong editing capability that balances instruction-following and image consistency.
Dressing in the Wild by Watching Dance Videos
Mar 29, 2022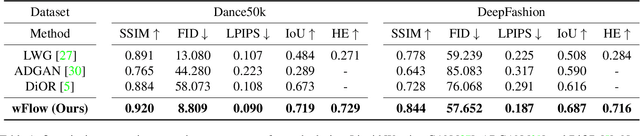
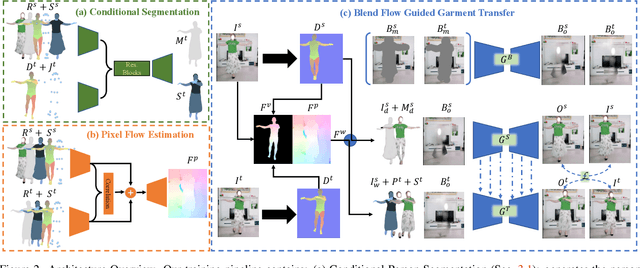
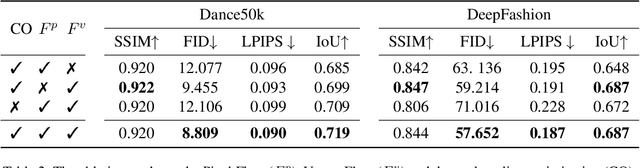
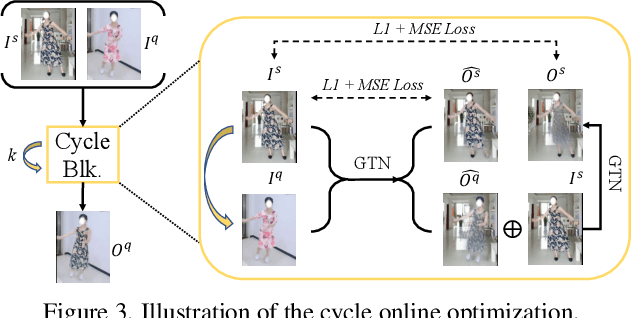
While significant progress has been made in garment transfer, one of the most applicable directions of human-centric image generation, existing works overlook the in-the-wild imagery, presenting severe garment-person misalignment as well as noticeable degradation in fine texture details. This paper, therefore, attends to virtual try-on in real-world scenes and brings essential improvements in authenticity and naturalness especially for loose garment (e.g., skirts, formal dresses), challenging poses (e.g., cross arms, bent legs), and cluttered backgrounds. Specifically, we find that the pixel flow excels at handling loose garments whereas the vertex flow is preferred for hard poses, and by combining their advantages we propose a novel generative network called wFlow that can effectively push up garment transfer to in-the-wild context. Moreover, former approaches require paired images for training. Instead, we cut down the laboriousness by working on a newly constructed large-scale video dataset named Dance50k with self-supervised cross-frame training and an online cycle optimization. The proposed Dance50k can boost real-world virtual dressing by covering a wide variety of garments under dancing poses. Extensive experiments demonstrate the superiority of our wFlow in generating realistic garment transfer results for in-the-wild images without resorting to expensive paired datasets.
