 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMO: Edge Model Overlays to Scale Model Size in Federated Learning
Apr 01, 2025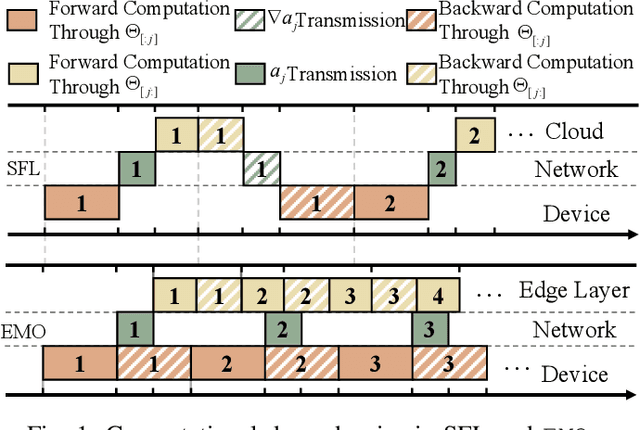
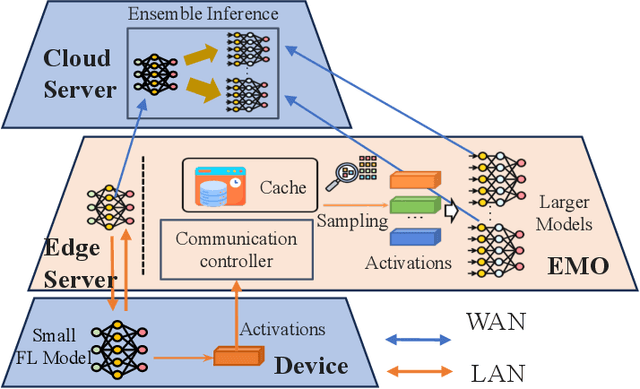
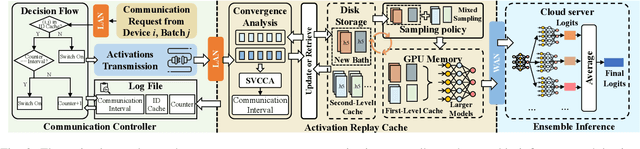
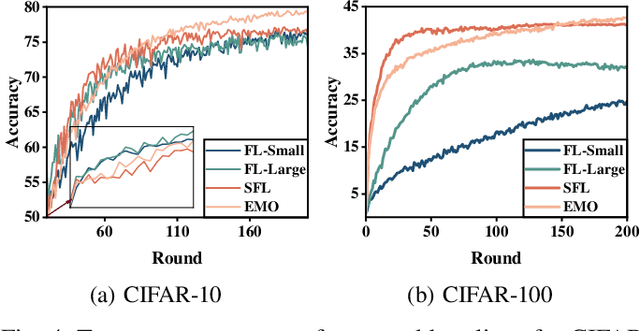
Federated Learning (FL) trains machine learning models on edge devices with distributed data. However, the computational and memory limitations of these devices restrict the training of large models using FL. Split Federated Learning (SFL) addresses this challenge by distributing the model across the device and server, but it introduces a tightly coupled data flow, leading to computational bottlenecks and high communication costs. We propose EMO as a solution to enable the training of large models in FL while mitigating the challenges of SFL. EMO introduces Edge Model Overlay(s) between the device and server, enabling the creation of a larger ensemble model without modifying the FL workflow. The key innovation in EMO is Augmented Federated Learning (AFL), which builds an ensemble model by connecting the original (smaller) FL model with model(s) trained in the overlay(s) to facilitate horizontal or vertical scaling. This is accomplished through three key modules: a hierarchical activation replay cache to decouple AFL from FL, a convergence-aware communication controller to optimize communication overhead, and an ensemble inference module. Evaluations on a real-world prototype show that EMO improves accuracy by up to 17.77% compared to FL, and reduces communication costs by up to 7.17x and decreases training time by up to 6.9x compared to SFL.
