 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrast and Clustering: Learning Neighborhood Pair Representation for Source-free Domain Adaptation
Jan 31, 2023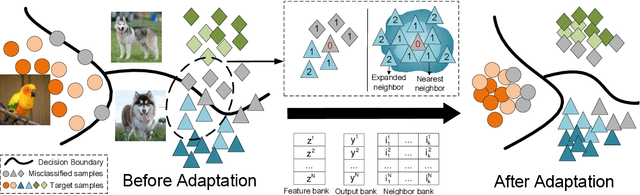

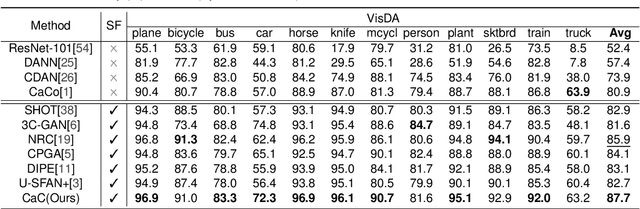
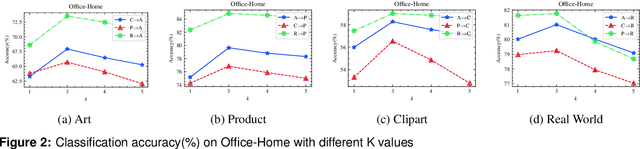
Domain adaptation has attracted a great deal of attention in the machine learning community, but it requires access to source data, which often raises concerns about data privacy. We are thus motivated to address these issues and propose a simple yet efficient method. This work treats domain adaptation as an unsupervised clustering problem and trains the target model without access to the source data. Specifically, we propose a loss function called contrast and clustering (CaC), where a positive pair term pulls neighbors belonging to the same class together in the feature space to form clusters, while a negative pair term pushes samples of different classes apart. In addition, extended neighbors are taken into account by querying the nearest neighbor indexes in the memory bank to mine for more valuable negative pairs. Extensive experiments on three common benchmarks, VisDA, Office-Home and Office-31, demonstrate that our method achieves state-of-the-art performance. The code will be made publicly available at https://github.com/yukilulu/CaC.