 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProCache: Constraint-Aware Feature Caching with Selective Computation for Diffusion Transformer Acceleration
Dec 19, 2025Diffusion Transformers (DiTs) have achieved state-of-the-art performance in generative modeling, yet their high computational cost hinders real-time deployment. While feature caching offers a promising training-free acceleration solution by exploiting temporal redundancy, existing methods suffer from two key limitations: (1) uniform caching intervals fail to align with the non-uniform temporal dynamics of DiT, and (2) naive feature reuse with excessively large caching intervals can lead to severe error accumulation. In this work, we analyze the evolution of DiT features during denoising and reveal that both feature changes and error propagation are highly time- and depth-varying. Motivated by this, we propose ProCache, a training-free dynamic feature caching framework that addresses these issues via two core components: (i) a constraint-aware caching pattern search module that generates non-uniform activation schedules through offline constrained sampling, tailored to the model's temporal characteristics; and (ii) a selective computation module that selectively computes within deep blocks and high-importance tokens for cached segments to mitigate error accumulation with minimal overhead. Extensive experiments on PixArt-alpha and DiT demonstrate that ProCache achieves up to 1.96x and 2.90x acceleration with negligible quality degradation, significantly outperforming prior caching-based methods.
Training-free Context-adaptive Attention for Efficient Long Context Modeling
Dec 10, 2025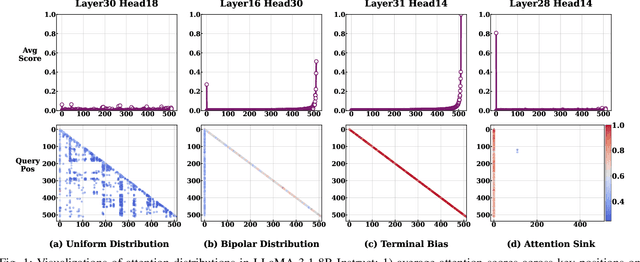
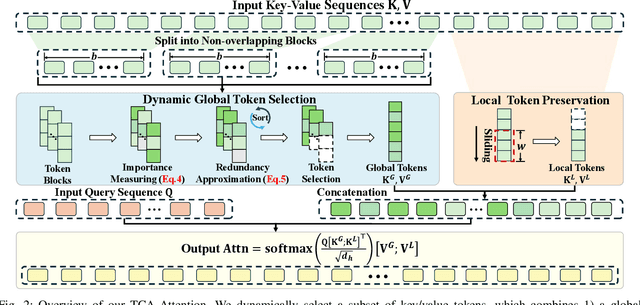
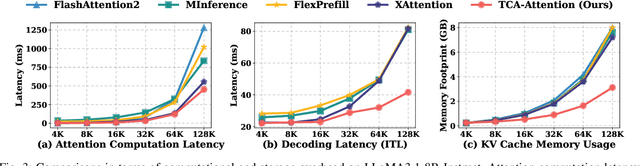
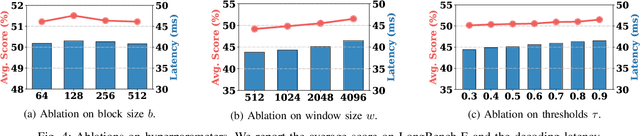
Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide range of natural language processing tasks. These capabilities stem primarily from the self-attention mechanism, which enables modeling of long-range dependencies. However, the quadratic complexity of self-attention with respect to sequence length poses significant computational and memory challenges, especially as sequence length extends to extremes. While various sparse attention and KV cache compression methods have been proposed to improve efficiency, they often suffer from limitations such as reliance on fixed patterns, inability to handle both prefilling and decoding stages, or the requirement for additional training. In this paper, we propose Training-free Context-adaptive Attention (TCA-Attention), a training-free sparse attention mechanism that selectively attends to only the informative tokens for efficient long-context inference. Our method consists of two lightweight phases: i) an offline calibration phase that determines head-specific sparsity budgets via a single forward pass, and ii) an online token selection phase that adaptively retains core context tokens using a lightweight redundancy metric. TCA-Attention provides a unified solution that accelerates both prefilling and decoding while reducing KV cache memory footprint, without requiring parameter updates or architectural changes. Theoretical analysis shows that our approach maintains bounded approximation error. Extensive experiments demonstrate that TCA-Attention achieves a 2.8$\times$ speedup and reduces KV cache by 61% at 128K context length while maintaining performance comparable to full attention across various benchmarks, offering a practical plug-and-play solution for efficient long-context inference.
