 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCGS-Mask: Making Time Series Predictions Intuitive for All
Dec 20, 2023



Artificial intelligence (AI) has immense potential in time series prediction, but most explainable tools have limited capabilities in providing a systematic understanding of important features over time. These tools typically rely on evaluating a single time point, overlook the time ordering of inputs, and neglect the time-sensitive nature of time series applications. These factors make it difficult for users, particularly those without domain knowledge, to comprehend AI model decisions and obtain meaningful explanations. We propose CGS-Mask, a post-hoc and model-agnostic cellular genetic strip mask-based saliency approach to address these challenges. CGS-Mask uses consecutive time steps as a cohesive entity to evaluate the impact of features on the final prediction, providing binary and sustained feature importance scores over time. Our algorithm optimizes the mask population iteratively to obtain the optimal mask in a reasonable time. We evaluated CGS-Mask on synthetic and real-world datasets, and it outperformed state-of-the-art methods in elucidating the importance of features over time. According to our pilot user study via a questionnaire survey, CGS-Mask is the most effective approach in presenting easily understandable time series prediction results, enabling users to comprehend the decision-making process of AI models with ease.
GaDei: On Scale-up Training As A Service For Deep Learning
Oct 03, 2017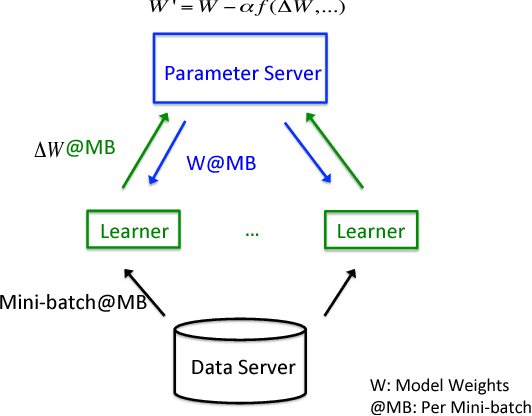
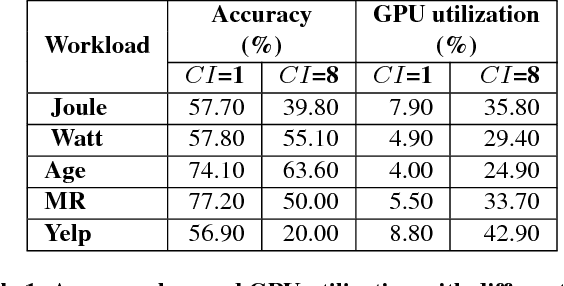
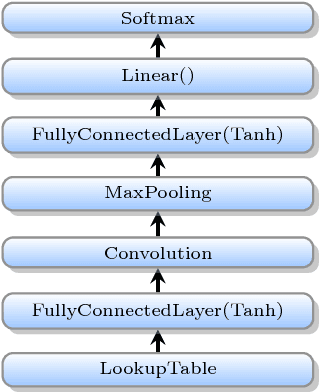
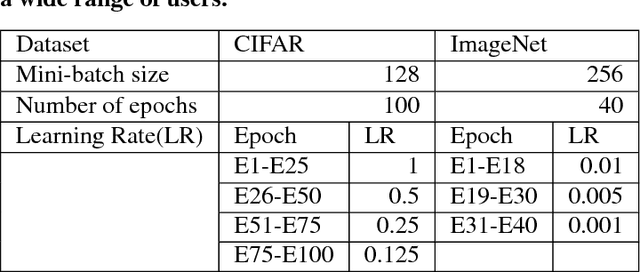
Deep learning (DL) training-as-a-service (TaaS) is an important emerging industrial workload. The unique challenge of TaaS is that it must satisfy a wide range of customers who have no experience and resources to tune DL hyper-parameters, and meticulous tuning for each user's dataset is prohibitively expensive. Therefore, TaaS hyper-parameters must be fixed with values that are applicable to all users. IBM Watson Natural Language Classifier (NLC) service, the most popular IBM cognitive service used by thousands of enterprise-level clients around the globe, is a typical TaaS service. By evaluating the NLC workloads, we show that only the conservative hyper-parameter setup (e.g., small mini-batch size and small learning rate) can guarantee acceptable model accuracy for a wide range of customers. We further justify theoretically why such a setup guarantees better model convergence in general. Unfortunately, the small mini-batch size causes a high volume of communication traffic in a parameter-server based system. We characterize the high communication bandwidth requirement of TaaS using representative industrial deep learning workloads and demonstrate that none of the state-of-the-art scale-up or scale-out solutions can satisfy such a requirement. We then present GaDei, an optimized shared-memory based scale-up parameter server design. We prove that the designed protocol is deadlock-free and it processes each gradient exactly once. Our implementation is evaluated on both commercial benchmarks and public benchmarks to demonstrate that it significantly outperforms the state-of-the-art parameter-server based implementation while maintaining the required accuracy and our implementation reaches near the best possible runtime performance, constrained only by the hardware limitation. Furthermore, to the best of our knowledge, GaDei is the only scale-up DL system that provides fault-tolerance.