 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Quality-Utility Paradox: Why High-Reward Data Impairs Small Model Mathematical Reasoning
Jun 15, 2026Knowledge distillation from powerful reasoning models is widely used to improve Small Language Models (SLMs) on mathematical reasoning, often assuming that traces with higher reward model scores provide more useful supervision. We identify a counterintuitive \textbf{Quality-Utility Paradox} in mathematical reasoning distillation. Data refined or synthesized by a stronger Oracle obtains higher perceived quality according to reward models, yet consistently underperforms traces generated by the SLM itself and selected through rejection sampling across Qwen2.5, LLaMA-3, and DeepSeek families. Our analysis shows that Oracle refinement couples logical repair with distributional drift away from the SLM's native reasoning distribution. This drift increases the learner's adaptation cost and can outweigh the benefit of improved reasoning logic. To test this mechanism, we introduce \textbf{Style-Aligned Refinement}, which preserves the native trajectory of the SLM while retaining logical repair from the Oracle. This intervention lowers adaptation cost and restores downstream utility. These findings suggest that effective mathematical reasoning distillation should jointly optimize perceived solution quality and learner-data compatibility, rather than relying solely on reward-model scores. The datasets and code are available at https://github.com/Dracoqhl/Quality-Utility-Paradox.
Where, What, Why, and Importance: Structured Defect Grounding for Text-to-Image Feedback
Jun 04, 2026Despite generating increasingly photorealistic images, text-to-image (T2I) models still exhibit localized, subtle, and structurally complex failures. Diagnosing these failures requires instance-level feedback that answers where a defect occurs, what type it is, why it is defective, and its importance to overall image quality. While recent dense-feedback methods move beyond scalar supervision, their heatmap-centric representations still formulate diagnosis as pixel-field regression, making it difficult to localize variable-cardinality defects and bind semantic reasons to individual failures. To address this representation bottleneck, we propose Structured Defect Grounding (SDG), which casts T2I diagnosis as structured set prediction by modeling each defect as a (location, type, reason, importance) tuple. To make this formulation trainable and measurable, we introduce SDG-30K, a 30K-image dataset with box-grounded annotations across four modern T2I generators, together with a dedicated evaluation protocol, SDG-Eval. Building on this structured representation, we further present a diagnosis-to-alignment framework in which a Vision-Language Model (VLM) serves as the SDG detector, and BoxFlow-GRPO converts predicted defect sets into box-derived, importance-weighted spatial rewards for diffusion model alignment. Extensive experiments show that our SDG detector outperforms leading proprietary VLMs on structured defect grounding, while SDG-guided rewards consistently improve T2I alignment and support localized image refinement. These results establish SDG as a unified, instance-level interface for diagnosing, evaluating, and enhancing modern generative models.
GazeOnce360: Fisheye-Based 360° Multi-Person Gaze Estimation with Global-Local Feature Fusion
Mar 17, 2026We present GazeOnce360, a novel end-to-end model for multi-person gaze estimation from a single tabletop-mounted upward-facing fisheye camera. Unlike conventional approaches that rely on forward-facing cameras in constrained viewpoints, we address the underexplored setting of estimating the 3D gaze direction of multiple people distributed across a 360° scene from an upward fisheye perspective. To support research in this setting, we introduce MPSGaze360, a large-scale synthetic dataset rendered using Unreal Engine, featuring diverse multi-person configurations with accurate 3D gaze and eye landmark annotations. Our model tackles the severe distortion and perspective variation inherent in fisheye imagery by incorporating rotational convolutions and eye landmark supervision. To better capture fine-grained eye features crucial for gaze estimation, we propose a dual-resolution architecture that fuses global low-resolution context with high-resolution local eye regions. Experimental results demonstrate the effectiveness of each component in our model. This work highlights the feasibility and potential of fisheye-based 360° gaze estimation in practical multi-person scenarios. Project page: https://caizhuojiang.github.io/GazeOnce360/.
Requesting Expert Reasoning: Augmenting LLM Agents with Learned Collaborative Intervention
Feb 26, 2026Large Language Model (LLM) based agents excel at general reasoning but often fail in specialized domains where success hinges on long-tail knowledge absent from their training data. While human experts can provide this missing knowledge, their guidance is often unstructured and unreliable, making its direct integration into an agent's plan problematic. To address this, we introduce AHCE (Active Human-Augmented Challenge Engagement), a framework for on-demand Human-AI collaboration. At its core, the Human Feedback Module (HFM) employs a learned policy to treat the human expert as an interactive reasoning tool. Extensive experiments in Minecraft demonstrate the framework's effectiveness, increasing task success rates by 32% on normal difficulty tasks and nearly 70% on highly difficult tasks, all with minimal human intervention. Our work demonstrates that successfully augmenting agents requires learning how to request expert reasoning, moving beyond simple requests for help.