Curse of High Dimensionality Issue in Transformer for Long-context Modeling
May 28, 2025Transformer-based large language models (LLMs) excel in natural language processing tasks by capturing long-range dependencies through self-attention mechanisms. However, long-context modeling faces significant computational inefficiencies due to \textit{redundant} attention computations: while attention weights are often \textit{sparse}, all tokens consume \textit{equal} computational resources. In this paper, we reformulate traditional probabilistic sequence modeling as a \textit{supervised learning task}, enabling the separation of relevant and irrelevant tokens and providing a clearer understanding of redundancy. Based on this reformulation, we theoretically analyze attention sparsity, revealing that only a few tokens significantly contribute to predictions. Building on this, we formulate attention optimization as a linear coding problem and propose a \textit{group coding strategy}, theoretically showing its ability to improve robustness against random noise and enhance learning efficiency. Motivated by this, we propose \textit{Dynamic Group Attention} (DGA), which leverages the group coding to explicitly reduce redundancy by aggregating less important tokens during attention computation. Empirical results show that our DGA significantly reduces computational costs while maintaining competitive performance.Code is available at https://github.com/bolixinyu/DynamicGroupAttention.
Core Context Aware Attention for Long Context Language Modeling
Dec 17, 2024



Transformer-based Large Language Models (LLMs) have exhibited remarkable success in various natural language processing tasks primarily attributed to self-attention mechanism, which requires a token to consider all preceding tokens as its context to compute the attention score. However, when the context length L becomes very large (e.g., 32K), more redundant context information will be included w.r.t. any tokens, making the self-attention suffer from two main limitations: 1) The computational and memory complexity scales quadratically w.r.t. L; 2) The presence of redundant context information may hamper the model to capture dependencies among crucial tokens, which may degrade the representation performance. In this paper, we propose a plug-and-play Core Context Aware (CCA) Attention for efficient long-range context modeling, which consists of two components: 1) Globality-pooling attention that divides input tokens into groups and then dynamically merges tokens within each group into one core token based on their significance; 2) Locality-preserved attention that incorporates neighboring tokens into the attention calculation. The two complementary attentions will then be fused to the final attention, maintaining comprehensive modeling ability as the full self-attention. In this way, the core context information w.r.t. a given token will be automatically focused and strengthened, while the context information in redundant groups will be diminished during the learning process. As a result, the computational and memory complexity will be significantly reduced. More importantly, the CCA-Attention can improve the long-context modeling ability by diminishing the redundant context information. Extensive experimental results demonstrate that our CCA-Attention significantly outperforms state-of-the-art models in terms of computational efficiency and long-context modeling ability.
Towards Long Video Understanding via Fine-detailed Video Story Generation
Dec 09, 2024



Long video understanding has become a critical task in computer vision, driving advancements across numerous applications from surveillance to content retrieval. Existing video understanding methods suffer from two challenges when dealing with long video understanding: intricate long-context relationship modeling and interference from redundancy. To tackle these challenges, we introduce Fine-Detailed Video Story generation (FDVS), which interprets long videos into detailed textual representations. Specifically, to achieve fine-grained modeling of long-temporal content, we propose a Bottom-up Video Interpretation Mechanism that progressively interprets video content from clips to video. To avoid interference from redundant information in videos, we introduce a Semantic Redundancy Reduction mechanism that removes redundancy at both the visual and textual levels. Our method transforms long videos into hierarchical textual representations that contain multi-granularity information of the video. With these representations, FDVS is applicable to various tasks without any fine-tuning. We evaluate the proposed method across eight datasets spanning three tasks. The performance demonstrates the effectiveness and versatility of our method.