 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to Trust Imagination: Adaptive Action Execution for World Action Models
May 07, 2026World Action Models (WAMs) have recently emerged as a promising paradigm for robotic manipulation by jointly predicting future visual observations and future actions. However, current WAMs typically execute a fixed number of predicted actions after each model inference, leaving the robot blind to whether the imagined future remains consistent with the actual physical rollout. In this work, we formulate adaptive WAM execution as a future-reality verification problem: the robot should execute longer when the WAM-predicted future remains reliable, and replan earlier when reality deviates from imagination. To this end, we propose Future Forward Dynamics Causal Attention (FFDC), a lightweight verifier that jointly reasons over predicted future actions, predicted visual dynamics, real observations, and language instructions to estimate whether the remaining action rollout can still be trusted. FFDC enables adaptive action chunk sizes as an emergent consequence of prediction-observation consistency, preserving the efficiency of long-horizon execution while restoring responsiveness in contact-rich or difficult phases. We further introduce Mixture-of-Horizon Training to improve long-horizon trajectory coverage for adaptive execution. Experiments on the RoboTwin benchmark and in the real world demonstrate that our method achieves a strong robustness-efficiency trade-off: on RoboTwin, it reduces WAM forward passes by 69.10% and execution time by 34.02%, while improving success rate by 2.54% over the short-chunk baseline; in real-world experiments, it improves success rate by 35%.
Learning to Reason in 4D: Dynamic Spatial Understanding for Vision Language Models
Dec 23, 2025Vision-language models (VLM) excel at general understanding yet remain weak at dynamic spatial reasoning (DSR), i.e., reasoning about the evolvement of object geometry and relationship in 3D space over time, largely due to the scarcity of scalable 4D-aware training resources. To bridge this gap across aspects of dataset, benchmark and model, we introduce DSR Suite. First, we propose an automated pipeline that generates multiple-choice question-answer pairs from in-the-wild videos for DSR. By leveraging modern vision foundation models, the pipeline extracts rich geometric and motion information, including camera poses, local point clouds, object masks, orientations, and 3D trajectories. These geometric cues enable the construction of DSR-Train for learning and further human-refined DSR-Bench for evaluation. Compared with previous works, our data emphasize (i) in-the-wild video sources, (ii) object- and scene-level 3D requirements, (iii) viewpoint transformations, (iv) multi-object interactions, and (v) fine-grained, procedural answers. Beyond data, we propose a lightweight Geometry Selection Module (GSM) to seamlessly integrate geometric priors into VLMs, which condenses question semantics and extracts question-relevant knowledge from pretrained 4D reconstruction priors into a compact set of geometry tokens. This targeted extraction avoids overwhelming the model with irrelevant knowledge. Experiments show that integrating DSR-Train and GSM into Qwen2.5-VL-7B significantly enhances its dynamic spatial reasoning capability, while maintaining accuracy on general video understanding benchmarks.
ASSIST-3D: Adapted Scene Synthesis for Class-Agnostic 3D Instance Segmentation
Dec 10, 2025Class-agnostic 3D instance segmentation tackles the challenging task of segmenting all object instances, including previously unseen ones, without semantic class reliance. Current methods struggle with generalization due to the scarce annotated 3D scene data or noisy 2D segmentations. While synthetic data generation offers a promising solution, existing 3D scene synthesis methods fail to simultaneously satisfy geometry diversity, context complexity, and layout reasonability, each essential for this task. To address these needs, we propose an Adapted 3D Scene Synthesis pipeline for class-agnostic 3D Instance SegmenTation, termed as ASSIST-3D, to synthesize proper data for model generalization enhancement. Specifically, ASSIST-3D features three key innovations, including 1) Heterogeneous Object Selection from extensive 3D CAD asset collections, incorporating randomness in object sampling to maximize geometric and contextual diversity; 2) Scene Layout Generation through LLM-guided spatial reasoning combined with depth-first search for reasonable object placements; and 3) Realistic Point Cloud Construction via multi-view RGB-D image rendering and fusion from the synthetic scenes, closely mimicking real-world sensor data acquisition. Experiments on ScanNetV2, ScanNet++, and S3DIS benchmarks demonstrate that models trained with ASSIST-3D-generated data significantly outperform existing methods. Further comparisons underscore the superiority of our purpose-built pipeline over existing 3D scene synthesis approaches.
