 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMPhysVideo: Scaling Physical Plausibility in Video Generation via Joint Multimodal Modeling
Apr 03, 2026Despite advancements in generating visually stunning content, video diffusion models (VDMs) often yield physically inconsistent results due to pixel-only reconstruction. To address this, we propose MMPhysVideo, the first framework to scale physical plausibility in video generation through joint multimodal modeling. We recast perceptual cues, specifically semantics, geometry, and spatio-temporal trajectory, into a unified pseudo-RGB format, enabling VDMs to directly capture complex physical dynamics. To mitigate cross-modal interference, we propose a Bidirectionally Controlled Teacher architecture, which utilizes parallel branches to fully decouple RGB and perception processing and adopts two zero-initialized control links to gradually learn pixel-wise consistency. For inference efficiency, the teacher's physical prior is distilled into a single-stream student model via representation alignment. Furthermore, we present MMPhysPipe, a scalable data curation and annotation pipeline tailored for constructing physics-rich multimodal datasets. MMPhysPipe employs a vision-language model (VLM) guided by a chain-of-visual-evidence rule to pinpoint physical subjects, enabling expert models to extract multi-granular perceptual information. Without additional inference costs, MMPhysVideo consistently improves physical plausibility and visual quality over advanced models across various benchmarks and achieves state-of-the-art performance compared to existing methods.
GEditBench v2: A Human-Aligned Benchmark for General Image Editing
Mar 30, 2026Recent advances in image editing have enabled models to handle complex instructions with impressive realism. However, existing evaluation frameworks lag behind: current benchmarks suffer from narrow task coverage, while standard metrics fail to adequately capture visual consistency, i.e., the preservation of identity, structure and semantic coherence between edited and original images. To address these limitations, we introduce GEditBench v2, a comprehensive benchmark with 1,200 real-world user queries spanning 23 tasks, including a dedicated open-set category for unconstrained, out-of-distribution editing instructions beyond predefined tasks. Furthermore, we propose PVC-Judge, an open-source pairwise assessment model for visual consistency, trained via two novel region-decoupled preference data synthesis pipelines. Besides, we construct VCReward-Bench using expert-annotated preference pairs to assess the alignment of PVC-Judge with human judgments on visual consistency evaluation. Experiments show that our PVC-Judge achieves state-of-the-art evaluation performance among open-source models and even surpasses GPT-5.1 on average. Finally, by benchmarking 16 frontier editing models, we show that GEditBench v2 enables more human-aligned evaluation, revealing critical limitations of current models, and providing a reliable foundation for advancing precise image editing.
Dropping Anchor and Spherical Harmonics for Sparse-view Gaussian Splatting
Feb 24, 2026Recent 3D Gaussian Splatting (3DGS) Dropout methods address overfitting under sparse-view conditions by randomly nullifying Gaussian opacities. However, we identify a neighbor compensation effect in these approaches: dropped Gaussians are often compensated by their neighbors, weakening the intended regularization. Moreover, these methods overlook the contribution of high-degree spherical harmonic coefficients (SH) to overfitting. To address these issues, we propose DropAnSH-GS, a novel anchor-based Dropout strategy. Rather than dropping Gaussians independently, our method randomly selects certain Gaussians as anchors and simultaneously removes their spatial neighbors. This effectively disrupts local redundancies near anchors and encourages the model to learn more robust, globally informed representations. Furthermore, we extend the Dropout to color attributes by randomly dropping higher-degree SH to concentrate appearance information in lower-degree SH. This strategy further mitigates overfitting and enables flexible post-training model compression via SH truncation. Experimental results demonstrate that DropAnSH-GS substantially outperforms existing Dropout methods with negligible computational overhead, and can be readily integrated into various 3DGS variants to enhance their performances. Project Website: https://sk-fun.fun/DropAnSH-GS
IGGT: Instance-Grounded Geometry Transformer for Semantic 3D Reconstruction
Oct 26, 2025Humans naturally perceive the geometric structure and semantic content of a 3D world as intertwined dimensions, enabling coherent and accurate understanding of complex scenes. However, most prior approaches prioritize training large geometry models for low-level 3D reconstruction and treat high-level spatial understanding in isolation, overlooking the crucial interplay between these two fundamental aspects of 3D-scene analysis, thereby limiting generalization and leading to poor performance in downstream 3D understanding tasks. Recent attempts have mitigated this issue by simply aligning 3D models with specific language models, thus restricting perception to the aligned model's capacity and limiting adaptability to downstream tasks. In this paper, we propose InstanceGrounded Geometry Transformer (IGGT), an end-to-end large unified transformer to unify the knowledge for both spatial reconstruction and instance-level contextual understanding. Specifically, we design a 3D-Consistent Contrastive Learning strategy that guides IGGT to encode a unified representation with geometric structures and instance-grounded clustering through only 2D visual inputs. This representation supports consistent lifting of 2D visual inputs into a coherent 3D scene with explicitly distinct object instances. To facilitate this task, we further construct InsScene-15K, a large-scale dataset with high-quality RGB images, poses, depth maps, and 3D-consistent instance-level mask annotations with a novel data curation pipeline.