Online Multi-Granularity Distillation for GAN Compression
Aug 26, 2021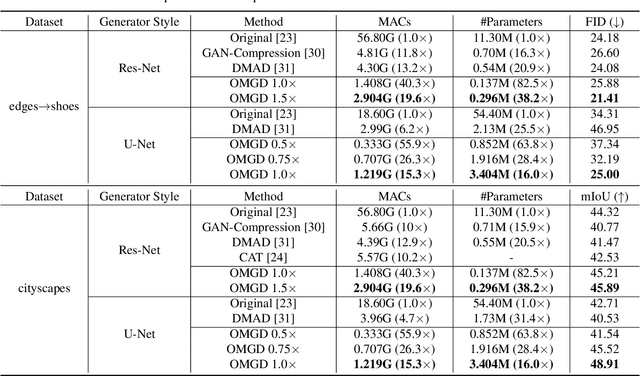
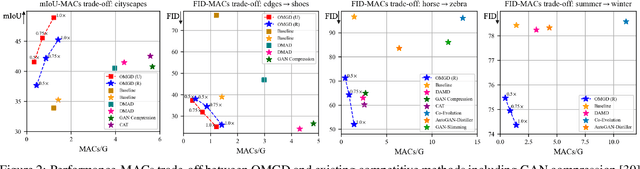
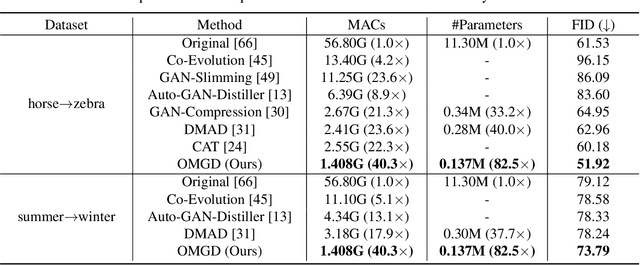
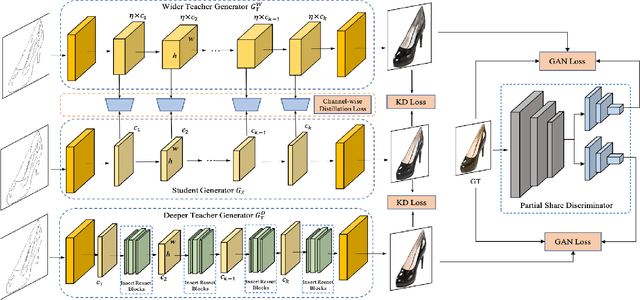
Generative Adversarial Networks (GANs) have witnessed prevailing success in yielding outstanding images, however, they are burdensome to deploy on resource-constrained devices due to ponderous computational costs and hulking memory usage. Although recent efforts on compressing GANs have acquired remarkable results, they still exist potential model redundancies and can be further compressed. To solve this issue, we propose a novel online multi-granularity distillation (OMGD) scheme to obtain lightweight GANs, which contributes to generating high-fidelity images with low computational demands. We offer the first attempt to popularize single-stage online distillation for GAN-oriented compression, where the progressively promoted teacher generator helps to refine the discriminator-free based student generator. Complementary teacher generators and network layers provide comprehensive and multi-granularity concepts to enhance visual fidelity from diverse dimensions. Experimental results on four benchmark datasets demonstrate that OMGD successes to compress 40x MACs and 82.5X parameters on Pix2Pix and CycleGAN, without loss of image quality. It reveals that OMGD provides a feasible solution for the deployment of real-time image translation on resource-constrained devices. Our code and models are made public at: https://github.com/bytedance/OMGD.
One Backward from Ten Forward, Subsampling for Large-Scale Deep Learning
Apr 27, 2021
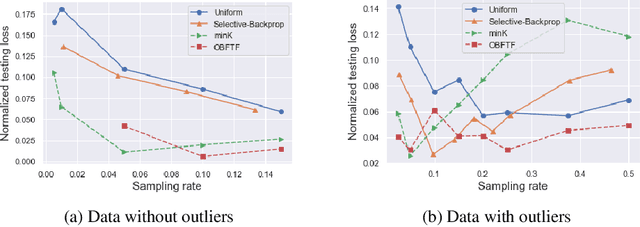

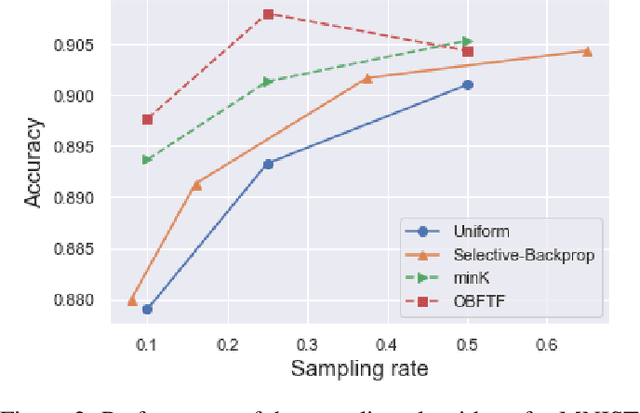
Deep learning models in large-scale machine learning systems are often continuously trained with enormous data from production environments. The sheer volume of streaming training data poses a significant challenge to real-time training subsystems and ad-hoc sampling is the standard practice. Our key insight is that these deployed ML systems continuously perform forward passes on data instances during inference, but ad-hoc sampling does not take advantage of this substantial computational effort. Therefore, we propose to record a constant amount of information per instance from these forward passes. The extra information measurably improves the selection of which data instances should participate in forward and backward passes. A novel optimization framework is proposed to analyze this problem and we provide an efficient approximation algorithm under the framework of Mini-batch gradient descent as a practical solution. We also demonstrate the effectiveness of our framework and algorithm on several large-scale classification and regression tasks, when compared with competitive baselines widely used in industry.
