 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSP-SLAM: Neural Real-Time Dense SLAM With Scene Priors
Jan 11, 2025Neural implicit representations have recently shown promising progress in dense Simultaneous Localization And Mapping (SLAM). However, existing works have shortcomings in terms of reconstruction quality and real-time performance, mainly due to inflexible scene representation strategy without leveraging any prior information. In this paper, we introduce SP-SLAM, a novel neural RGB-D SLAM system that performs tracking and mapping in real-time. SP-SLAM computes depth images and establishes sparse voxel-encoded scene priors near the surfaces to achieve rapid convergence of the model. Subsequently, the encoding voxels computed from single-frame depth image are fused into a global volume, which facilitates high-fidelity surface reconstruction. Simultaneously, we employ tri-planes to store scene appearance information, striking a balance between achieving high-quality geometric texture mapping and minimizing memory consumption. Furthermore, in SP-SLAM, we introduce an effective optimization strategy for mapping, allowing the system to continuously optimize the poses of all historical input frames during runtime without increasing computational overhead. We conduct extensive evaluations on five benchmark datasets (Replica, ScanNet, TUM RGB-D, Synthetic RGB-D, 7-Scenes). The results demonstrate that, compared to existing methods, we achieve superior tracking accuracy and reconstruction quality, while running at a significantly faster speed.
FLMarket: Enabling Privacy-preserved Pre-training Data Pricing for Federated Learning
Nov 18, 2024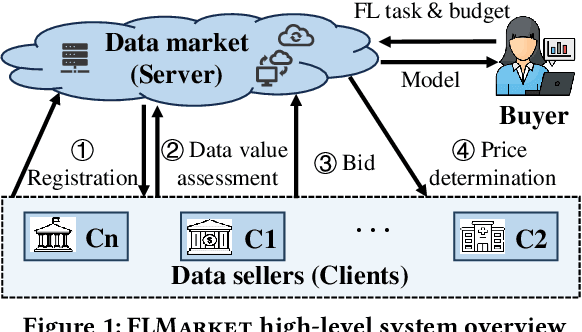
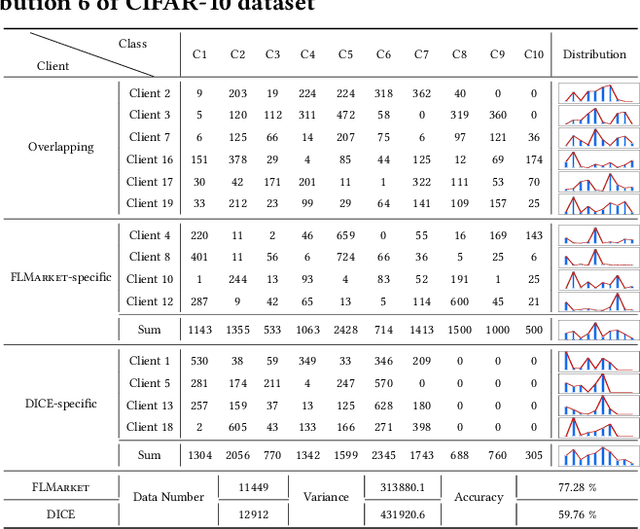
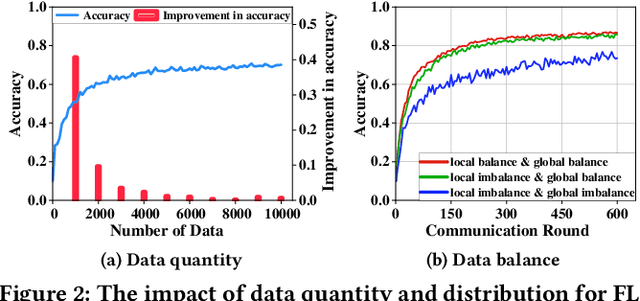
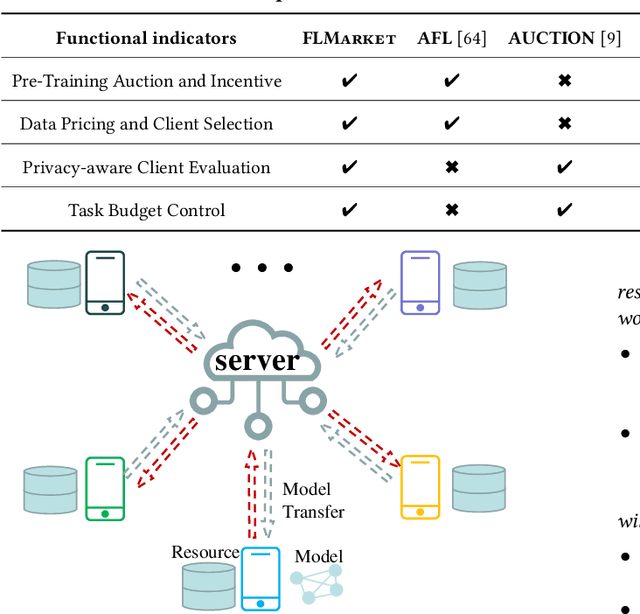
Federated Learning (FL), as a mainstream privacy-preserving machine learning paradigm, offers promising solutions for privacy-critical domains such as healthcare and finance. Although extensive efforts have been dedicated from both academia and industry to improve the vanilla FL, little work focuses on the data pricing mechanism. In contrast to the straightforward in/post-training pricing techniques, we study a more difficult problem of pre-training pricing without direct information from the learning process. We propose FLMarket that integrates a two-stage, auction-based