SP-SLAM: Neural Real-Time Dense SLAM With Scene Priors
Jan 11, 2025Neural implicit representations have recently shown promising progress in dense Simultaneous Localization And Mapping (SLAM). However, existing works have shortcomings in terms of reconstruction quality and real-time performance, mainly due to inflexible scene representation strategy without leveraging any prior information. In this paper, we introduce SP-SLAM, a novel neural RGB-D SLAM system that performs tracking and mapping in real-time. SP-SLAM computes depth images and establishes sparse voxel-encoded scene priors near the surfaces to achieve rapid convergence of the model. Subsequently, the encoding voxels computed from single-frame depth image are fused into a global volume, which facilitates high-fidelity surface reconstruction. Simultaneously, we employ tri-planes to store scene appearance information, striking a balance between achieving high-quality geometric texture mapping and minimizing memory consumption. Furthermore, in SP-SLAM, we introduce an effective optimization strategy for mapping, allowing the system to continuously optimize the poses of all historical input frames during runtime without increasing computational overhead. We conduct extensive evaluations on five benchmark datasets (Replica, ScanNet, TUM RGB-D, Synthetic RGB-D, 7-Scenes). The results demonstrate that, compared to existing methods, we achieve superior tracking accuracy and reconstruction quality, while running at a significantly faster speed.
FLMarket: Enabling Privacy-preserved Pre-training Data Pricing for Federated Learning
Nov 18, 2024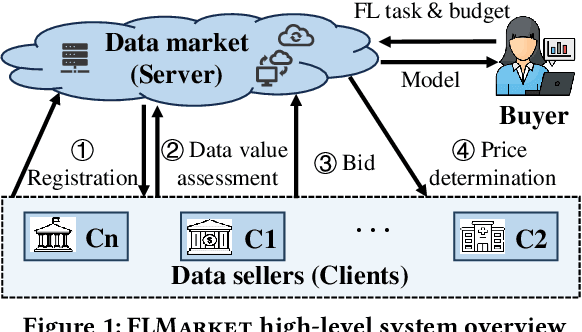
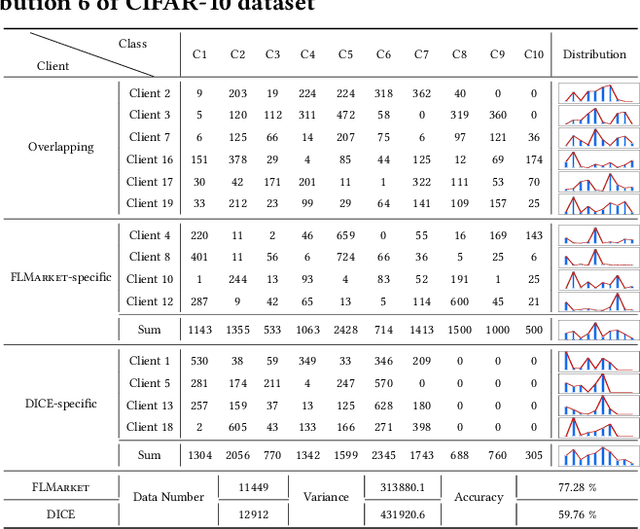
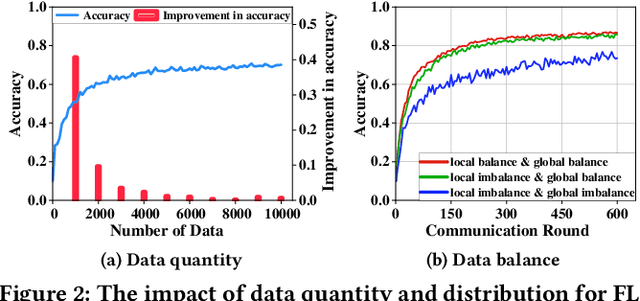
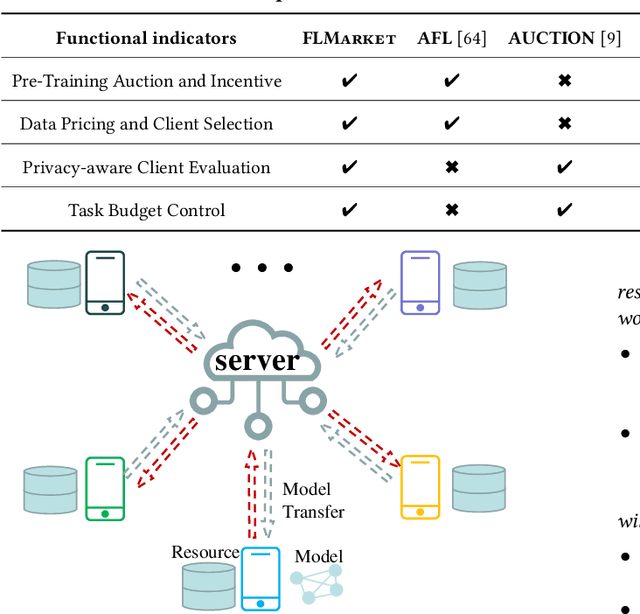
Federated Learning (FL), as a mainstream privacy-preserving machine learning paradigm, offers promising solutions for privacy-critical domains such as healthcare and finance. Although extensive efforts have been dedicated from both academia and industry to improve the vanilla FL, little work focuses on the data pricing mechanism. In contrast to the straightforward in/post-training pricing techniques, we study a more difficult problem of pre-training pricing without direct information from the learning process. We propose FLMarket that integrates a two-stage, auction-based pricing mechanism with a security protocol to address the utility-privacy conflict. Through comprehensive experiments, we show that the client selection according to FLMarket can achieve more than 10% higher accuracy in subsequent FL training compared to state-of-the-art methods. In addition, it outperforms the in-training baseline with more than 2% accuracy increase and 3x run-time speedup.
