 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Topology-Preserving Graph Coarsening with Graph Collapse
Jan 30, 2026Graph coarsening reduces the size of a graph while preserving certain properties. Most existing methods preserve either spectral or spatial characteristics. Recent research has shown that preserving topological features helps maintain the predictive performance of graph neural networks (GNNs) trained on the coarsened graph but suffers from exponential time complexity. To address these problems, we propose Scalable Topology-Preserving Graph Coarsening (STPGC) by introducing the concepts of graph strong collapse and graph edge collapse extended from algebraic topology. STPGC comprises three new algorithms, GStrongCollapse, GEdgeCollapse, and NeighborhoodConing based on these two concepts, which eliminate dominated nodes and edges while rigorously preserving topological features. We further prove that STPGC preserves the GNN receptive field and develop approximate algorithms to accelerate GNN training. Experiments on node classification with GNNs demonstrate the efficiency and effectiveness of STPGC.
STFM: A Spatio-Temporal Information Fusion Model Based on Phase Space Reconstruction for Sea Surface Temperature Prediction
Apr 23, 2025



The sea surface temperature (SST), a key environmental parameter, is crucial to optimizing production planning, making its accurate prediction a vital research topic. However, the inherent nonlinearity of the marine dynamic system presents significant challenges. Current forecasting methods mainly include physics-based numerical simulations and data-driven machine learning approaches. The former, while describing SST evolution through differential equations, suffers from high computational complexity and limited applicability, whereas the latter, despite its computational benefits, requires large datasets and faces interpretability challenges. This study presents a prediction framework based solely on data-driven techniques. Using phase space reconstruction, we construct initial-delay attractor pairs with a mathematical homeomorphism and design a Spatio-Temporal Fusion Mapping (STFM) to uncover their intrinsic connections. Unlike conventional models, our method captures SST dynamics efficiently through phase space reconstruction and achieves high prediction accuracy with minimal training data in comparative tests
ScaDyG:A New Paradigm for Large-scale Dynamic Graph Learning
Jan 27, 2025Dynamic graphs (DGs), which capture time-evolving relationships between graph entities, have widespread real-world applications. To efficiently encode DGs for downstream tasks, most dynamic graph neural networks follow the traditional message-passing mechanism and extend it with time-based techniques. Despite their effectiveness, the growth of historical interactions introduces significant scalability issues, particularly in industry scenarios. To address this limitation, we propose ScaDyG, with the core idea of designing a time-aware scalable learning paradigm as follows: 1) Time-aware Topology Reformulation: ScaDyG first segments historical interactions into time steps (intra and inter) based on dynamic modeling, enabling weight-free and time-aware graph propagation within pre-processing. 2) Dynamic Temporal Encoding: To further achieve fine-grained graph propagation within time steps, ScaDyG integrates temporal encoding through a combination of exponential functions in a scalable manner. 3) Hypernetwork-driven Message Aggregation: After obtaining the propagated features (i.e., messages), ScaDyG utilizes hypernetwork to analyze historical dependencies, implementing node-wise representation by an adaptive temporal fusion. Extensive experiments on 12 datasets demonstrate that ScaDyG performs comparably well or even outperforms other SOTA methods in both node and link-level downstream tasks, with fewer learnable parameters and higher efficiency.
SP-SLAM: Neural Real-Time Dense SLAM With Scene Priors
Jan 11, 2025Neural implicit representations have recently shown promising progress in dense Simultaneous Localization And Mapping (SLAM). However, existing works have shortcomings in terms of reconstruction quality and real-time performance, mainly due to inflexible scene representation strategy without leveraging any prior information. In this paper, we introduce SP-SLAM, a novel neural RGB-D SLAM system that performs tracking and mapping in real-time. SP-SLAM computes depth images and establishes sparse voxel-encoded scene priors near the surfaces to achieve rapid convergence of the model. Subsequently, the encoding voxels computed from single-frame depth image are fused into a global volume, which facilitates high-fidelity surface reconstruction. Simultaneously, we employ tri-planes to store scene appearance information, striking a balance between achieving high-quality geometric texture mapping and minimizing memory consumption. Furthermore, in SP-SLAM, we introduce an effective optimization strategy for mapping, allowing the system to continuously optimize the poses of all historical input frames during runtime without increasing computational overhead. We conduct extensive evaluations on five benchmark datasets (Replica, ScanNet, TUM RGB-D, Synthetic RGB-D, 7-Scenes). The results demonstrate that, compared to existing methods, we achieve superior tracking accuracy and reconstruction quality, while running at a significantly faster speed.