pricing mechanism with a security protocol to address the utility-privacy conflict. Through comprehensive experiments, we show that the client selection according to FLMarket can achieve more than 10% higher accuracy in subsequent FL training compared to state-of-the-art methods. In addition, it outperforms the in-training baseline with more than 2% accuracy increase and 3x run-time speedup.
EfficientTDNN: Efficient Architecture Search for Speaker Recognition in the Wild
Apr 20, 2021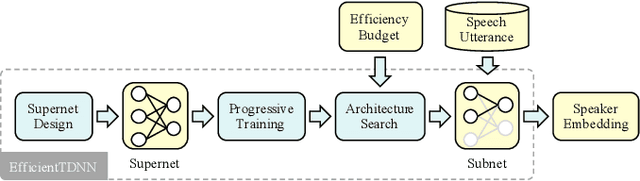

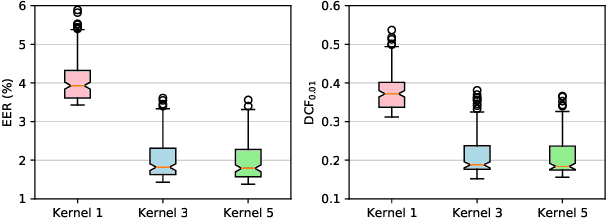
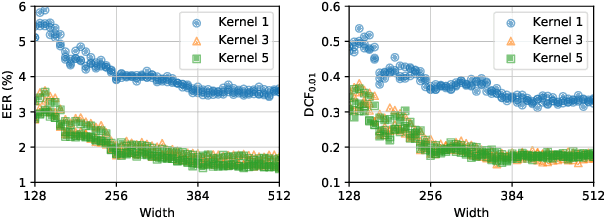
Speaker recognition refers to audio biometrics that utilizes acoustic characteristics. These systems have emerged as an essential means of authenticating identity in various areas such as smart homes, general business interactions, e-commerce applications, and forensics. The mismatch between development and real-world data causes a shift of speaker embedding space and severely degrades the performance of speaker recognition. Extensive efforts have been devoted to address speaker recognition in the wild, but these often neglect computation and storage requirements. In this work, we propose an efficient time-delay neural network (EfficientTDNN) based on neural architecture search to improve inference efficiency while maintaining recognition accuracy. The proposed EfficientTDNN contains three phases: supernet design, progressive training, and architecture search. Firstly, we borrow the design of TDNN to construct a supernet that enables sampling subnets with different depth, kernel, and width. Secondly, the supernet is progressively trained with multi-condition data augmentation to mitigate interference between subnets and overcome the challenge of optimizing a huge search space. Thirdly, an accuracy predictor and efficiency estimator are proposed to use in the architecture search to derive the specialized subnet under the given efficiency constraints. Experimental results on the VoxCeleb dataset show EfficientTDNN achieves 1.55% equal error rate (EER) and 0.138 detection cost function (DCF$_{0.01}$) with 565M multiply-accumulate operations (MACs) as well as 0.96% EER and 0.108 DCF$_{0.01}$ with 1.46G MACs. Comprehensive investigations suggest that the trained supernet generalizes subnets not sampled during training and obtains a favorable trade-off between accuracy and efficiency.