 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Fast and Slow: Cognitive-Inspired Elastic Reasoning for Large Language Models
Dec 17, 2025Large language models (LLMs) have demonstrated impressive performance across various language tasks. However, existing LLM reasoning strategies mainly rely on the LLM itself with fast or slow mode (like o1 thinking) and thus struggle to balance reasoning efficiency and accuracy across queries of varying difficulties. In this paper, we propose Cognitive-Inspired Elastic Reasoning (CogER), a framework inspired by human hierarchical reasoning that dynamically selects the most suitable reasoning strategy for each query. Specifically, CogER first assesses the complexity of incoming queries and assigns them to one of several predefined levels, each corresponding to a tailored processing strategy, thereby addressing the challenge of unobservable query difficulty. To achieve automatic strategy selection, we model the process as a Markov Decision Process and train a CogER-Agent using reinforcement learning. The agent is guided by a reward function that balances solution quality and computational cost, ensuring resource-efficient reasoning. Moreover, for queries requiring external tools, we introduce Cognitive Tool-Assisted Reasoning, which enables the LLM to autonomously invoke external tools within its chain-of-thought. Extensive experiments demonstrate that CogER outperforms state-of-the-art Test-Time scaling methods, achieving at least a 13% relative improvement in average exact match on In-Domain tasks and an 8% relative gain on Out-of-Domain tasks.
Curse of High Dimensionality Issue in Transformer for Long-context Modeling
May 28, 2025Transformer-based large language models (LLMs) excel in natural language processing tasks by capturing long-range dependencies through self-attention mechanisms. However, long-context modeling faces significant computational inefficiencies due to \textit{redundant} attention computations: while attention weights are often \textit{sparse}, all tokens consume \textit{equal} computational resources. In this paper, we reformulate traditional probabilistic sequence modeling as a \textit{supervised learning task}, enabling the separation of relevant and irrelevant tokens and providing a clearer understanding of redundancy. Based on this reformulation, we theoretically analyze attention sparsity, revealing that only a few tokens significantly contribute to predictions. Building on this, we formulate attention optimization as a linear coding problem and propose a \textit{group coding strategy}, theoretically showing its ability to improve robustness against random noise and enhance learning efficiency. Motivated by this, we propose \textit{Dynamic Group Attention} (DGA), which leverages the group coding to explicitly reduce redundancy by aggregating less important tokens during attention computation. Empirical results show that our DGA significantly reduces computational costs while maintaining competitive performance.Code is available at https://github.com/bolixinyu/DynamicGroupAttention.
Test-Time Learning for Large Language Models
May 27, 2025
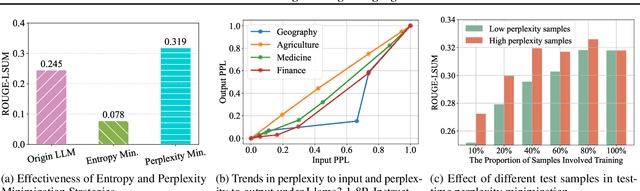
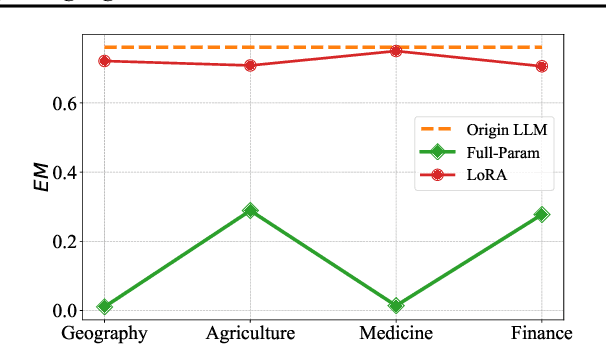
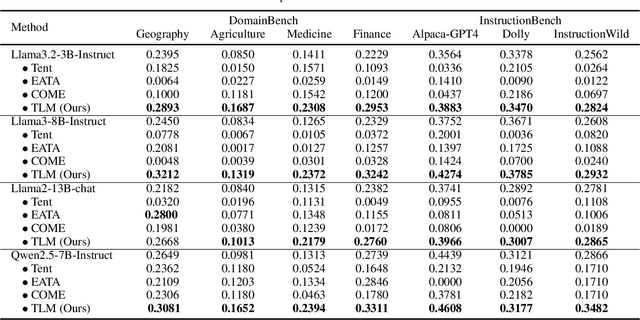