ViStoryBench: Comprehensive Benchmark Suite for Story Visualization
May 30, 2025Story visualization, which aims to generate a sequence of visually coherent images aligning with a given narrative and reference images, has seen significant progress with recent advancements in generative models. To further enhance the performance of story visualization frameworks in real-world scenarios, we introduce a comprehensive evaluation benchmark, ViStoryBench. We collect a diverse dataset encompassing various story types and artistic styles, ensuring models are evaluated across multiple dimensions such as different plots (e.g., comedy, horror) and visual aesthetics (e.g., anime, 3D renderings). ViStoryBench is carefully curated to balance narrative structures and visual elements, featuring stories with single and multiple protagonists to test models' ability to maintain character consistency. Additionally, it includes complex plots and intricate world-building to challenge models in generating accurate visuals. To ensure comprehensive comparisons, our benchmark incorporates a wide range of evaluation metrics assessing critical aspects. This structured and multifaceted framework enables researchers to thoroughly identify both the strengths and weaknesses of different models, fostering targeted improvements.
Step1X-3D: Towards High-Fidelity and Controllable Generation of Textured 3D Assets
May 12, 2025While generative artificial intelligence has advanced significantly across text, image, audio, and video domains, 3D generation remains comparatively underdeveloped due to fundamental challenges such as data scarcity, algorithmic limitations, and ecosystem fragmentation. To this end, we present Step1X-3D, an open framework addressing these challenges through: (1) a rigorous data curation pipeline processing >5M assets to create a 2M high-quality dataset with standardized geometric and textural properties; (2) a two-stage 3D-native architecture combining a hybrid VAE-DiT geometry generator with an diffusion-based texture synthesis module; and (3) the full open-source release of models, training code, and adaptation modules. For geometry generation, the hybrid VAE-DiT component produces TSDF representations by employing perceiver-based latent encoding with sharp edge sampling for detail preservation. The diffusion-based texture synthesis module then ensures cross-view consistency through geometric conditioning and latent-space synchronization. Benchmark results demonstrate state-of-the-art performance that exceeds existing open-source methods, while also achieving competitive quality with proprietary solutions. Notably, the framework uniquely bridges the 2D and 3D generation paradigms by supporting direct transfer of 2D control techniques~(e.g., LoRA) to 3D synthesis. By simultaneously advancing data quality, algorithmic fidelity, and reproducibility, Step1X-3D aims to establish new standards for open research in controllable 3D asset generation.
StyleMe3D: Stylization with Disentangled Priors by Multiple Encoders on 3D Gaussians
Apr 21, 20253D Gaussian Splatting (3DGS) excels in photorealistic scene reconstruction but struggles with stylized scenarios (e.g., cartoons, games) due to fragmented textures, semantic misalignment, and limited adaptability to abstract aesthetics. We propose StyleMe3D, a holistic framework for 3D GS style transfer that integrates multi-modal style conditioning, multi-level semantic alignment, and perceptual quality enhancement. Our key insights include: (1) optimizing only RGB attributes preserves geometric integrity during stylization; (2) disentangling low-, medium-, and high-level semantics is critical for coherent style transfer; (3) scalability across isolated objects and complex scenes is essential for practical deployment. StyleMe3D introduces four novel components: Dynamic Style Score Distillation (DSSD), leveraging Stable Diffusion's latent space for semantic alignment; Contrastive Style Descriptor (CSD) for localized, content-aware texture transfer; Simultaneously Optimized Scale (SOS) to decouple style details and structural coherence; and 3D Gaussian Quality Assessment (3DG-QA), a differentiable aesthetic prior trained on human-rated data to suppress artifacts and enhance visual harmony. Evaluated on NeRF synthetic dataset (objects) and tandt db (scenes) datasets, StyleMe3D outperforms state-of-the-art methods in preserving geometric details (e.g., carvings on sculptures) and ensuring stylistic consistency across scenes (e.g., coherent lighting in landscapes), while maintaining real-time rendering. This work bridges photorealistic 3D GS and artistic stylization, unlocking applications in gaming, virtual worlds, and digital art.
