 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge Intelligence with Spiking Neural Networks
Jul 18, 2025The convergence of artificial intelligence and edge computing has spurred growing interest in enabling intelligent services directly on resource-constrained devices. While traditional deep learning models require significant computational resources and centralized data management, the resulting latency, bandwidth consumption, and privacy concerns have exposed critical limitations in cloud-centric paradigms. Brain-inspired computing, particularly Spiking Neural Networks (SNNs), offers a promising alternative by emulating biological neuronal dynamics to achieve low-power, event-driven computation. This survey provides a comprehensive overview of Edge Intelligence based on SNNs (EdgeSNNs), examining their potential to address the challenges of on-device learning, inference, and security in edge scenarios. We present a systematic taxonomy of EdgeSNN foundations, encompassing neuron models, learning algorithms, and supporting hardware platforms. Three representative practical considerations of EdgeSNN are discussed in depth: on-device inference using lightweight SNN models, resource-aware training and updating under non-stationary data conditions, and secure and privacy-preserving issues. Furthermore, we highlight the limitations of evaluating EdgeSNNs on conventional hardware and introduce a dual-track benchmarking strategy to support fair comparisons and hardware-aware optimization. Through this study, we aim to bridge the gap between brain-inspired learning and practical edge deployment, offering insights into current advancements, open challenges, and future research directions. To the best of our knowledge, this is the first dedicated and comprehensive survey on EdgeSNNs, providing an essential reference for researchers and practitioners working at the intersection of neuromorphic computing and edge intelligence.
Personalizing Federated Learning for Hierarchical Edge Networks with Non-IID Data
Apr 11, 2025Accommodating edge networks between IoT devices and the cloud server in Hierarchical Federated Learning (HFL) enhances communication efficiency without compromising data privacy. However, devices connected to the same edge often share geographic or contextual similarities, leading to varying edge-level data heterogeneity with different subsets of labels per edge, on top of device-level heterogeneity. This hierarchical non-Independent and Identically Distributed (non-IID) nature, which implies that each edge has its own optimization goal, has been overlooked in HFL research. Therefore, existing edge-accommodated HFL demonstrates inconsistent performance across edges in various hierarchical non-IID scenarios. To ensure robust performance with diverse edge-level non-IID data, we propose a Personalized Hierarchical Edge-enabled Federated Learning (PHE-FL), which personalizes each edge model to perform well on the unique class distributions specific to each edge. We evaluated PHE-FL across 4 scenarios with varying levels of edge-level non-IIDness, with extreme IoT device level non-IIDness. To accurately assess the effectiveness of our personalization approach, we deployed test sets on each edge server instead of the cloud server, and used both balanced and imbalanced test sets. Extensive experiments show that PHE-FL achieves up to 83 percent higher accuracy compared to existing federated learning approaches that incorporate edge networks, given the same number of training rounds. Moreover, PHE-FL exhibits improved stability, as evidenced by reduced accuracy fluctuations relative to the state-of-the-art FedAvg with two-level (edge and cloud) aggregation.
AutoRank: MCDA Based Rank Personalization for LoRA-Enabled Distributed Learning
Dec 20, 2024



As data volumes expand rapidly, distributed machine learning has become essential for addressing the growing computational demands of modern AI systems. However, training models in distributed environments is challenging with participants hold skew, Non-Independent-Identically distributed (Non-IID) data. Low-Rank Adaptation (LoRA) offers a promising solution to this problem by personalizing low-rank updates rather than optimizing the entire model, LoRA-enabled distributed learning minimizes computational and maximize personalization for each participant. Enabling more robust and efficient training in distributed learning settings, especially in large-scale, heterogeneous systems. Despite the strengths of current state-of-the-art methods, they often require manual configuration of the initial rank, which is increasingly impractical as the number of participants grows. This manual tuning is not only time-consuming but also prone to suboptimal configurations. To address this limitation, we propose AutoRank, an adaptive rank-setting algorithm inspired by the bias-variance trade-off. AutoRank leverages the MCDA method TOPSIS to dynamically assign local ranks based on the complexity of each participant's data. By evaluating data distribution and complexity through our proposed data complexity metrics, AutoRank provides fine-grained adjustments to the rank of each participant's local LoRA model. This adaptive approach effectively mitigates the challenges of double-imbalanced, non-IID data. Experimental results demonstrate that AutoRank significantly reduces computational overhead, enhances model performance, and accelerates convergence in highly heterogeneous federated learning environments. Through its strong adaptability, AutoRank offers a scalable and flexible solution for distributed machine learning.
