 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegression generation adversarial network based on dual data evaluation strategy for industrial application
Dec 22, 2025Soft sensing infers hard-to-measure data through a large number of easily obtainable variables. However, in complex industrial scenarios, the issue of insufficient data volume persists, which diminishes the reliability of soft sensing. Generative Adversarial Networks (GAN) are one of the effective solutions for addressing insufficient samples. Nevertheless, traditional GAN fail to account for the mapping relationship between labels and features, which limits further performance improvement. Although some studies have proposed solutions, none have considered both performance and efficiency simultaneously. To address these problems, this paper proposes the multi-task learning-based regression GAN framework that integrates regression information into both the discriminator and generator, and implements a shallow sharing mechanism between the discriminator and regressor. This approach significantly enhances the quality of generated samples while improving the algorithm's operational efficiency. Moreover, considering the importance of training samples and generated samples, a dual data evaluation strategy is designed to make GAN generate more diverse samples, thereby increasing the generalization of subsequent modeling. The superiority of method is validated through four classic industrial soft sensing cases: wastewater treatment plants, surface water, $CO_2$ absorption towers, and industrial gas turbines.
Contrast and Clustering: Learning Neighborhood Pair Representation for Source-free Domain Adaptation
Jan 31, 2023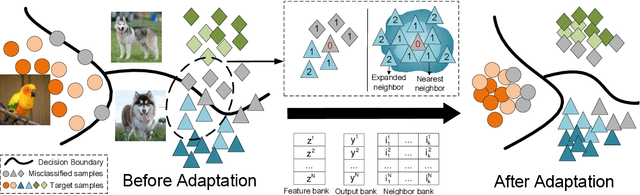

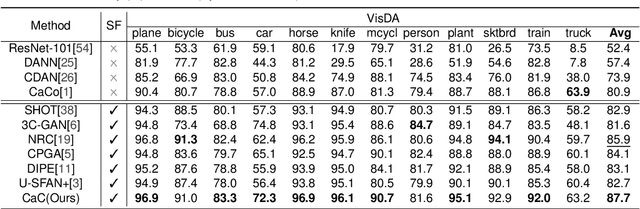
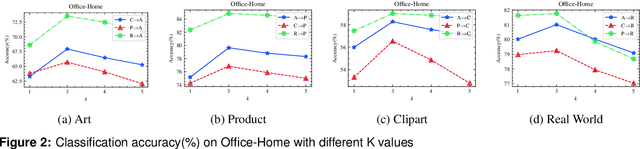
Domain adaptation has attracted a great deal of attention in the machine learning community, but it requires access to source data, which often raises concerns about data privacy. We are thus motivated to address these issues and propose a simple yet efficient method. This work treats domain adaptation as an unsupervised clustering problem and trains the target model without access to the source data. Specifically, we propose a loss function called contrast and clustering (CaC), where a positive pair term pulls neighbors belonging to the same class together in the feature space to form clusters, while a negative pair term pushes samples of different classes apart. In addition, extended neighbors are taken into account by querying the nearest neighbor indexes in the memory bank to mine for more valuable negative pairs. Extensive experiments on three common benchmarks, VisDA, Office-Home and Office-31, demonstrate that our method achieves state-of-the-art performance. The code will be made publicly available at https://github.com/yukilulu/CaC.
A Method For Eliminating Contour Errors In Self-Encoder Reconstructed Images
Jan 25, 2023In this paper, we propose a self-supervised twin network approach based on this a priori. The method of generating the approximate10 edge information of an image and then differentially eliminating the edge errors11 in the reconstructed image with a dilate algorithm. This is used to improve the12 accuracy of the reconstructed image and to separate foreign matter and noise from13 the original image, so that it can be visualized in a more practical scene
Differentiable Architecture Search with Random Features
Aug 18, 2022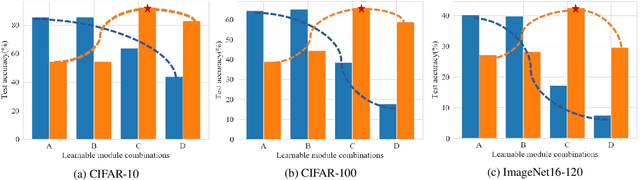