InstructLayout: Instruction-Driven 2D and 3D Layout Synthesis with Semantic Graph Prior
Jul 11, 2024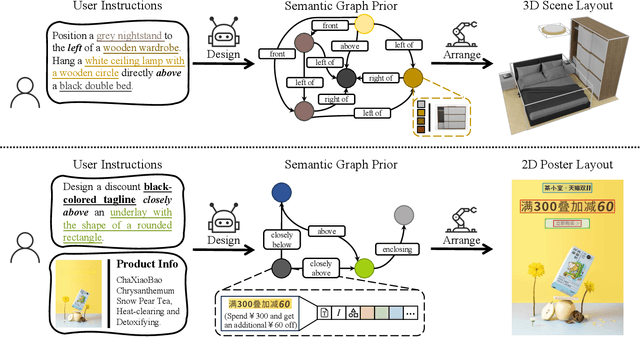
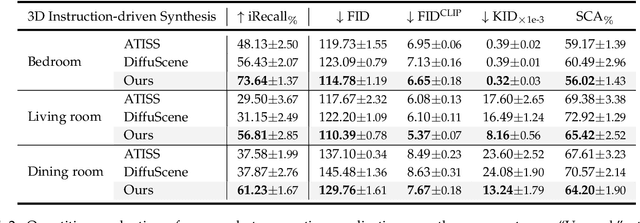
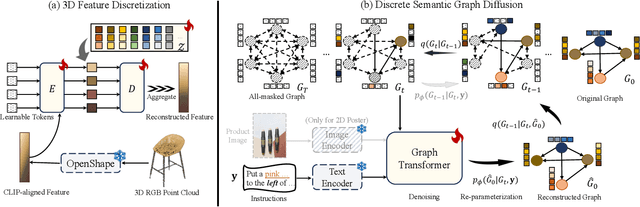
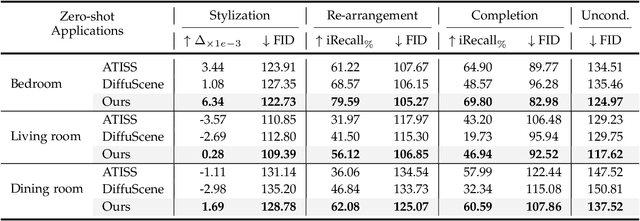
Comprehending natural language instructions is a charming property for both 2D and 3D layout synthesis systems. Existing methods implicitly model object joint distributions and express object relations, hindering generation's controllability. We introduce InstructLayout, a novel generative framework that integrates a semantic graph prior and a layout decoder to improve controllability and fidelity for 2D and 3D layout synthesis. The proposed semantic graph prior learns layout appearances and object distributions simultaneously, demonstrating versatility across various downstream tasks in a zero-shot manner. To facilitate the benchmarking for text-driven 2D and 3D scene synthesis, we respectively curate two high-quality datasets of layout-instruction pairs from public Internet resources with large language and multimodal models. Extensive experimental results reveal that the proposed method outperforms existing state-of-the-art approaches by a large margin in both 2D and 3D layout synthesis tasks. Thorough ablation studies confirm the efficacy of crucial design components.