RBLA: Rank-Based-LoRA-Aggregation for Fine-tuning Heterogeneous Models in FLaaS
Aug 16, 2024



Federated Learning (FL) is a promising privacy-aware distributed learning framework that can be deployed on various devices, such as mobile phones, desktops, and devices equipped with CPUs or GPUs. In the context of server-based Federated Learning as a Service (FLaas), FL enables the central server to coordinate the training process across multiple devices without direct access to the local data, thereby enhancing privacy and data security. Low-Rank Adaptation (LoRA) is a method that fine-tunes models efficiently by focusing on a low-dimensional subspace of the model's parameters. This approach significantly reduces computational and memory costs compared to fine-tuning all parameters from scratch. When integrated with FL, especially in a FLaas environment, LoRA allows for flexible and efficient deployment across diverse hardware with varying computational capabilities by adjusting the local model's rank. However, in LoRA-enabled FL, different clients may train models with varying ranks, which poses a challenge for model aggregation on the server. Current methods of aggregating models of different ranks require padding weights to a uniform shape, which can degrade the global model's performance. To address this issue, we propose Rank-Based LoRA Aggregation (RBLA), a novel model aggregation method designed for heterogeneous LoRA structures. RBLA preserves key features across models with different ranks. This paper analyzes the issues with current padding methods that reshape models for aggregation in a FLaas environment. Then, we introduce RBLA, a rank-based aggregation method that maintains both low-rank and high-rank features. Finally, we demonstrate the effectiveness of RBLA through comparative experiments with state-of-the-art methods.
CGS-Mask: Making Time Series Predictions Intuitive for All
Dec 20, 2023



Artificial intelligence (AI) has immense potential in time series prediction, but most explainable tools have limited capabilities in providing a systematic understanding of important features over time. These tools typically rely on evaluating a single time point, overlook the time ordering of inputs, and neglect the time-sensitive nature of time series applications. These factors make it difficult for users, particularly those without domain knowledge, to comprehend AI model decisions and obtain meaningful explanations. We propose CGS-Mask, a post-hoc and model-agnostic cellular genetic strip mask-based saliency approach to address these challenges. CGS-Mask uses consecutive time steps as a cohesive entity to evaluate the impact of features on the final prediction, providing binary and sustained feature importance scores over time. Our algorithm optimizes the mask population iteratively to obtain the optimal mask in a reasonable time. We evaluated CGS-Mask on synthetic and real-world datasets, and it outperformed state-of-the-art methods in elucidating the importance of features over time. According to our pilot user study via a questionnaire survey, CGS-Mask is the most effective approach in presenting easily understandable time series prediction results, enabling users to comprehend the decision-making process of AI models with ease.
Hierarchical Federated Learning with Momentum Acceleration in Multi-Tier Networks
Oct 26, 2022In this paper, we propose Hierarchical Federated Learning with Momentum Acceleration (HierMo), a three-tier worker-edge-cloud federated learning algorithm that applies momentum for training acceleration. Momentum is calculated and aggregated in the three tiers. We provide convergence analysis for HierMo, showing a convergence rate of O(1/T). In the analysis, we develop a new approach to characterize model aggregation, momentum aggregation, and their interactions. Based on this result, {we prove that HierMo achieves a tighter convergence upper bound compared with HierFAVG without momentum}. We also propose HierOPT, which optimizes the aggregation periods (worker-edge and edge-cloud aggregation periods) to minimize the loss given a limited training time.
