 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCategory-Level 6D Object Pose and Size Estimation using Self-Supervised Deep Prior Deformation Networks
Paper and Code
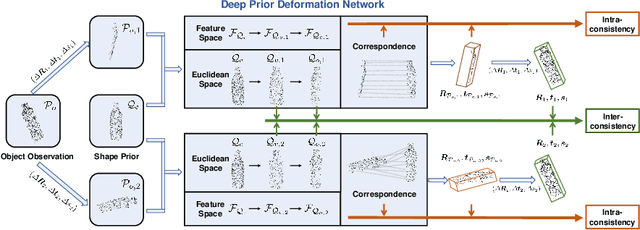
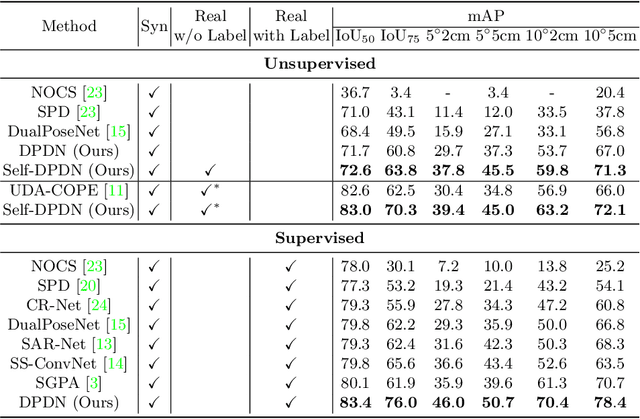
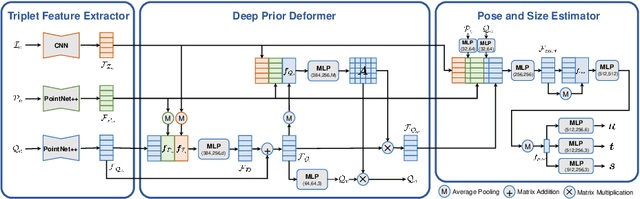
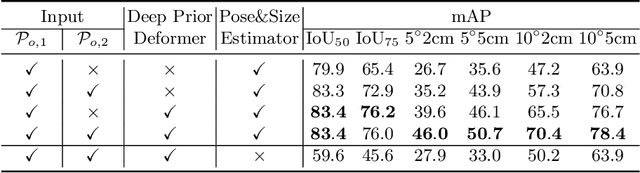
It is difficult to precisely annotate object instances and their semantics in 3D space, and as such, synthetic data are extensively used for these tasks, e.g., category-level 6D object pose and size estimation. However, the easy annotations in synthetic domains bring the downside effect of synthetic-to-real (Sim2Real) domain gap. In this work, we aim to address this issue in the task setting of Sim2Real, unsupervised domain adaptation for category-level 6D object pose and size estimation. We propose a method that is built upon a novel Deep Prior Deformation Network, shortened as DPDN. DPDN learns to deform features of categorical shape priors to match those of object observations, and is thus able to establish deep correspondence in the feature space for direct regression of object poses and sizes. To reduce the Sim2Real domain gap, we formulate a novel self-supervised objective upon DPDN via consistency learning; more specifically, we apply two rigid transformations to each object observation in parallel, and feed them into DPDN respectively to yield dual sets of predictions; on top of the parallel learning, an inter-consistency term is employed to keep cross consistency between dual predictions for improving the sensitivity of DPDN to pose changes, while individual intra-consistency ones are used to enforce self-adaptation within each learning itself. We train DPDN on both training sets of the synthetic CAMERA25 and real-world REAL275 datasets; our results outperform the existing methods on REAL275 test set under both the unsupervised and supervised settings. Ablation studies also verify the efficacy of our designs. Our code is released publicly at https://github.com/JiehongLin/Self-DPDN.