Towards Implicit Aggregation: Robust Image Representation for Place Recognition in the Transformer Era
Nov 08, 2025Visual place recognition (VPR) is typically regarded as a specific image retrieval task, whose core lies in representing images as global descriptors. Over the past decade, dominant VPR methods (e.g., NetVLAD) have followed a paradigm that first extracts the patch features/tokens of the input image using a backbone, and then aggregates these patch features into a global descriptor via an aggregator. This backbone-plus-aggregator paradigm has achieved overwhelming dominance in the CNN era and remains widely used in transformer-based models. In this paper, however, we argue that a dedicated aggregator is not necessary in the transformer era, that is, we can obtain robust global descriptors only with the backbone. Specifically, we introduce some learnable aggregation tokens, which are prepended to the patch tokens before a particular transformer block. All these tokens will be jointly processed and interact globally via the intrinsic self-attention mechanism, implicitly aggregating useful information within the patch tokens to the aggregation tokens. Finally, we only take these aggregation tokens from the last output tokens and concatenate them as the global representation. Although implicit aggregation can provide robust global descriptors in an extremely simple manner, where and how to insert additional tokens, as well as the initialization of tokens, remains an open issue worthy of further exploration. To this end, we also propose the optimal token insertion strategy and token initialization method derived from empirical studies. Experimental results show that our method outperforms state-of-the-art methods on several VPR datasets with higher efficiency and ranks 1st on the MSLS challenge leaderboard. The code is available at https://github.com/lu-feng/image.
Enhancing Sa2VA for Referent Video Object Segmentation: 2nd Solution for 7th LSVOS RVOS Track
Sep 19, 2025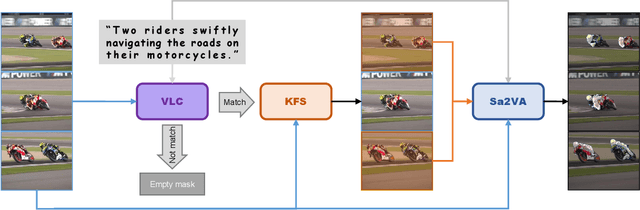
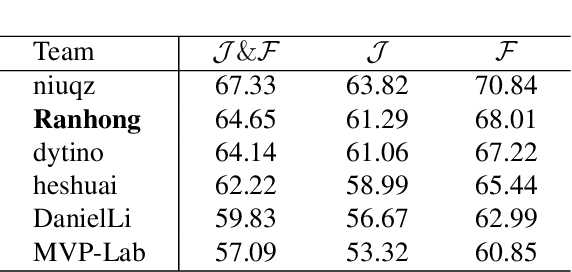

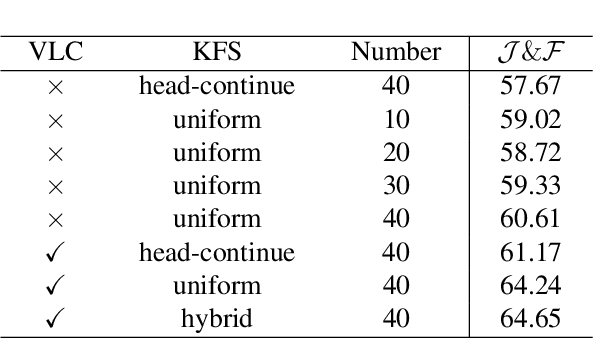
Referential Video Object Segmentation (RVOS) aims to segment all objects in a video that match a given natural language description, bridging the gap between vision and language understanding. Recent work, such as Sa2VA, combines Large Language Models (LLMs) with SAM~2, leveraging the strong video reasoning capability of LLMs to guide video segmentation. In this work, we present a training-free framework that substantially improves Sa2VA's performance on the RVOS task. Our method introduces two key components: (1) a Video-Language Checker that explicitly verifies whether the subject and action described in the query actually appear in the video, thereby reducing false positives; and (2) a Key-Frame Sampler that adaptively selects informative frames to better capture both early object appearances and long-range temporal context. Without any additional training, our approach achieves a J&F score of 64.14% on the MeViS test set, ranking 2nd place in the RVOS track of the 7th LSVOS Challenge at ICCV 2025.
Pseudo-Label Enhanced Cascaded Framework: 2nd Technical Report for LSVOS 2025 VOS Track
Sep 18, 2025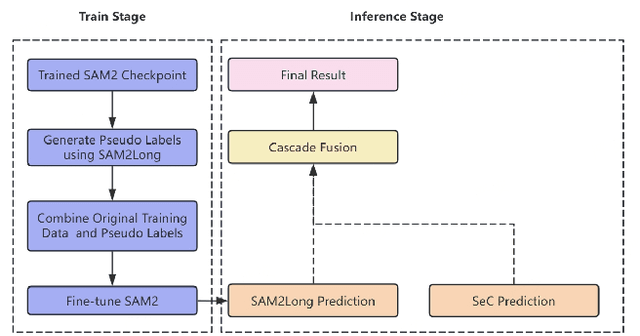



Complex Video Object Segmentation (VOS) presents significant challenges in accurately segmenting objects across frames, especially in the presence of small and similar targets, frequent occlusions, rapid motion, and complex interactions. In this report, we present our solution for the LSVOS 2025 VOS Track based on the SAM2 framework. We adopt a pseudo-labeling strategy during training: a trained SAM2 checkpoint is deployed within the SAM2Long framework to generate pseudo labels for the MOSE test set, which are then combined with existing data for further training. For inference, the SAM2Long framework is employed to obtain our primary segmentation results, while an open-source SeC model runs in parallel to produce complementary predictions. A cascaded decision mechanism dynamically integrates outputs from both models, exploiting the temporal stability of SAM2Long and the concept-level robustness of SeC. Benefiting from pseudo-label training and cascaded multi-model inference, our approach achieves a J\&F score of 0.8616 on the MOSE test set -- +1.4 points over our SAM2Long baseline -- securing the 2nd place in the LSVOS 2025 VOS Track, and demonstrating strong robustness and accuracy in long, complex video segmentation scenarios.