Intelligent Blockchain-based Edge Computing via Deep Reinforcement Learning: Solutions and Challenges
Jun 17, 2022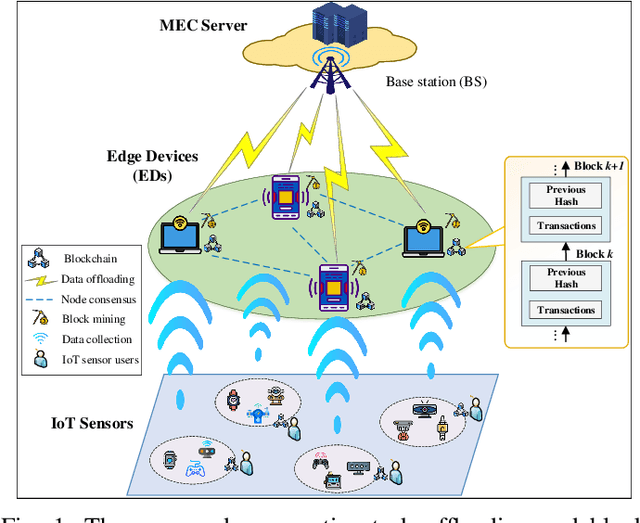
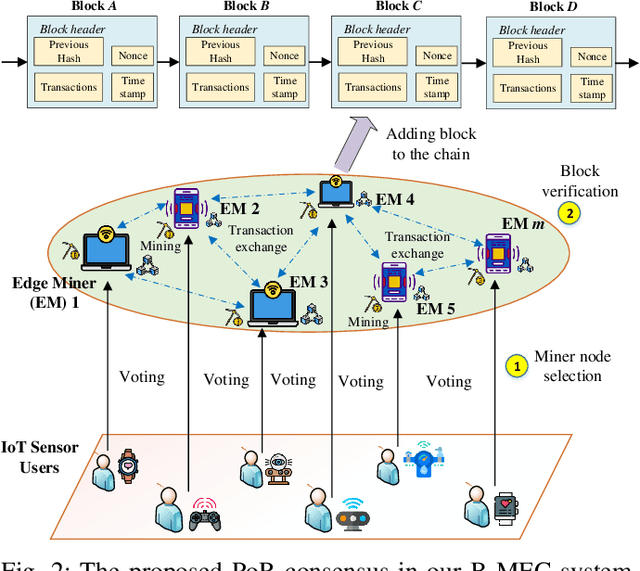
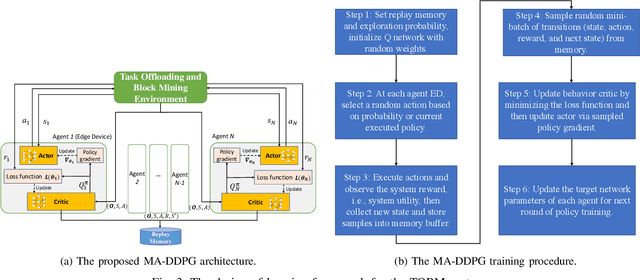
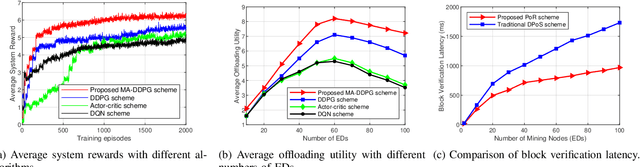
The convergence of mobile edge computing (MEC) and blockchain is transforming the current computing services in wireless Internet-of-Things networks, by enabling task offloading with security enhancement based on blockchain mining. Yet the existing approaches for these enabling technologies are isolated, providing only tailored solutions for specific services and scenarios. To fill this gap, we propose a novel cooperative task offloading and blockchain mining (TOBM) scheme for a blockchain-based MEC system, where each edge device not only handles computation tasks but also deals with block mining for improving system utility. To address the latency issues caused by the blockchain operation in MEC, we develop a new Proof-of-Reputation consensus mechanism based on a lightweight block verification strategy. To accommodate the highly dynamic environment and high-dimensional system state space, we apply a novel distributed deep reinforcement learning-based approach by using a multi-agent deep deterministic policy gradient algorithm. Experimental results demonstrate the superior performance of the proposed TOBM scheme in terms of enhanced system reward, improved offloading utility with lower blockchain mining latency, and better system utility, compared to the existing cooperative and non-cooperative schemes. The paper concludes with key technical challenges and possible directions for future blockchain-based MEC research.