PicoPose: Progressive Pixel-to-Pixel Correspondence Learning for Novel Object Pose Estimation
Apr 03, 2025Novel object pose estimation from RGB images presents a significant challenge for zero-shot generalization, as it involves estimating the relative 6D transformation between an RGB observation and a CAD model of an object that was not seen during training. In this paper, we introduce PicoPose, a novel framework designed to tackle this task using a three-stage pixel-to-pixel correspondence learning process. Firstly, PicoPose matches features from the RGB observation with those from rendered object templates, identifying the best-matched template and establishing coarse correspondences. Secondly, PicoPose smooths the correspondences by globally regressing a 2D affine transformation, including in-plane rotation, scale, and 2D translation, from the coarse correspondence map. Thirdly, PicoPose applies the affine transformation to the feature map of the best-matched template and learns correspondence offsets within local regions to achieve fine-grained correspondences. By progressively refining the correspondences, PicoPose significantly improves the accuracy of object poses computed via PnP/RANSAC. PicoPose achieves state-of-the-art performance on the seven core datasets of the BOP benchmark, demonstrating exceptional generalization to novel objects represented by CAD models or object reference images. Code and models are available at https://github.com/foollh/PicoPose.
SAM-6D: Segment Anything Model Meets Zero-Shot 6D Object Pose Estimation
Nov 27, 2023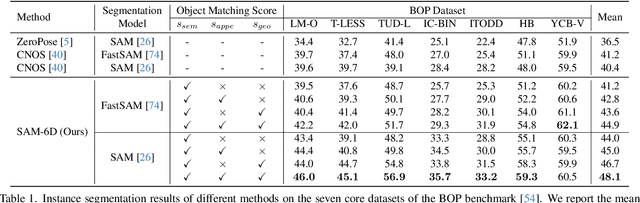
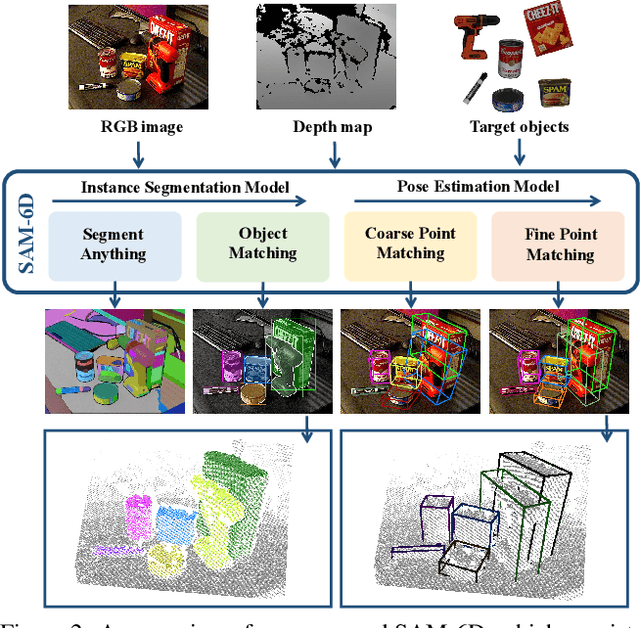
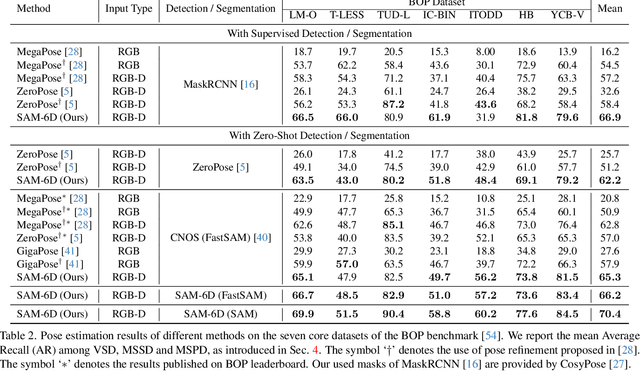
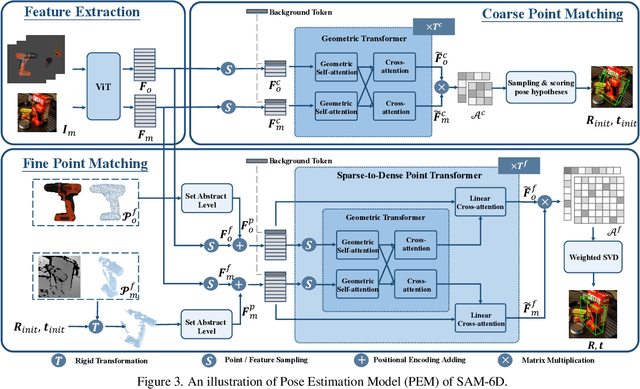
Zero-shot 6D object pose estimation involves the detection of novel objects with their 6D poses in cluttered scenes, presenting significant challenges for model generalizability. Fortunately, the recent Segment Anything Model (SAM) has showcased remarkable zero-shot transfer performance, which provides a promising solution to tackle this task. Motivated by this, we introduce SAM-6D, a novel framework designed to realize the task through two steps, including instance segmentation and pose estimation. Given the target objects, SAM-6D employs two dedicated sub-networks, namely Instance Segmentation Model (ISM) and Pose Estimation Model (PEM), to perform these steps on cluttered RGB-D images. ISM takes SAM as an advanced starting point to generate all possible object proposals and selectively preserves valid ones through meticulously crafted object matching scores in terms of semantics, appearance and geometry. By treating pose estimation as a partial-to-partial point matching problem, PEM performs a two-stage point matching process featuring a novel design of background tokens to construct dense 3D-3D correspondence, ultimately yielding the pose estimates. Without bells and whistles, SAM-6D outperforms the existing methods on the seven core datasets of the BOP Benchmark for both instance segmentation and pose estimation of novel objects.
