 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficientTDNN: Efficient Architecture Search for Speaker Recognition in the Wild
Paper and Code
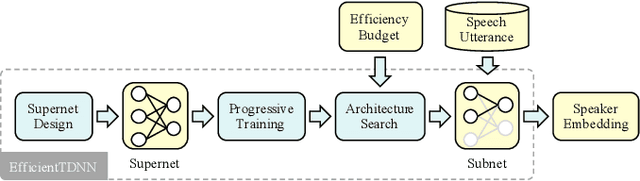

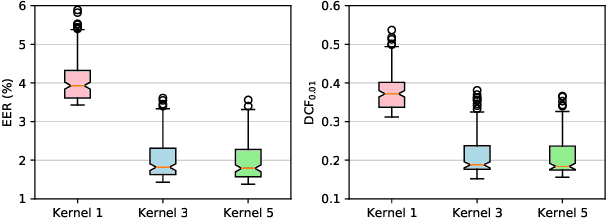
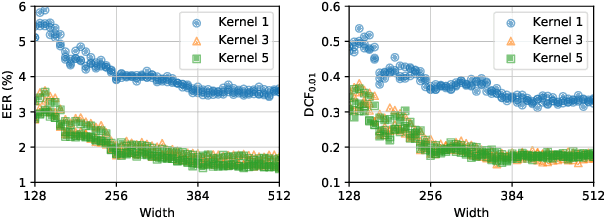
Speaker recognition refers to audio biometrics that utilizes acoustic characteristics. These systems have emerged as an essential means of authenticating identity in various areas such as smart homes, general business interactions, e-commerce applications, and forensics. The mismatch between development and real-world data causes a shift of speaker embedding space and severely degrades the performance of speaker recognition. Extensive efforts have been devoted to address speaker recognition in the wild, but these often neglect computation and storage requirements. In this work, we propose an efficient time-delay neural network (EfficientTDNN) based on neural architecture search to improve inference efficiency while maintaining recognition accuracy. The proposed EfficientTDNN contains three phases: supernet design, progressive training, and architecture search. Firstly, we borrow the design of TDNN to construct a supernet that enables sampling subnets with different depth, kernel, and width. Secondly, the supernet is progressively trained with multi-condition data augmentation to mitigate interference between subnets and overcome the challenge of optimizing a huge search space. Thirdly, an accuracy predictor and efficiency estimator are proposed to use in the architecture search to derive the specialized subnet under the given efficiency constraints. Experimental results on the VoxCeleb dataset show EfficientTDNN achieves 1.55% equal error rate (EER) and 0.138 detection cost function (DCF$_{0.01}$) with 565M multiply-accumulate operations (MACs) as well as 0.96% EER and 0.108 DCF$_{0.01}$ with 1.46G MACs. Comprehensive investigations suggest that the trained supernet generalizes subnets not sampled during training and obtains a favorable trade-off between accuracy and efficiency.