Federated Learning for COVID-19 Detection with Generative Adversarial Networks in Edge Cloud Computing
Oct 14, 2021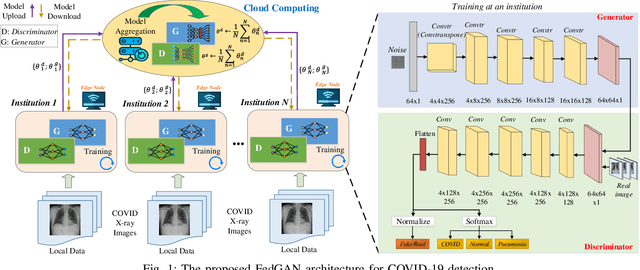
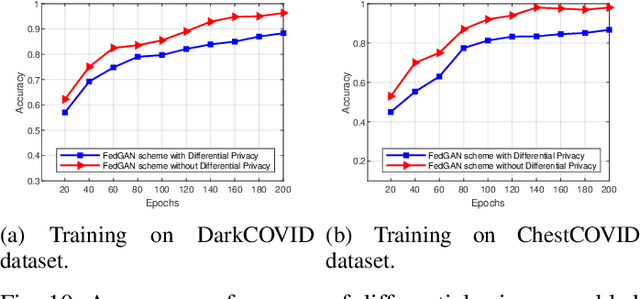
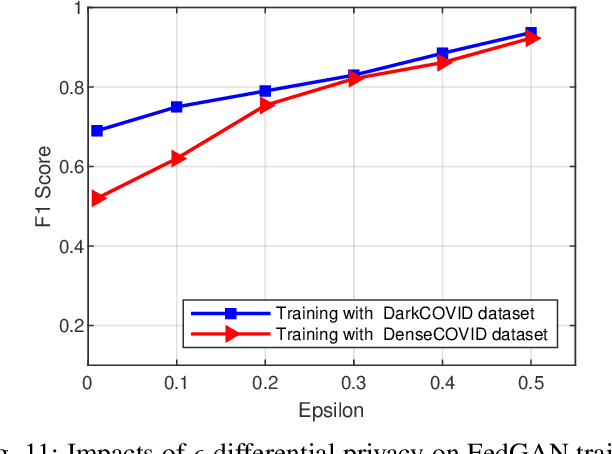
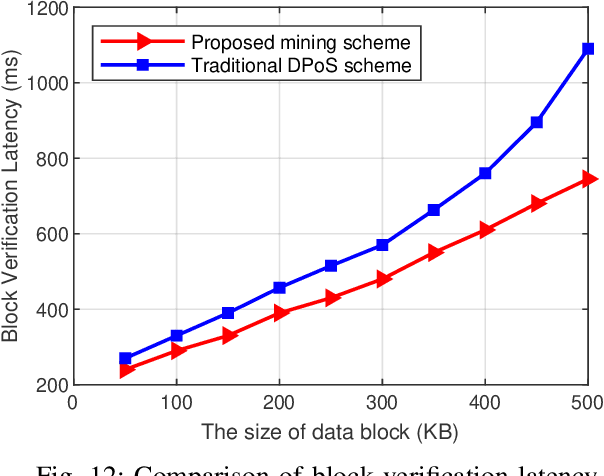
COVID-19 has spread rapidly across the globe and become a deadly pandemic. Recently, many artificial intelligence-based approaches have been used for COVID-19 detection, but they often require public data sharing with cloud datacentres and thus remain privacy concerns. This paper proposes a new federated learning scheme, called FedGAN, to generate realistic COVID-19 images for facilitating privacy-enhanced COVID-19 detection with generative adversarial networks (GANs) in edge cloud computing. Particularly, we first propose a GAN where a discriminator and a generator based on convolutional neural networks (CNNs) at each edge-based medical institution alternatively are trained to mimic the real COVID-19 data distribution. Then, we propose a new federated learning solution which allows local GANs to collaborate and exchange learned parameters with a cloud server, aiming to enrich the global GAN model for generating realistic COVID-19 images without the need for sharing actual data. To enhance the privacy in federated COVID-19 data analytics, we integrate a differential privacy solution at each hospital institution. Moreover, we propose a new blockchain-based FedGAN framework for secure COVID-19 data analytics, by decentralizing the FL process with a new mining solution for low running latency. Simulations results demonstrate the superiority of our approach for COVID-19 detection over the state-of-the-art schemes.