While Large Language Models (LLMs) have exhibited remarkable emergent capabilities through extensive pre-training, they still face critical limitations in generalizing to specialized domains and handling diverse linguistic variations, known as distribution shifts. In this paper, we propose a Test-Time Learning (TTL) paradigm for LLMs, namely TLM, which dynamically adapts LLMs to target domains using only unlabeled test data during testing. Specifically, we first provide empirical evidence and theoretical insights to reveal that more accurate predictions from LLMs can be achieved by minimizing the input perplexity of the unlabeled test data. Based on this insight, we formulate the Test-Time Learning process of LLMs as input perplexity minimization, enabling self-supervised enhancement of LLM performance. Furthermore, we observe that high-perplexity samples tend to be more informative for model optimization. Accordingly, we introduce a Sample Efficient Learning Strategy that actively selects and emphasizes these high-perplexity samples for test-time updates. Lastly, to mitigate catastrophic forgetting and ensure adaptation stability, we adopt Low-Rank Adaptation (LoRA) instead of full-parameter optimization, which allows lightweight model updates while preserving more original knowledge from the model. We introduce the AdaptEval benchmark for TTL and demonstrate through experiments that TLM improves performance by at least 20% compared to original LLMs on domain knowledge adaptation.
Easing Seasickness through Attention Redirection with a Mindfulness-Based Brain--Computer Interface
Jan 15, 2025Seasickness is a prevalent issue that adversely impacts both passenger experiences and the operational efficiency of maritime crews. While techniques that redirect attention have proven effective in alleviating motion sickness symptoms in terrestrial environments, applying similar strategies to manage seasickness poses unique challenges due to the prolonged and intense motion environment associated with maritime travel. In this study, we propose a mindfulness brain-computer interface (BCI), specifically designed to redirect attention with the aim of mitigating seasickness symptoms in real-world settings. Our system utilizes a single-channel headband to capture prefrontal EEG signals, which are then wirelessly transmitted to computing devices for the assessment of mindfulness states. The results are transferred into real-time feedback as mindfulness scores and audiovisual stimuli, facilitating a shift in attentional focus from physiological discomfort to mindfulness practices. A total of 43 individuals participated in a real-world maritime experiment consisted of three sessions: a real-feedback mindfulness session, a resting session, and a pseudofeedback mindfulness session. Notably, 81.39% of participants reported that the mindfulness BCI intervention was effective, and there was a significant reduction in the severity of seasickness, as measured by the Misery Scale (MISC). Furthermore, EEG analysis revealed a decrease in the theta/beta ratio, corresponding with the alleviation of seasickness symptoms. A decrease in overall EEG band power during the real-feedback mindfulness session suggests that the mindfulness BCI fosters a more tranquil and downregulated state of brain activity. Together, this study presents a novel nonpharmacological, portable, and effective approach for seasickness intervention, with the potential to enhance the cruising experience for both passengers and crews.