GRID: Scene-Graph-based Instruction-driven Robotic Task Planning
Sep 14, 2023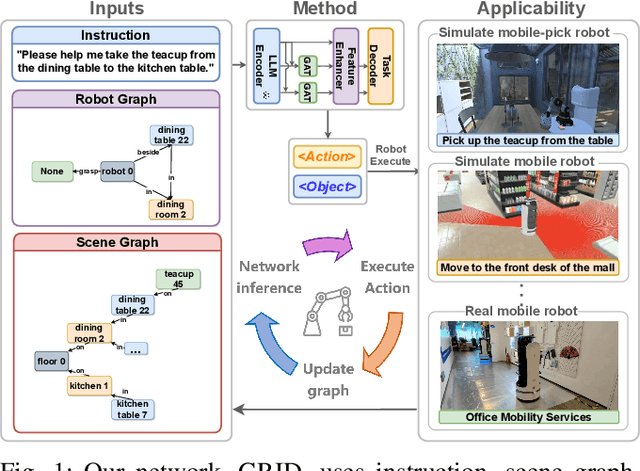
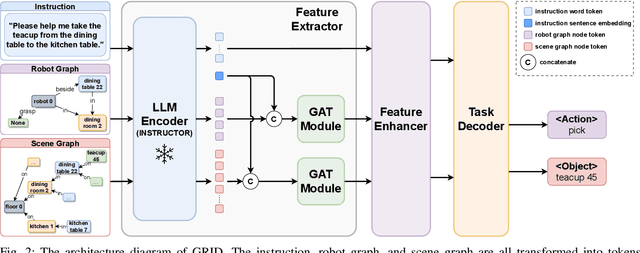
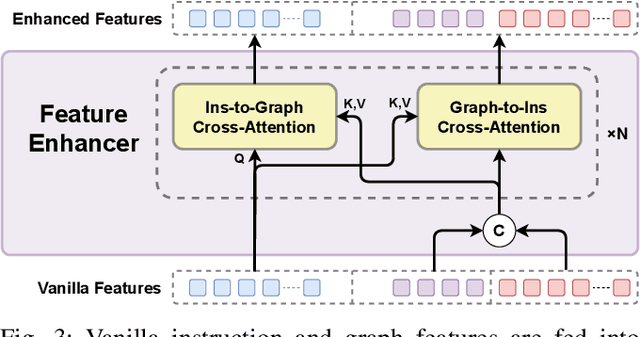
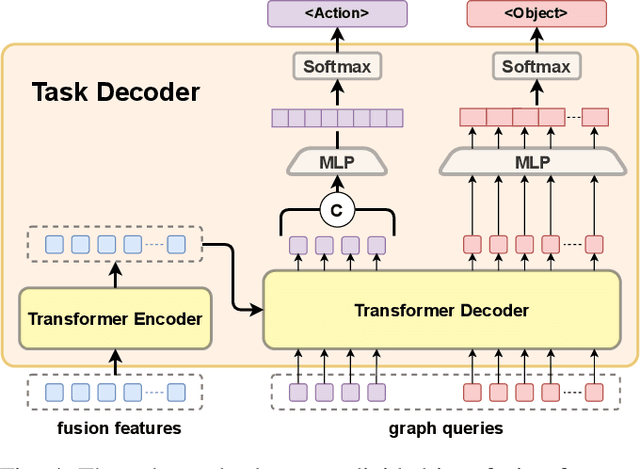
Recent works have shown that Large Language Models (LLMs) can promote grounding instructions to robotic task planning. Despite the progress, most existing works focused on utilizing raw images to help LLMs understand environmental information, which not only limits the observation scope but also typically requires massive multimodal data collection and large-scale models. In this paper, we propose a novel approach called Graph-based Robotic Instruction Decomposer (GRID), leverages scene graph instead of image to perceive global scene information and continuously plans subtask in each stage for a given instruction. Our method encodes object attributes and relationships in graphs through an LLM and Graph Attention Networks, integrating instruction features to predict subtasks consisting of pre-defined robot actions and target objects in the scene graph. This strategy enables robots to acquire semantic knowledge widely observed in the environment from the scene graph. To train and evaluate GRID, we build a dataset construction pipeline to generate synthetic datasets in graph-based robotic task planning. Experiments have shown that our method outperforms GPT-4 by over 25.4% in subtask accuracy and 43.6% in task accuracy. Experiments conducted on datasets of unseen scenes and scenes with different numbers of objects showed that the task accuracy of GRID declined by at most 3.8%, which demonstrates its good cross-scene generalization ability. We validate our method in both physical simulation and the real world.