Adaptive Processor Frequency Adjustment for Mobile Edge Computing with Intermittent Energy Supply
Feb 10, 2021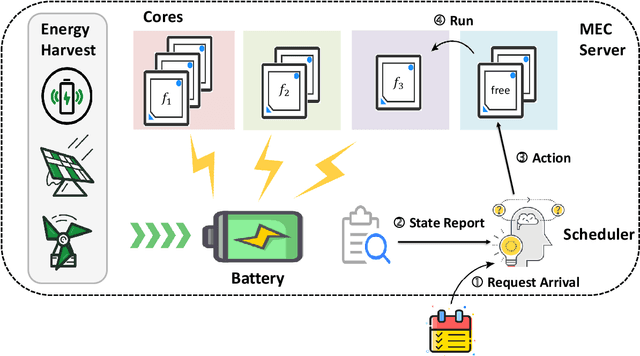
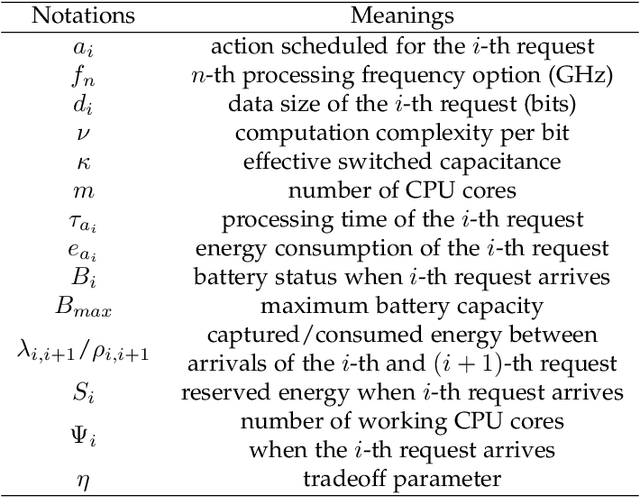
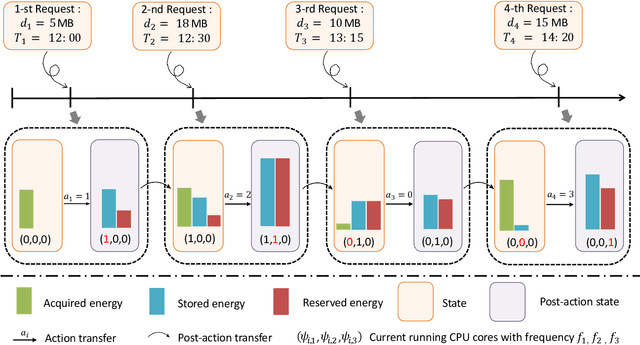

With astonishing speed, bandwidth, and scale, Mobile Edge Computing (MEC) has played an increasingly important role in the next generation of connectivity and service delivery. Yet, along with the massive deployment of MEC servers, the ensuing energy issue is now on an increasingly urgent agenda. In the current context, the large scale deployment of renewable-energy-supplied MEC servers is perhaps the most promising solution for the incoming energy issue. Nonetheless, as a result of the intermittent nature of their power sources, these special design MEC server must be more cautious about their energy usage, in a bid to maintain their service sustainability as well as service standard. Targeting optimization on a single-server MEC scenario, we in this paper propose NAFA, an adaptive processor frequency adjustment solution, to enable an effective plan of the server's energy usage. By learning from the historical data revealing request arrival and energy harvest pattern, the deep reinforcement learning-based solution is capable of making intelligent schedules on the server's processor frequency, so as to strike a good balance between service sustainability and service quality. The superior performance of NAFA is substantiated by real-data-based experiments, wherein NAFA demonstrates up to 20% increase in average request acceptance ratio and up to 50% reduction in average request processing time.
