 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMirrorLA: Reflecting Feature Map for Vision Linear Attention
Feb 04, 2026Linear attention significantly reduces the computational complexity of Transformers from quadratic to linear, yet it consistently lags behind softmax-based attention in performance. We identify the root cause of this degradation as the non-negativity constraint imposed on kernel feature maps: standard projections like ReLU act as "passive truncation" operators, indiscriminately discarding semantic information residing in the negative domain. We propose MirrorLA, a geometric framework that substitutes passive truncation with active reorientation. By leveraging learnable Householder reflections, MirrorLA rotates the feature geometry into the non-negative orthant to maximize information retention. Our approach restores representational density through a cohesive, multi-scale design: it first optimizes local discriminability via block-wise isometries, stabilizes long-context dynamics using variance-aware modulation to diversify activations, and finally, integrates dispersed subspaces via cross-head reflections to induce global covariance mixing. MirrorLA achieves state-of-the-art performance across standard benchmarks, demonstrating that strictly linear efficiency can be achieved without compromising representational fidelity.
STILL: Selecting Tokens for Intra-Layer Hybrid Attention to Linearize LLMs
Feb 02, 2026Linearizing pretrained large language models (LLMs) primarily relies on intra-layer hybrid attention mechanisms to alleviate the quadratic complexity of standard softmax attention. Existing methods perform token routing based on sliding-window partitions, resulting in position-based selection and fails to capture token-specific global importance. Meanwhile, linear attention further suffers from distribution shift caused by learnable feature maps that distort pretrained feature magnitudes. Motivated by these limitations, we propose STILL, an intra-layer hybrid linearization framework for efficiently linearizing LLMs. STILL introduces a Self-Saliency Score with strong local-global consistency, enabling accurate token selection using sliding-window computation, and retains salient tokens for sparse softmax attention while summarizing the remaining context via linear attention. To preserve pretrained representations, we design a Norm-Preserved Feature Map (NP-Map) that decouples feature direction from magnitude and reinjects pretrained norms. We further adopt a unified training-inference architecture with chunk-wise parallelization and delayed selection to improve hardware efficiency. Experiments show that STILL matches or surpasses the original pretrained model on commonsense and general reasoning tasks, and achieves up to a 86.2% relative improvement over prior linearized attention methods on long-context benchmarks.
Training-free Context-adaptive Attention for Efficient Long Context Modeling
Dec 10, 2025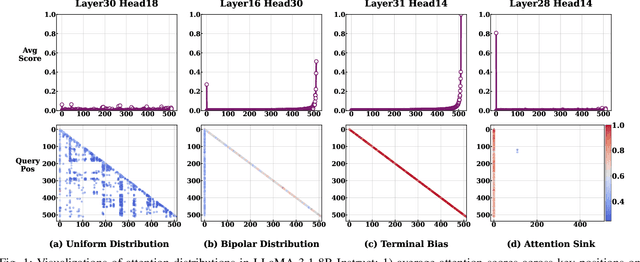
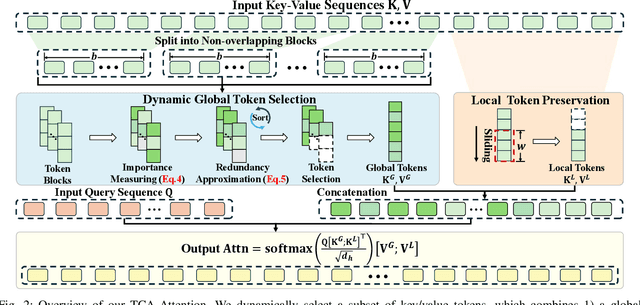
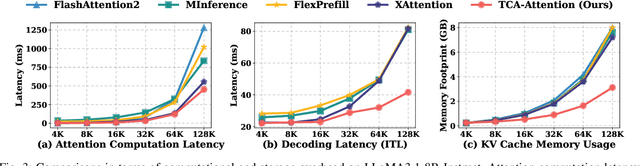
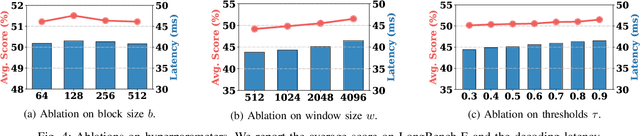
Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide range of natural language processing tasks. These capabilities stem primarily from the self-attention mechanism, which enables modeling of long-range dependencies. However, the quadratic complexity of self-attention with respect to sequence length poses significant computational and memory challenges, especially as sequence length extends to extremes. While various sparse attention and KV cache compression methods have been proposed to improve efficiency, they often suffer from limitations such as reliance on fixed patterns, inability to handle both prefilling and decoding stages, or the requirement for additional training. In this paper, we propose Training-free Context-adaptive Attention (TCA-Attention), a training-free sparse attention mechanism that selectively attends to only the informative tokens for efficient long-context inference. Our method consists of two lightweight phases: i) an offline calibration phase that determines head-specific sparsity budgets via a single forward pass, and ii) an online token selection phase that adaptively retains core context tokens using a lightweight redundancy metric. TCA-Attention provides a unified solution that accelerates both prefilling and decoding while reducing KV cache memory footprint, without requiring parameter updates or architectural changes. Theoretical analysis shows that our approach maintains bounded approximation error. Extensive experiments demonstrate that TCA-Attention achieves a 2.8$\times$ speedup and reduces KV cache by 61% at 128K context length while maintaining performance comparable to full attention across various benchmarks, offering a practical plug-and-play solution for efficient long-context inference.
Contrast and Clustering: Learning Neighborhood Pair Representation for Source-free Domain Adaptation
Jan 31, 2023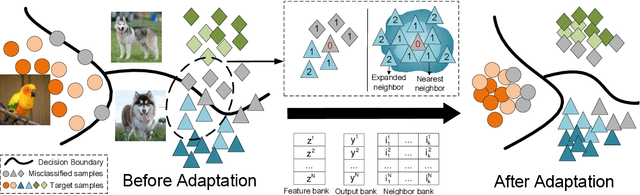

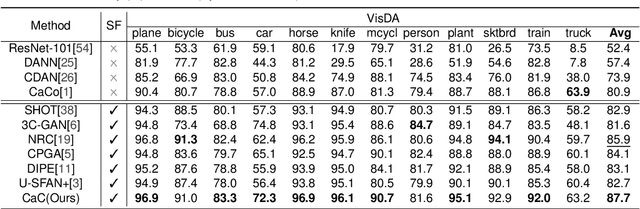
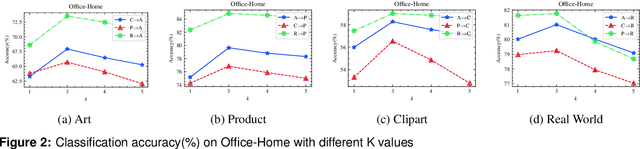
Domain adaptation has attracted a great deal of attention in the machine learning community, but it requires access to source data, which often raises concerns about data privacy. We are thus motivated to address these issues and propose a simple yet efficient method. This work treats domain adaptation as an unsupervised clustering problem and trains the target model without access to the source data. Specifically, we propose a loss function called contrast and clustering (CaC), where a positive pair term pulls neighbors belonging to the same class together in the feature space to form clusters, while a negative pair term pushes samples of different classes apart. In addition, extended neighbors are taken into account by querying the nearest neighbor indexes in the memory bank to mine for more valuable negative pairs. Extensive experiments on three common benchmarks, VisDA, Office-Home and Office-31, demonstrate that our method achieves state-of-the-art performance. The code will be made publicly available at https://github.com/yukilulu/CaC.