4K4DGen: Panoramic 4D Generation at 4K Resolution
Jun 19, 2024
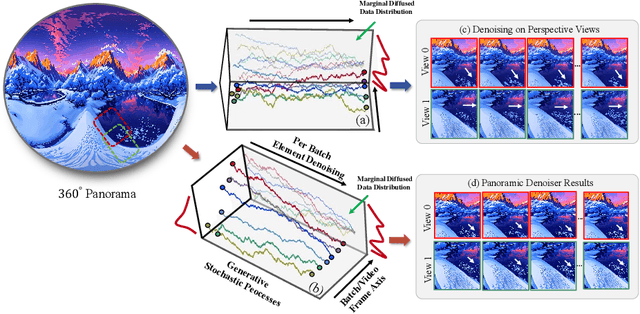

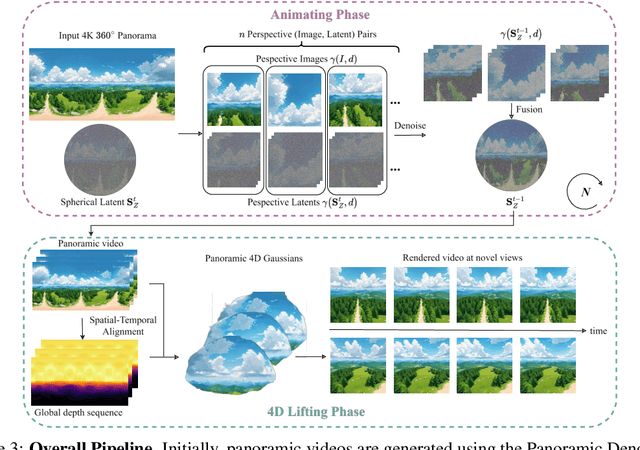
The blooming of virtual reality and augmented reality (VR/AR) technologies has driven an increasing demand for the creation of high-quality, immersive, and dynamic environments. However, existing generative techniques either focus solely on dynamic objects or perform outpainting from a single perspective image, failing to meet the needs of VR/AR applications. In this work, we tackle the challenging task of elevating a single panorama to an immersive 4D experience. For the first time, we demonstrate the capability to generate omnidirectional dynamic scenes with 360-degree views at 4K resolution, thereby providing an immersive user experience. Our method introduces a pipeline that facilitates natural scene animations and optimizes a set of 4D Gaussians using efficient splatting techniques for real-time exploration. To overcome the lack of scene-scale annotated 4D data and models, especially in panoramic formats, we propose a novel Panoramic Denoiser that adapts generic 2D diffusion priors to animate consistently in 360-degree images, transforming them into panoramic videos with dynamic scenes at targeted regions. Subsequently, we elevate the panoramic video into a 4D immersive environment while preserving spatial and temporal consistency. By transferring prior knowledge from 2D models in the perspective domain to the panoramic domain and the 4D lifting with spatial appearance and geometry regularization, we achieve high-quality Panorama-to-4D generation at a resolution of (4096 $\times$ 2048) for the first time. See the project website at https://4k4dgen.github.io.
Benchmarks and Challenges in Pose Estimation for Egocentric Hand Interactions with Objects
Mar 25, 2024
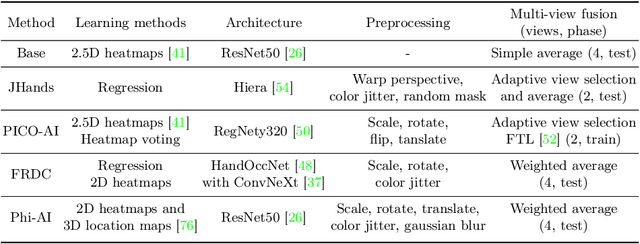
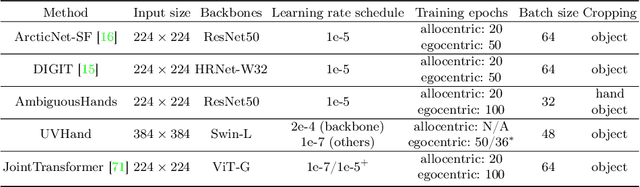
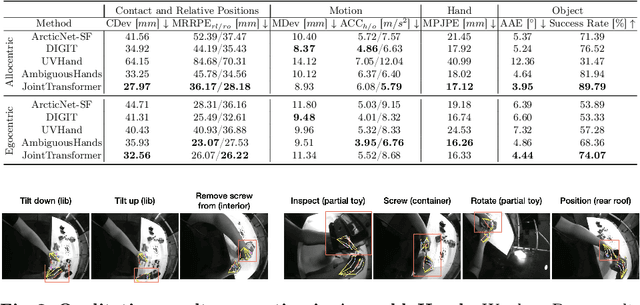
We interact with the world with our hands and see it through our own (egocentric) perspective. A holistic 3D understanding of such interactions from egocentric views is important for tasks in robotics, AR/VR, action recognition and motion generation. Accurately reconstructing such interactions in 3D is challenging due to heavy occlusion, viewpoint bias, camera distortion, and motion blur from the head movement. To this end, we designed the HANDS23 challenge based on the AssemblyHands and ARCTIC datasets with carefully designed training and testing splits. Based on the results of the top submitted methods and more recent baselines on the leaderboards, we perform a thorough analysis on 3D hand(-object) reconstruction tasks. Our analysis demonstrates the effectiveness of addressing distortion specific to egocentric cameras, adopting high-capacity transformers to learn complex hand-object interactions, and fusing predictions from different views. Our study further reveals challenging scenarios intractable with state-of-the-art methods, such as fast hand motion, object reconstruction from narrow egocentric views, and close contact between two hands and objects. Our efforts will enrich the community's knowledge foundation and facilitate future hand studies on egocentric hand-object interactions.