Developmental Network Two, Its Optimality, and Emergent Turing Machines
Aug 04, 2022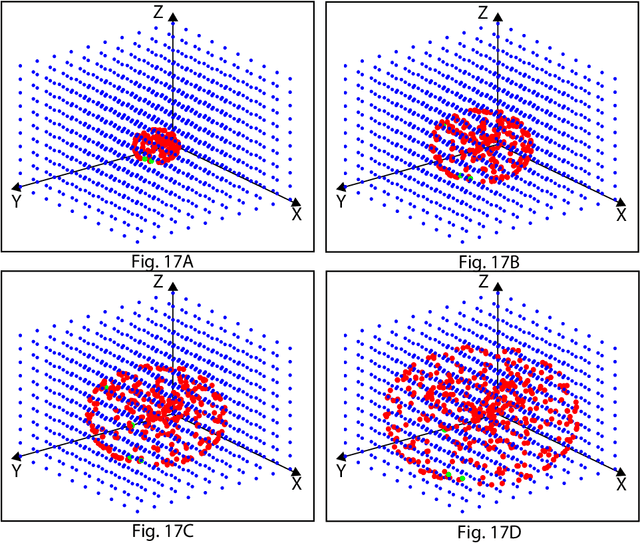
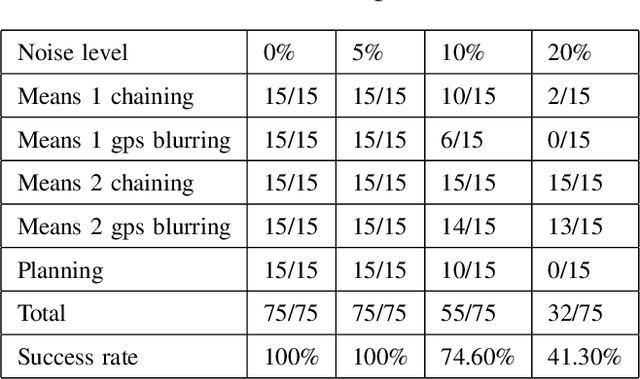
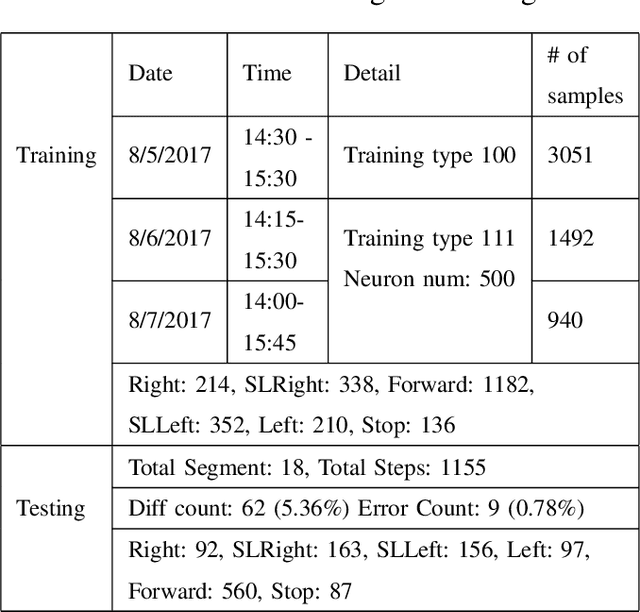
Strong AI requires the learning engine to be task non-specific and to automatically construct a dynamic hierarchy of internal features. By hierarchy, we mean, e.g., short road edges and short bush edges amount to intermediate features of landmarks; but intermediate features from tree shadows are distractors that must be disregarded by the high-level landmark concept. By dynamic, we mean the automatic selection of features while disregarding distractors is not static, but instead based on dynamic statistics (e.g. because of the instability of shadows in the context of landmark). By internal features, we mean that they are not only sensory, but also motor, so that context from motor (state) integrates with sensory inputs to become a context-based logic machine. We present why strong AI is necessary for any practical AI systems that work reliably in the real world. We then present a new generation of Developmental Networks 2 (DN-2). With many new novelties beyond DN-1, the most important novelty of DN-2 is that the inhibition area of each internal neuron is neuron-specific and dynamic. This enables DN-2 to automatically construct an internal hierarchy that is fluid, whose number of areas is not static as in DN-1. To optimally use the limited resource available, we establish that DN-2 is optimal in terms of maximum likelihood, under the condition of limited learning experience and limited resources. We also present how DN-2 can learn an emergent Universal Turing Machine (UTM). Together with the optimality, we present the optimal UTM. Experiments for real-world vision-based navigation, maze planning, and audition used DN-2. They successfully showed that DN-2 is for general purposes using natural and synthetic inputs. Their automatically constructed internal representation focuses on important features while being invariant to distractors and other irrelevant context-concepts.
One Backward from Ten Forward, Subsampling for Large-Scale Deep Learning
Apr 27, 2021
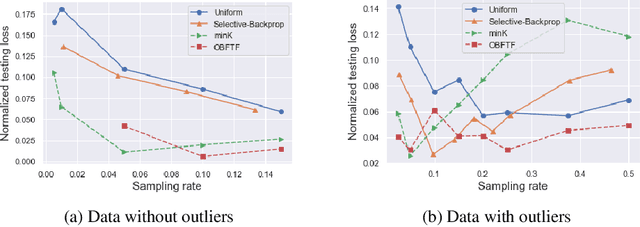

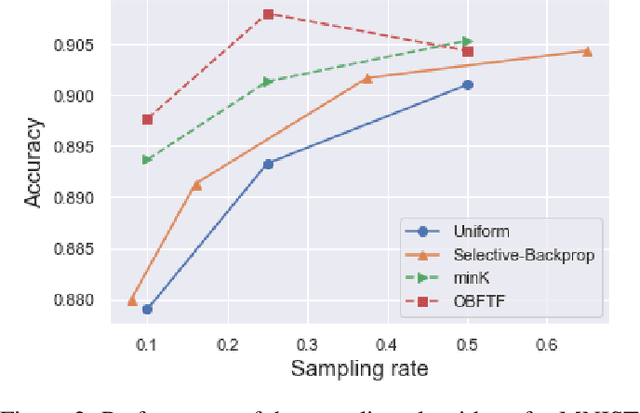
Deep learning models in large-scale machine learning systems are often continuously trained with enormous data from production environments. The sheer volume of streaming training data poses a significant challenge to real-time training subsystems and ad-hoc sampling is the standard practice. Our key insight is that these deployed ML systems continuously perform forward passes on data instances during inference, but ad-hoc sampling does not take advantage of this substantial computational effort. Therefore, we propose to record a constant amount of information per instance from these forward passes. The extra information measurably improves the selection of which data instances should participate in forward and backward passes. A novel optimization framework is proposed to analyze this problem and we provide an efficient approximation algorithm under the framework of Mini-batch gradient descent as a practical solution. We also demonstrate the effectiveness of our framework and algorithm on several large-scale classification and regression tasks, when compared with competitive baselines widely used in industry.