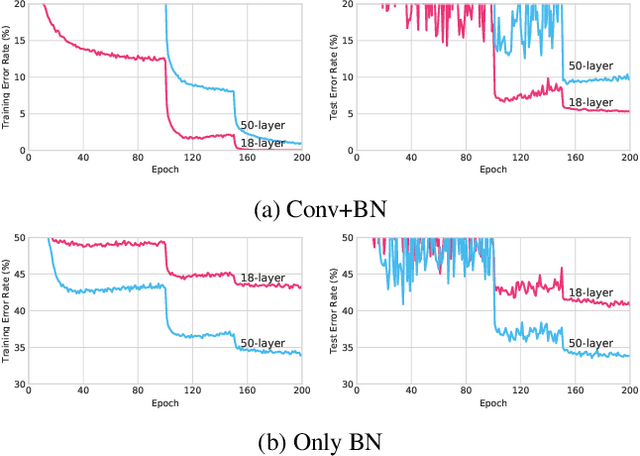
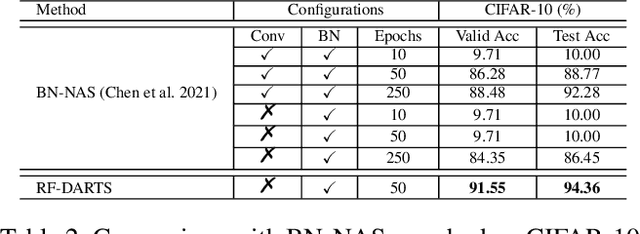
Differentiable architecture search (DARTS) has significantly promoted the development of NAS techniques because of its high search efficiency and effectiveness but suffers from performance collapse. In this paper, we make efforts to alleviate the performance collapse problem for DARTS from two aspects. First, we investigate the expressive power of the supernet in DARTS and then derive a new setup of DARTS paradigm with only training BatchNorm. Second, we theoretically find that random features dilute the auxiliary connection role of skip-connection in supernet optimization and enable search algorithm focus on fairer operation selection, thereby solving the performance collapse problem. We instantiate DARTS and PC-DARTS with random features to build an improved version for each named RF-DARTS and RF-PCDARTS respectively. Experimental results show that RF-DARTS obtains \textbf{94.36\%} test accuracy on CIFAR-10 (which is the nearest optimal result in NAS-Bench-201), and achieves the newest state-of-the-art top-1 test error of \textbf{24.0\%} on ImageNet when transferring from CIFAR-10. Moreover, RF-DARTS performs robustly across three datasets (CIFAR-10, CIFAR-100, and SVHN) and four search spaces (S1-S4). Besides, RF-PCDARTS achieves even better results on ImageNet, that is, \textbf{23.9\%} top-1 and \textbf{7.1\%} top-5 test error, surpassing representative methods like single-path, training-free, and partial-channel paradigms directly searched on ImageNet.
DADA: Differentiable Automatic Data Augmentation
Mar 28, 2020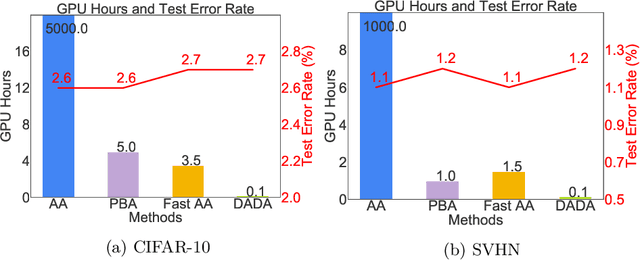

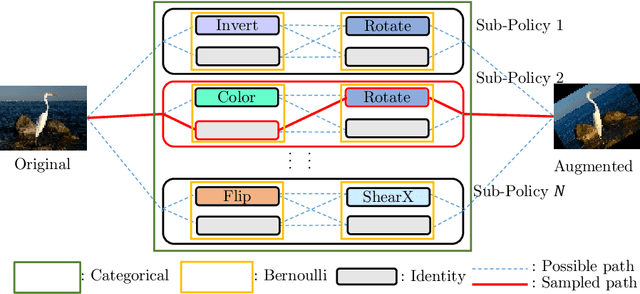
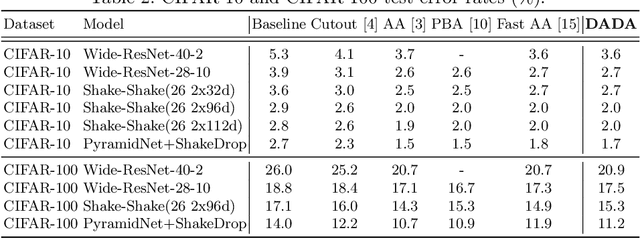
Data augmentation (DA) techniques aim to increase data variability, and thus train deep networks with better generalisation. The pioneering AutoAugment automated the search for optimal DA policies with reinforcement learning. However, AutoAugment is extremely computationally expensive, limiting its wide applicability. Followup work such as PBA and Fast AutoAugment improved efficiency, but optimization speed remains a bottleneck. In this paper, we propose Differentiable Automatic Data Augmentation (DADA) which dramatically reduces the cost. DADA relaxes the discrete DA policy selection to a differentiable optimization problem via Gumbel-Softmax. In addition, we introduce an unbiased gradient estimator, RELAX, leading to an efficient and effective one-pass optimization strategy to learn an efficient and accurate DA policy. We conduct extensive experiments on CIFAR-10, CIFAR-100, SVHN, and ImageNet datasets. Furthermore, we demonstrate the value of Auto DA in pre-training for downstream detection problems. Results show our DADA is at least one order of magnitude faster than the state-of-the-art while achieving very comparable accuracy.