VI-Net: Boosting Category-level 6D Object Pose Estimation via Learning Decoupled Rotations on the Spherical Representations
Aug 19, 2023



Rotation estimation of high precision from an RGB-D object observation is a huge challenge in 6D object pose estimation, due to the difficulty of learning in the non-linear space of SO(3). In this paper, we propose a novel rotation estimation network, termed as VI-Net, to make the task easier by decoupling the rotation as the combination of a viewpoint rotation and an in-plane rotation. More specifically, VI-Net bases the feature learning on the sphere with two individual branches for the estimates of two factorized rotations, where a V-Branch is employed to learn the viewpoint rotation via binary classification on the spherical signals, while another I-Branch is used to estimate the in-plane rotation by transforming the signals to view from the zenith direction. To process the spherical signals, a Spherical Feature Pyramid Network is constructed based on a novel design of SPAtial Spherical Convolution (SPA-SConv), which settles the boundary problem of spherical signals via feature padding and realizesviewpoint-equivariant feature extraction by symmetric convolutional operations. We apply the proposed VI-Net to the challenging task of category-level 6D object pose estimation for predicting the poses of unknown objects without available CAD models; experiments on the benchmarking datasets confirm the efficacy of our method, which outperforms the existing ones with a large margin in the regime of high precision.
Manifold-Aware Self-Training for Unsupervised Domain Adaptation on Regressing 6D Object Pose
May 18, 2023



Domain gap between synthetic and real data in visual regression (\eg 6D pose estimation) is bridged in this paper via global feature alignment and local refinement on the coarse classification of discretized anchor classes in target space, which imposes a piece-wise target manifold regularization into domain-invariant representation learning. Specifically, our method incorporates an explicit self-supervised manifold regularization, revealing consistent cumulative target dependency across domains, to a self-training scheme (\eg the popular Self-Paced Self-Training) to encourage more discriminative transferable representations of regression tasks. Moreover, learning unified implicit neural functions to estimate relative direction and distance of targets to their nearest class bins aims to refine target classification predictions, which can gain robust performance against inconsistent feature scaling sensitive to UDA regressors. Experiment results on three public benchmarks of the challenging 6D pose estimation task can verify the effectiveness of our method, consistently achieving superior performance to the state-of-the-art for UDA on 6D pose estimation.
Point-DAE: Denoising Autoencoders for Self-supervised Point Cloud Learning
Nov 13, 2022



Masked autoencoder has demonstrated its effectiveness in self-supervised point cloud learning. Considering that masking is a kind of corruption, in this work we explore a more general denoising autoencoder for point cloud learning (Point-DAE) by investigating more types of corruptions beyond masking. Specifically, we degrade the point cloud with certain corruptions as input, and learn an encoder-decoder model to reconstruct the original point cloud from its corrupted version. Three corruption families (i.e., density/masking, noise, and affine transformation) and a total of fourteen corruption types are investigated. Interestingly, the affine transformation-based Point-DAE generally outperforms others (e.g., the popular masking corruptions), suggesting a promising direction for self-supervised point cloud learning. More importantly, we find a statistically significant linear relationship between task relatedness and model performance on downstream tasks. This finding partly demystifies the advantage of affine transformation-based Point-DAE, given that such Point-DAE variants are closely related to the downstream classification task. Additionally, we reveal that most Point-DAE variants unintentionally benefit from the manually-annotated canonical poses in the pre-training dataset. To tackle such an issue, we promote a new dataset setting by estimating object poses automatically. The codes will be available at \url{https://github.com/YBZh/Point-DAE.}
DCL-Net: Deep Correspondence Learning Network for 6D Pose Estimation
Oct 11, 2022

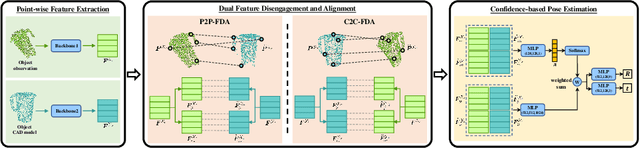

Establishment of point correspondence between camera and object coordinate systems is a promising way to solve 6D object poses. However, surrogate objectives of correspondence learning in 3D space are a step away from the true ones of object pose estimation, making the learning suboptimal for the end task. In this paper, we address this shortcoming by introducing a new method of Deep Correspondence Learning Network for direct 6D object pose estimation, shortened as DCL-Net. Specifically, DCL-Net employs dual newly proposed Feature Disengagement and Alignment (FDA) modules to establish, in the feature space, partial-to-partial correspondence and complete-to-complete one for partial object observation and its complete CAD model, respectively, which result in aggregated pose and match feature pairs from two coordinate systems; these two FDA modules thus bring complementary advantages. The match feature pairs are used to learn confidence scores for measuring the qualities of deep correspondence, while the pose feature pairs are weighted by confidence scores for direct object pose regression. A confidence-based pose refinement network is also proposed to further improve pose precision in an iterative manner. Extensive experiments show that DCL-Net outperforms existing methods on three benchmarking datasets, including YCB-Video, LineMOD, and Oclussion-LineMOD; ablation studies also confirm the efficacy of our novel designs.