Dataset Distillation-based Hybrid Federated Learning on Non-IID Data
Sep 26, 2024



In federated learning, the heterogeneity of client data has a great impact on the performance of model training. Many heterogeneity issues in this process are raised by non-independently and identically distributed (Non-IID) data. This study focuses on the issue of label distribution skew. To address it, we propose a hybrid federated learning framework called HFLDD, which integrates dataset distillation to generate approximately independent and equally distributed (IID) data, thereby improving the performance of model training. Particularly, we partition the clients into heterogeneous clusters, where the data labels among different clients within a cluster are unbalanced while the data labels among different clusters are balanced. The cluster headers collect distilled data from the corresponding cluster members, and conduct model training in collaboration with the server. This training process is like traditional federated learning on IID data, and hence effectively alleviates the impact of Non-IID data on model training. Furthermore, we compare our proposed method with typical baseline methods on public datasets. Experimental results demonstrate that when the data labels are severely imbalanced, the proposed HFLDD outperforms the baseline methods in terms of both test accuracy and communication cost.
Data Augmentation on Graphs: A Survey
Dec 20, 2022In recent years, graph representation learning has achieved remarkable success while suffering from low-quality data problems. As a mature technology to improve data quality in computer vision, data augmentation has also attracted increasing attention in graph domain. For promoting the development of this emerging research direction, in this survey, we comprehensively review and summarize the existing graph data augmentation (GDAug) techniques. Specifically, we first summarize a variety of feasible taxonomies, and then classify existing GDAug studies based on fine-grained graph elements. Furthermore, for each type of GDAug technique, we formalize the general definition, discuss the technical details, and give schematic illustration. In addition, we also summarize common performance metrics and specific design metrics for constructing a GDAug evaluation system. Finally, we summarize the applications of GDAug from both data and model levels, as well as future directions.