CM-NAS: Rethinking Cross-Modality Neural Architectures for Visible-Infrared Person Re-Identification
Jan 21, 2021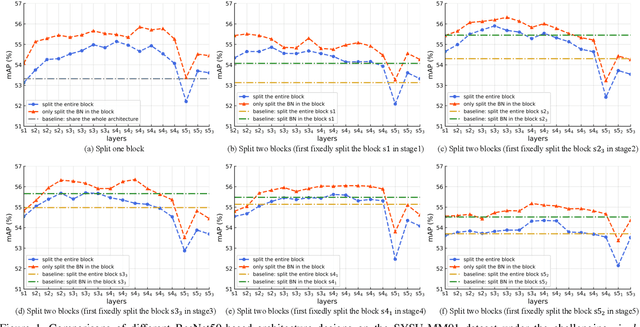
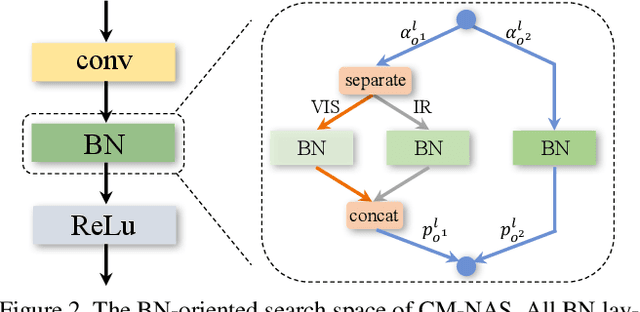
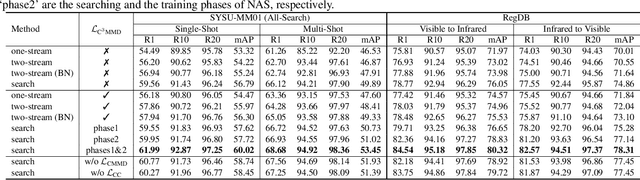
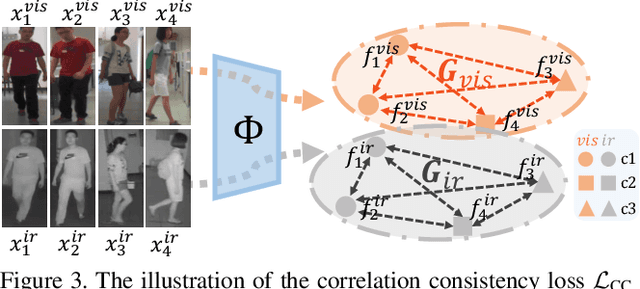
Visible-Infrared person re-identification (VI-ReID) aims at matching cross-modality pedestrian images, breaking through the limitation of single-modality person ReID in dark environment. In order to mitigate the impact of large modality discrepancy, existing works manually design various two-stream architectures to separately learn modality-specific and modality-sharable representations. Such a manual design routine, however, highly depends on massive experiments and empirical practice, which is time consuming and labor intensive. In this paper, we systematically study the manually designed architectures, and identify that appropriately splitting Batch Normalization (BN) layers to learn modality-specific representations will bring a great boost towards cross-modality matching. Based on this observation, the essential objective is to find the optimal splitting scheme for each BN layer. To this end, we propose a novel method, named Cross-Modality Neural Architecture Search (CM-NAS). It consists of a BN-oriented search space in which the standard optimization can be fulfilled subject to the cross-modality task. Besides, in order to better guide the search process, we further formulate a new Correlation Consistency based Class-specific Maximum Mean Discrepancy (C3MMD) loss. Apart from the modality discrepancy, it also concerns the similarity correlations, which have been overlooked before, in the two modalities. Resorting to these advantages, our method outperforms state-of-the-art counterparts in extensive experiments, improving the Rank-1/mAP by 6.70%/6.13% on SYSU-MM01 and 12.17%/11.23% on RegDB. The source code will be released soon.