Category-Level 6D Object Pose and Size Estimation using Self-Supervised Deep Prior Deformation Networks
Jul 12, 2022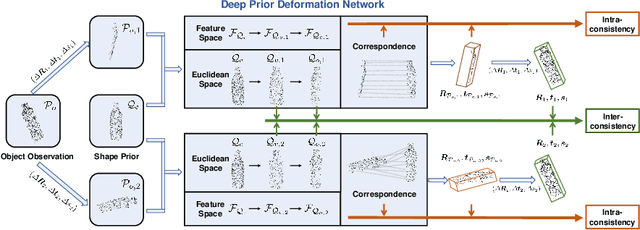
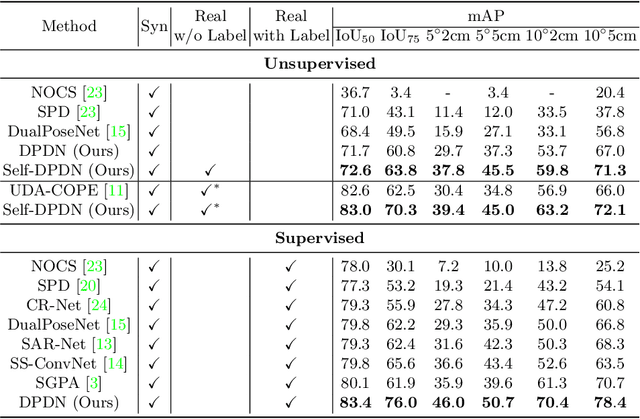
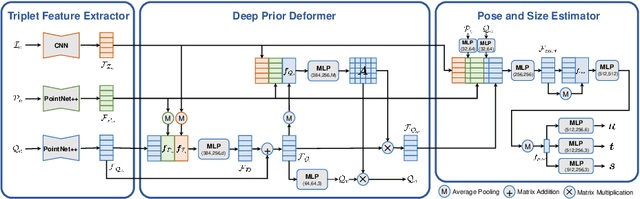
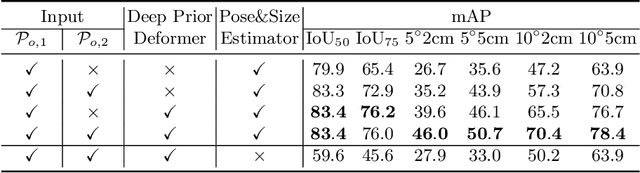
It is difficult to precisely annotate object instances and their semantics in 3D space, and as such, synthetic data are extensively used for these tasks, e.g., category-level 6D object pose and size estimation. However, the easy annotations in synthetic domains bring the downside effect of synthetic-to-real (Sim2Real) domain gap. In this work, we aim to address this issue in the task setting of Sim2Real, unsupervised domain adaptation for category-level 6D object pose and size estimation. We propose a method that is built upon a novel Deep Prior Deformation Network, shortened as DPDN. DPDN learns to deform features of categorical shape priors to match those of object observations, and is thus able to establish deep correspondence in the feature space for direct regression of object poses and sizes. To reduce the Sim2Real domain gap, we formulate a novel self-supervised objective upon DPDN via consistency learning; more specifically, we apply two rigid transformations to each object observation in parallel, and feed them into DPDN respectively to yield dual sets of predictions; on top of the parallel learning, an inter-consistency term is employed to keep cross consistency between dual predictions for improving the sensitivity of DPDN to pose changes, while individual intra-consistency ones are used to enforce self-adaptation within each learning itself. We train DPDN on both training sets of the synthetic CAMERA25 and real-world REAL275 datasets; our results outperform the existing methods on REAL275 test set under both the unsupervised and supervised settings. Ablation studies also verify the efficacy of our designs. Our code is released publicly at https://github.com/JiehongLin/Self-DPDN.