FedMoE-DA: Federated Mixture of Experts via Domain Aware Fine-grained Aggregation
Nov 04, 2024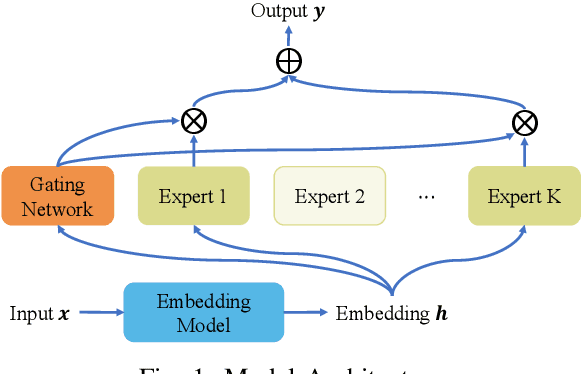
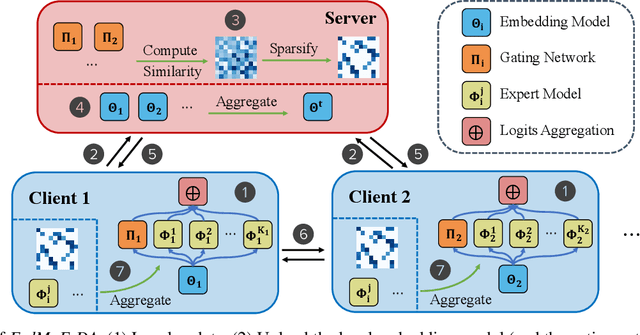
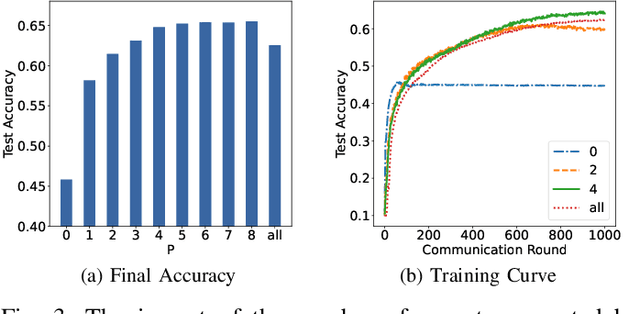
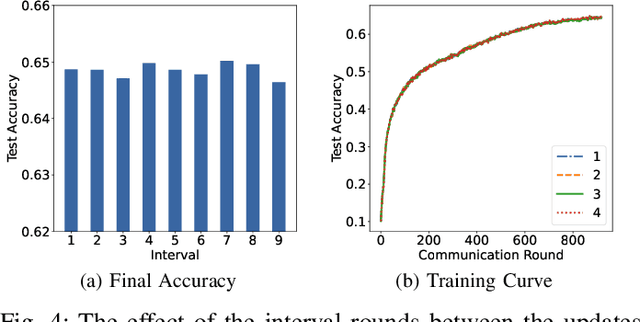
Federated learning (FL) is a collaborative machine learning approach that enables multiple clients to train models without sharing their private data. With the rise of deep learning, large-scale models have garnered significant attention due to their exceptional performance. However, a key challenge in FL is the limitation imposed by clients with constrained computational and communication resources, which hampers the deployment of these large models. The Mixture of Experts (MoE) architecture addresses this challenge with its sparse activation property, which reduces computational workload and communication demands during inference and updates. Additionally, MoE facilitates better personalization by allowing each expert to specialize in different subsets of the data distribution. To alleviate the communication burdens between the server and clients, we propose FedMoE-DA, a new FL model training framework that leverages the MoE architecture and incorporates a novel domain-aware, fine-grained aggregation strategy to enhance the robustness, personalizability, and communication efficiency simultaneously. Specifically, the correlation between both intra-client expert models and inter-client data heterogeneity is exploited. Moreover, we utilize peer-to-peer (P2P) communication between clients for selective expert model synchronization, thus significantly reducing the server-client transmissions. Experiments demonstrate that our FedMoE-DA achieves excellent performance while reducing the communication pressure on the server.
Detecting Machine-Generated Texts by Multi-Population Aware Optimization for Maximum Mean Discrepancy
Feb 29, 2024



Large language models (LLMs) such as ChatGPT have exhibited remarkable performance in generating human-like texts. However, machine-generated texts (MGTs) may carry critical risks, such as plagiarism issues, misleading information, or hallucination issues. Therefore, it is very urgent and important to detect MGTs in many situations. Unfortunately, it is challenging to distinguish MGTs and human-written texts because the distributional discrepancy between them is often very subtle due to the remarkable performance of LLMs. In this paper, we seek to exploit \textit{maximum mean discrepancy} (MMD) to address this issue in the sense that MMD can well identify distributional discrepancies. However, directly training a detector with MMD using diverse MGTs will incur a significantly increased variance of MMD since MGTs may contain \textit{multiple text populations} due to various LLMs. This will severely impair MMD's ability to measure the difference between two samples. To tackle this, we propose a novel \textit{multi-population} aware optimization method for MMD called MMD-MP, which can \textit{avoid variance increases} and thus improve the stability to measure the distributional discrepancy. Relying on MMD-MP, we develop two methods for paragraph-based and sentence-based detection, respectively. Extensive experiments on various LLMs, \eg, GPT2 and ChatGPT, show superior detection performance of our MMD-MP. The source code is available at \url{https://github.com/ZSHsh98/MMD-MP}.