Stochastic Client Selection for Federated Learning with Volatile Clients
Nov 17, 2020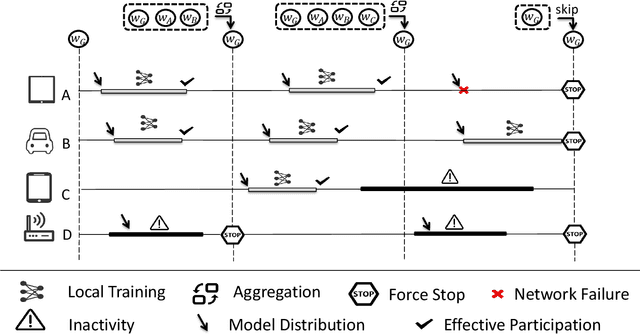
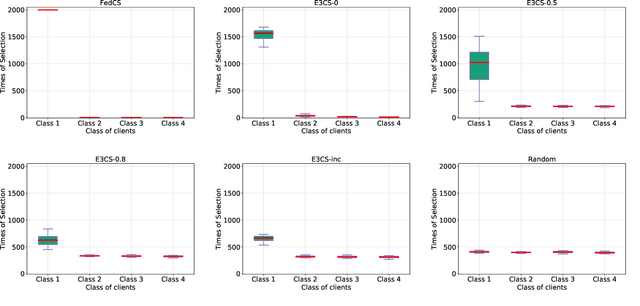
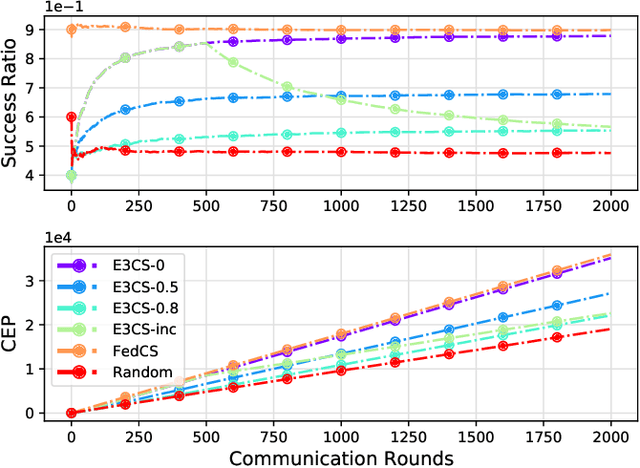
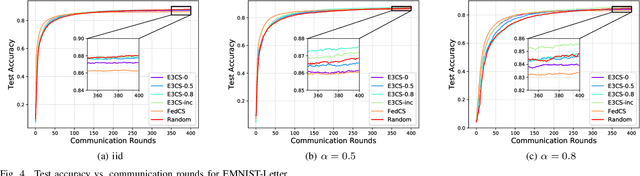
Federated Learning (FL), arising as a novel secure learning paradigm, has received notable attention from the public. In each round of synchronous FL training, only a fraction of available clients are chosen to participate and the selection of which might have a direct or indirect effect on the training efficiency, as well as the final model performance. In this paper, we investigate the client selection problem under a volatile context, in which the local training of heterogeneous clients is likely to fail due to various kinds of reasons and in different levels of frequency. Intuitively, too much training failure might potentially reduce the training efficiency and therefore should be regulated through proper selection of clients. Being inspired, effective participation under a deadline-based aggregation mechanism is modeled as the objective function in our problem model, and the fairness degree, another critical factor that might influence the training performance, is covered as an expected constraint. For an efficient settlement for the proposed selection problem, we propose E3CS, a stochastic client selection scheme on the basis of an adversarial bandit solution and we further corroborate its effectiveness by conducting real data-based experiments. According to the experimental results, under a proper setting, our proposed selection scheme is able to achieve at least 20 percent and up to 50 percent of acceleration to a fixed model accuracy while maintaining the same level of final model accuracy, in comparison to the vanilla selection scheme in FL.