Learning Disentangled Behaviour Patterns for Wearable-based Human Activity Recognition
Feb 15, 2022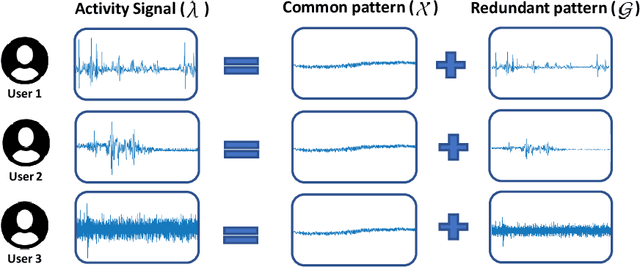

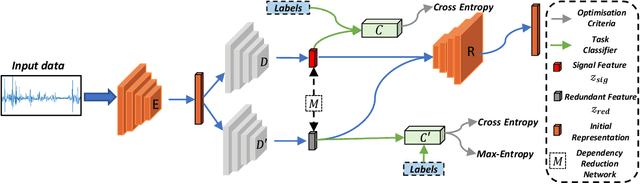
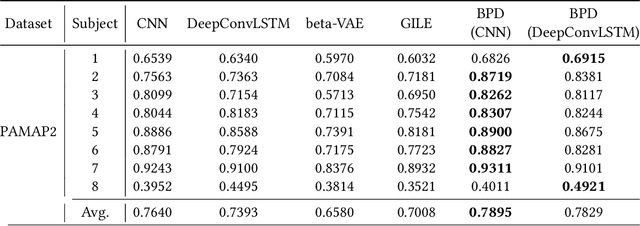
In wearable-based human activity recognition (HAR) research, one of the major challenges is the large intra-class variability problem. The collected activity signal is often, if not always, coupled with noises or bias caused by personal, environmental, or other factors, making it difficult to learn effective features for HAR tasks, especially when with inadequate data. To address this issue, in this work, we proposed a Behaviour Pattern Disentanglement (BPD) framework, which can disentangle the behavior patterns from the irrelevant noises such as personal styles or environmental noises, etc. Based on a disentanglement network, we designed several loss functions and used an adversarial training strategy for optimization, which can disentangle activity signals from the irrelevant noises with the least dependency (between them) in the feature space. Our BPD framework is flexible, and it can be used on top of existing deep learning (DL) approaches for feature refinement. Extensive experiments were conducted on four public HAR datasets, and the promising results of our proposed BPD scheme suggest its flexibility and effectiveness. This is an open-source project, and the code can be found at http://github.com/Jie-su/BPD
Orchestrating Development Lifecycle of Machine Learning Based IoT Applications: A Survey
Oct 15, 2019
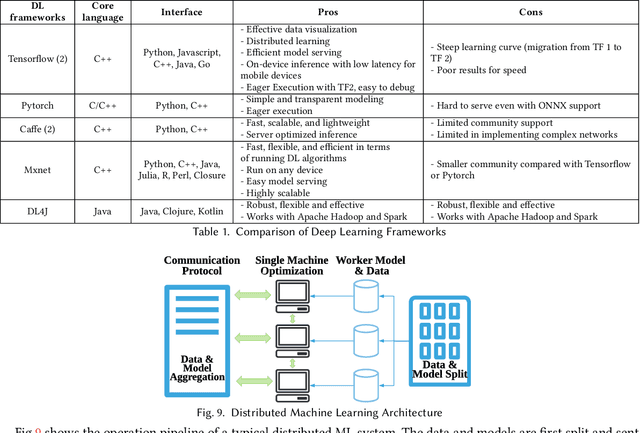
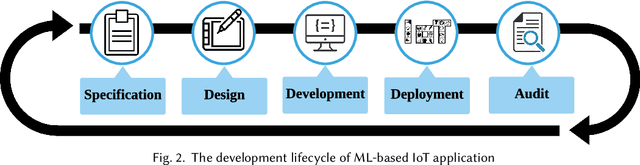

Machine Learning (ML) and Internet of Things (IoT) are complementary advances: ML techniques unlock complete potentials of IoT with intelligence, and IoT applications increasingly feed data collected by sensors into ML models, thereby employing results to improve their business processes and services. Hence, orchestrating ML pipelines that encompasses model training and implication involved in holistic development lifecycle of an IoT application often leads to complex system integration. This paper provides a comprehensive and systematic survey on the development lifecycle of ML-based IoT application. We outline core roadmap and taxonomy, and subsequently assess and compare existing standard techniques used in individual stage.