Few-Shot Learning for Annotation-Efficient Nucleus Instance Segmentation
Feb 28, 2024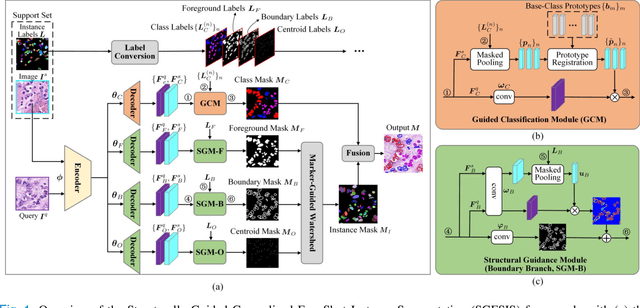
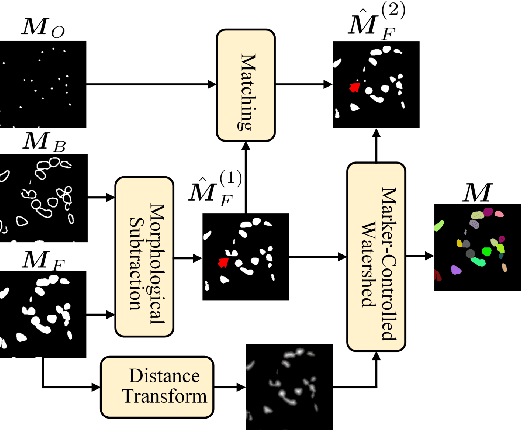
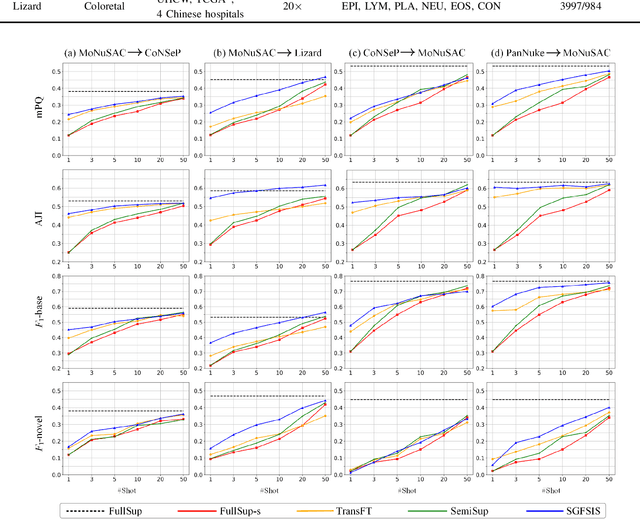
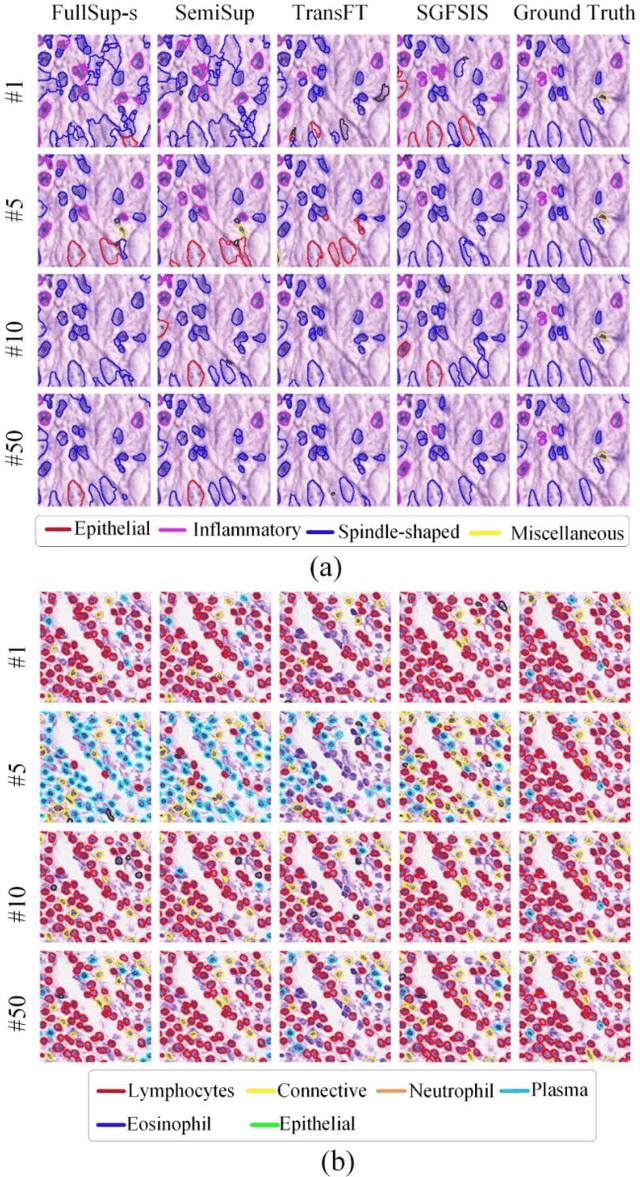
Nucleus instance segmentation from histopathology images suffers from the extremely laborious and expert-dependent annotation of nucleus instances. As a promising solution to this task, annotation-efficient deep learning paradigms have recently attracted much research interest, such as weakly-/semi-supervised learning, generative adversarial learning, etc. In this paper, we propose to formulate annotation-efficient nucleus instance segmentation from the perspective of few-shot learning (FSL). Our work was motivated by that, with the prosperity of computational pathology, an increasing number of fully-annotated datasets are publicly accessible, and we hope to leverage these external datasets to assist nucleus instance segmentation on the target dataset which only has very limited annotation. To achieve this goal, we adopt the meta-learning based FSL paradigm, which however has to be tailored in two substantial aspects before adapting to our task. First, since the novel classes may be inconsistent with those of the external dataset, we extend the basic definition of few-shot instance segmentation (FSIS) to generalized few-shot instance segmentation (GFSIS). Second, to cope with the intrinsic challenges of nucleus segmentation, including touching between adjacent cells, cellular heterogeneity, etc., we further introduce a structural guidance mechanism into the GFSIS network, finally leading to a unified Structurally-Guided Generalized Few-Shot Instance Segmentation (SGFSIS) framework. Extensive experiments on a