Human Motion Transfer from Poses in the Wild
Apr 07, 2020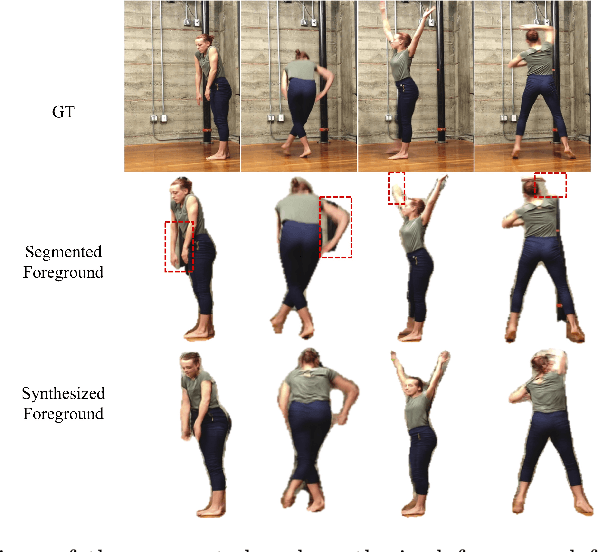
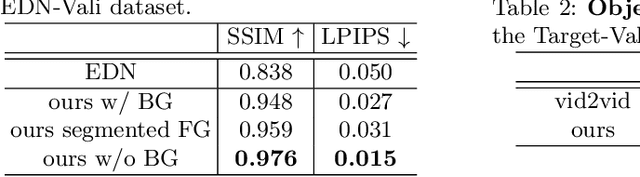
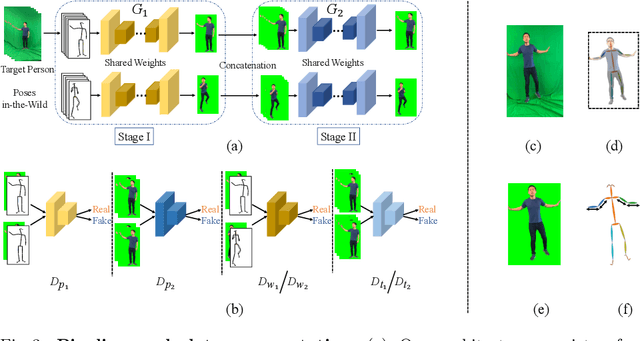

In this paper, we tackle the problem of human motion transfer, where we synthesize novel motion video for a target person that imitates the movement from a reference video. It is a video-to-video translation task in which the estimated poses are used to bridge two domains. Despite substantial progress on the topic, there exist several problems with the previous methods. First, there is a domain gap between training and testing pose sequences--the model is tested on poses it has not seen during training, such as difficult dancing moves. Furthermore, pose detection errors are inevitable, making the job of the generator harder. Finally, generating realistic pixels from sparse poses is challenging in a single step. To address these challenges, we introduce a novel pose-to-video translation framework for generating high-quality videos that are temporally coherent even for in-the-wild pose sequences unseen during training. We propose a pose augmentation method to minimize the training-test gap, a unified paired and unpaired learning strategy to improve the robustness to detection errors, and two-stage network architecture to achieve superior texture quality. To further boost research on the topic, we build two human motion datasets. Finally, we show the superiority of our approach over the state-of-the-art studies through extensive experiments and evaluations on different datasets.