Imbalance Robust Softmax for Deep Embeeding Learning
Nov 23, 2020
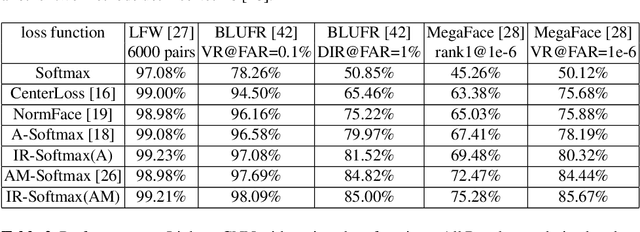
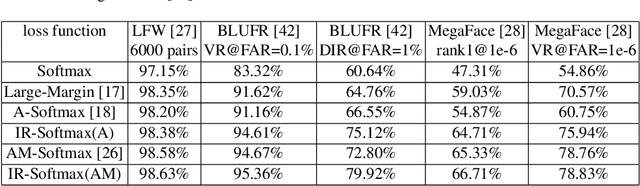
Deep embedding learning is expected to learn a metric space in which features have smaller maximal intra-class distance than minimal inter-class distance. In recent years, one research focus is to solve the open-set problem by discriminative deep embedding learning in the field of face recognition (FR) and person re-identification (re-ID). Apart from open-set problem, we find that imbalanced training data is another main factor causing the performance degradation of FR and re-ID, and data imbalance widely exists in the real applications. However, very little research explores why and how data imbalance influences the performance of FR and re-ID with softmax or its variants. In this work, we deeply investigate data imbalance in the perspective of neural network optimisation and feature distribution about softmax. We find one main reason of performance degradation caused by data imbalance is that the weights (from the penultimate fully-connected layer) are far from their class centers in feature space. Based on this investigation, we propose a unified framework, Imbalance-Robust Softmax (IR-Softmax), which can simultaneously solve the open-set problem and reduce the influence of data imbalance. IR-Softmax can generalise to any softmax and its variants (which are discriminative for open-set problem) by directly setting the weights as their class centers, naturally solving the data imbalance problem. In this work, we explicitly re-formulate two discriminative softmax (A-Softmax and AM-Softmax) under the framework of IR-Softmax. We conduct extensive experiments on FR databases (LFW, MegaFace) and re-ID database (Market-1501, Duke), and IR-Softmax outperforms many state-of-the-art methods.
DVG-Face: Dual Variational Generation for Heterogeneous Face Recognition
Sep 20, 2020

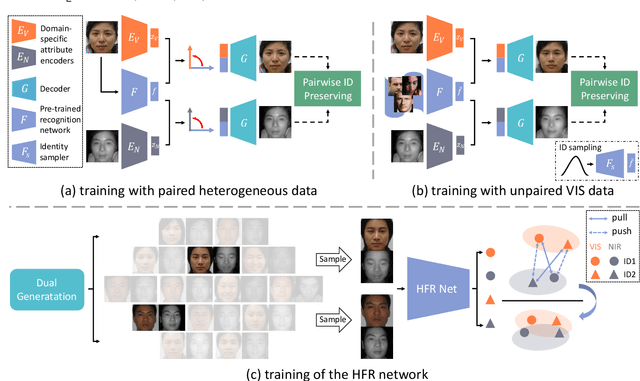
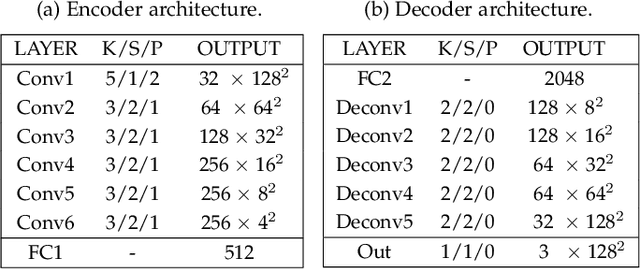
Heterogeneous Face Recognition (HFR) refers to matching cross-domain faces, playing a crucial role in public security. Nevertheless, HFR is confronted with the challenges from large domain discrepancy and insufficient heterogeneous data. In this paper, we formulate HFR as a dual generation problem, and tackle it via a novel Dual Variational Generation (DVG-Face) framework. Specifically, a dual variational generator is elaborately designed to learn the joint distribution of paired heterogeneous images. However, the small-scale paired heterogeneous training data may limit the identity diversity of sampling. With this in mind, we propose to integrate abundant identity information of large-scale VIS images into the joint distribution. Furthermore, a pairwise identity preserving loss is imposed on the generated paired heterogeneous images to ensure their identity consistency. As a consequence, massive new diverse paired heterogeneous images with the same identity can be generated from noises. The identity consistency and diversity properties allow us to employ these generated images to train the HFR network via a contrastive learning mechanism, yielding both domain invariant and discriminative embedding features. Concretely, the generated paired heterogeneous images are regarded as positive pairs, and the images obtained from different samplings are considered as negative pairs. Our method achieves superior performances over state-of-the-art methods on seven databases belonging to five HFR tasks, including NIR-VIS, Sketch-Photo, Profile-Frontal Photo, Thermal-VIS, and ID-Camera. The related code will be released at https://github.com/BradyFU.