couple of publicly accessible datasets demonstrate that, SGFSIS can outperform other annotation-efficient learning baselines, including semi-supervised learning, simple transfer learning, etc., with comparable performance to fully supervised learning with less than 5% annotations.
V2C: Visual Voice Cloning
Nov 25, 2021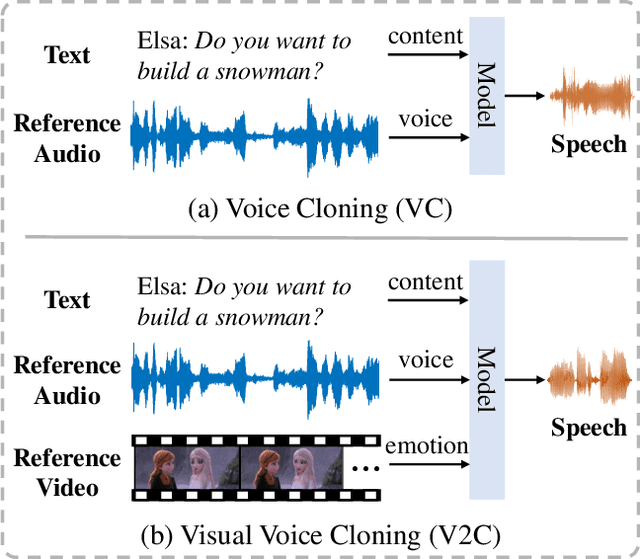
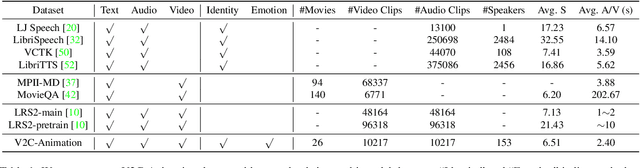

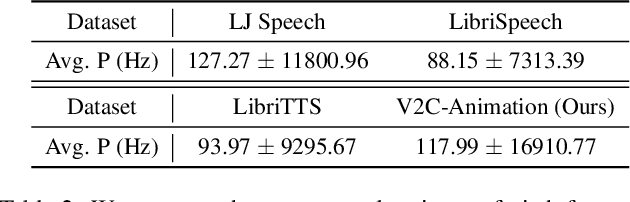
Existing Voice Cloning (VC) tasks aim to convert a paragraph text to a speech with desired voice specified by a reference audio. This has significantly boosted the development of artificial speech applications. However, there also exist many scenarios that cannot be well reflected by these VC tasks, such as movie dubbing, which requires the speech to be with emotions consistent with the movie plots. To fill this gap, in this work we propose a new task named Visual Voice Cloning (V2C), which seeks to convert a paragraph of text to a speech with both desired voice specified by a reference audio and desired emotion specified by a reference video. To facilitate research in this field, we construct a dataset, V2C-Animation, and propose a strong baseline based on existing state-of-the-art (SoTA) VC techniques. Our dataset contains 10,217 animated movie clips covering a large variety of genres (e.g., Comedy, Fantasy) and emotions (e.g., happy, sad). We further design a set of evaluation metrics, named MCD-DTW-SL, which help evaluate the similarity between ground-truth speeches and the synthesised ones. Extensive experimental results show that even SoTA VC methods cannot generate satisfying speeches for our V2C task. We hope the proposed new task together with the constructed dataset and evaluation metric will facilitate the research in the field of voice cloning and the broader vision-and-language community.