In the Eye of MLLM: Benchmarking Egocentric Video Intent Understanding with Gaze-Guided Prompting
Sep 09, 2025The emergence of advanced multimodal large language models (MLLMs) has significantly enhanced AI assistants' ability to process complex information across modalities. Recently, egocentric videos, by directly capturing user focus, actions, and context in an unified coordinate, offer an exciting opportunity to enable proactive and personalized AI user experiences with MLLMs. However, existing benchmarks overlook the crucial role of gaze as an indicator of user intent. To address this gap, we introduce EgoGazeVQA, an egocentric gaze-guided video question answering benchmark that leverages gaze information to improve the understanding of longer daily-life videos. EgoGazeVQA consists of gaze-based QA pairs generated by MLLMs and refined by human annotators. Our experiments reveal that existing MLLMs struggle to accurately interpret user intentions. In contrast, our gaze-guided intent prompting methods significantly enhance performance by integrating spatial, temporal, and intent-related cues. We further conduct experiments on gaze-related fine-tuning and analyze how gaze estimation accuracy impacts prompting effectiveness. These results underscore the value of gaze for more personalized and effective AI assistants in egocentric settings.
SelaVPR++: Towards Seamless Adaptation of Foundation Models for Efficient Place Recognition
Feb 23, 2025Recent studies show that the visual place recognition (VPR) method using pre-trained visual foundation models can achieve promising performance. In our previous work, we propose a novel method to realize seamless adaptation of foundation models to VPR (SelaVPR). This method can produce both global and local features that focus on discriminative landmarks to recognize places for two-stage VPR by a parameter-efficient adaptation approach. Although SelaVPR has achieved competitive results, we argue that the previous adaptation is inefficient in training time and GPU memory usage, and the re-ranking paradigm is also costly in retrieval latency and storage usage. In pursuit of higher efficiency and better performance, we propose an extension of the SelaVPR, called SelaVPR++. Concretely, we first design a parameter-, time-, and memory-efficient adaptation method that uses lightweight multi-scale convolution (MultiConv) adapters to refine intermediate features from the frozen foundation backbone. This adaptation method does not back-propagate gradients through the backbone during training, and the MultiConv adapter facilitates feature interactions along the spatial axes and introduces proper local priors, thus achieving higher efficiency and better performance. Moreover, we propose an innovative re-ranking paradigm for more efficient VPR. Instead of relying on local features for re-ranking, which incurs huge overhead in latency and storage, we employ compact binary features for initial retrieval and robust floating-point (global) features for re-ranking. To obtain such binary features, we propose a similarity-constrained deep hashing method, which can be easily integrated into the VPR pipeline. Finally, we improve our training strategy and unify the training protocol of several common training datasets to merge them for better training of VPR models. Extensive experiments show that ......
3D Prior is All You Need: Cross-Task Few-shot 2D Gaze Estimation
Feb 06, 20253D and 2D gaze estimation share the fundamental objective of capturing eye movements but are traditionally treated as two distinct research domains. In this paper, we introduce a novel cross-task few-shot 2D gaze estimation approach, aiming to adapt a pre-trained 3D gaze estimation network for 2D gaze prediction on unseen devices using only a few training images. This task is highly challenging due to the domain gap between 3D and 2D gaze, unknown screen poses, and limited training data. To address these challenges, we propose a novel framework that bridges the gap between 3D and 2D gaze. Our framework contains a physics-based differentiable projection module with learnable parameters to model screen poses and project 3D gaze into 2D gaze. The framework is fully differentiable and can integrate into existing 3D gaze networks without modifying their original architecture. Additionally, we introduce a dynamic pseudo-labelling strategy for flipped images, which is particularly challenging for 2D labels due to unknown screen poses. To overcome this, we reverse the projection process by converting 2D labels to 3D space, where flipping is performed. Notably, this 3D space is not aligned with the camera coordinate system, so we learn a dynamic transformation matrix to compensate for this misalignment. We evaluate our method on MPIIGaze, EVE, and GazeCapture datasets, collected respectively on laptops, desktop computers, and mobile devices. The superior performance highlights the effectiveness of our approach, and demonstrates its strong potential for real-world applications.