Elastic Architecture Search for Diverse Tasks with Different Resources
Aug 03, 2021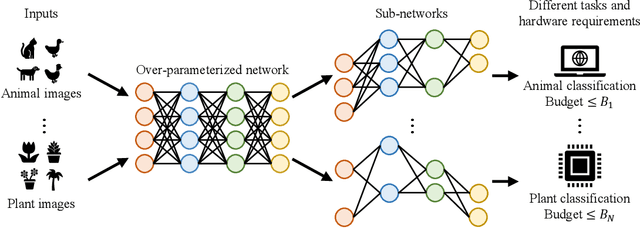
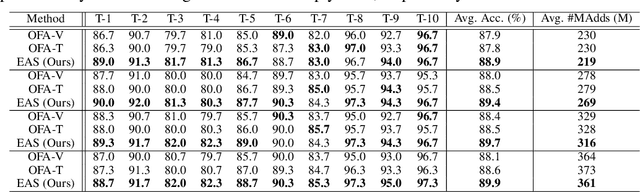
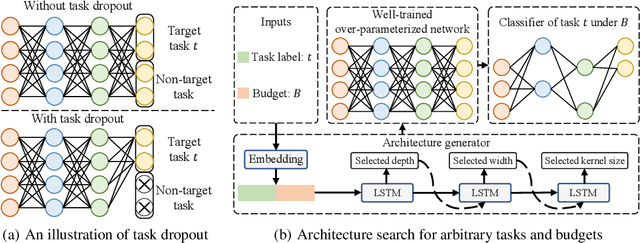
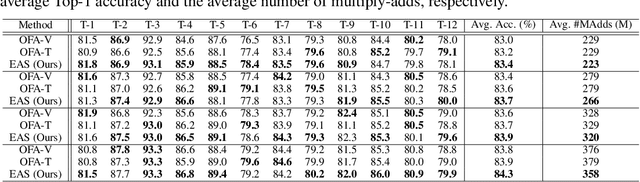
We study a new challenging problem of efficient deployment for diverse tasks with different resources, where the resource constraint and task of interest corresponding to a group of classes are dynamically specified at testing time. Previous NAS approaches seek to design architectures for all classes simultaneously, which may not be optimal for some individual tasks. A straightforward solution is to search an architecture from scratch for each deployment scenario, which however is computation-intensive and impractical. To address this, we present a novel and general framework, called Elastic Architecture Search (EAS), permitting instant specializations at runtime for diverse tasks with various resource constraints. To this end, we first propose to effectively train the over-parameterized network via a task dropout strategy to disentangle the tasks during training. In this way, the resulting model is robust to the subsequent task dropping at inference time. Based on the well-trained over-parameterized network, we then propose an efficient architecture generator to obtain optimal architectures within a single forward pass. Experiments on two image classification datasets show that EAS is able to find more compact networks with better performance while remarkably being orders of magnitude faster than state-of-the-art NAS methods. For example, our proposed EAS finds compact architectures within 0.1 second for 50 deployment scenarios.
Perception-aware Multi-sensor Fusion for 3D LiDAR Semantic Segmentation
Jun 21, 2021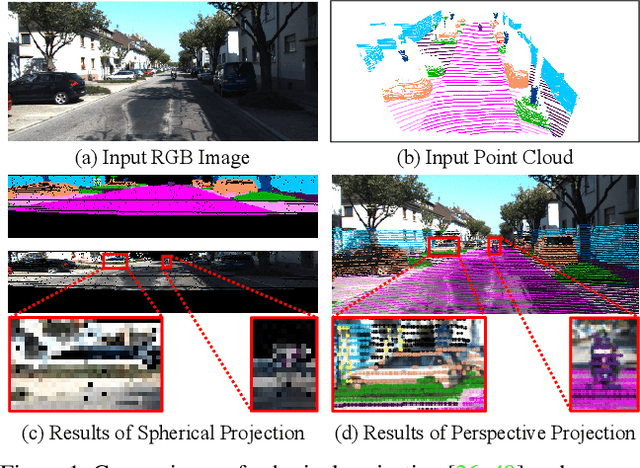
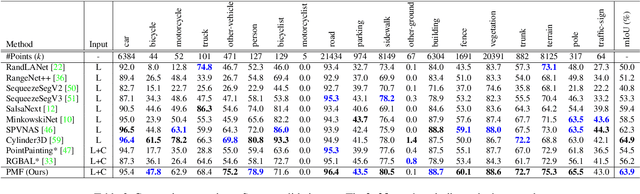
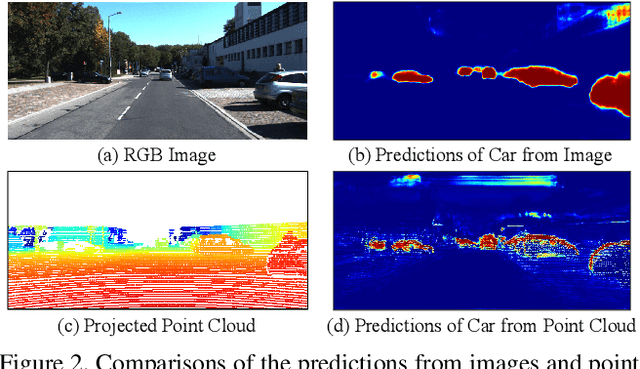
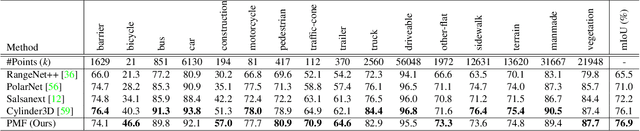
3D LiDAR (light detection and ranging) based semantic segmentation is important in scene understanding for many applications, such as auto-driving and robotics. For example, for autonomous cars equipped with RGB cameras and LiDAR, it is crucial to fuse complementary information from different sensors for robust and accurate segmentation. Existing fusion-based methods, however, may not achieve promising performance due to the vast difference between two modalities. In this work, we investigate a collaborative fusion scheme called perception-aware multi-sensor fusion (PMF) to exploit perceptual information from two modalities, namely, appearance information from RGB images and spatio-depth information from point clouds. To this end, we first project point clouds to the camera coordinates to provide spatio-depth information for RGB images. Then, we propose a two-stream network to extract features from the two modalities, separately, and fuse the features by effective residual-based fusion modules. Moreover, we propose additional perception-aware losses to measure the great perceptual difference between the two modalities. Extensive experiments on two benchmark data sets show the superiority of our method. For example, on nuScenes, our PMF outperforms the state-of-the-art method by 0.8% in mIoU.