 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstruction-Anchored Diffusion Model for Text-to-Motion Generation
Jan 21, 2026Diffusion models have seen widespread adoption for text-driven human motion generation and related tasks due to their impressive generative capabilities and flexibility. However, current motion diffusion models face two major limitations: a representational gap caused by pre-trained text encoders that lack motion-specific information, and error propagation during the iterative denoising process. This paper introduces Reconstruction-Anchored Diffusion Model (RAM) to address these challenges. First, RAM leverages a motion latent space as intermediate supervision for text-to-motion generation. To this end, RAM co-trains a motion reconstruction branch with two key objective functions: self-regularization to enhance the discrimination of the motion space and motion-centric latent alignment to enable accurate mapping from text to the motion latent space. Second, we propose Reconstructive Error Guidance (REG), a testing-stage guidance mechanism that exploits the diffusion model's inherent self-correction ability to mitigate error propagation. At each denoising step, REG uses the motion reconstruction branch to reconstruct the previous estimate, reproducing the prior error patterns. By amplifying the residual between the current prediction and the reconstructed estimate, REG highlights the improvements in the current prediction. Extensive experiments demonstrate that RAM achieves significant improvements and state-of-the-art performance. Our code will be released.
ChartMaster: Advancing Chart-to-Code Generation with Real-World Charts and Chart Similarity Reinforcement Learning
Aug 25, 2025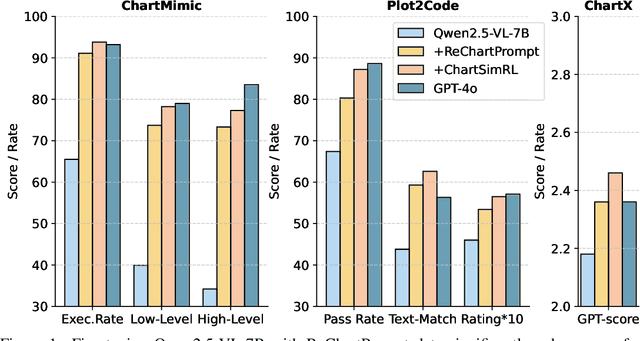

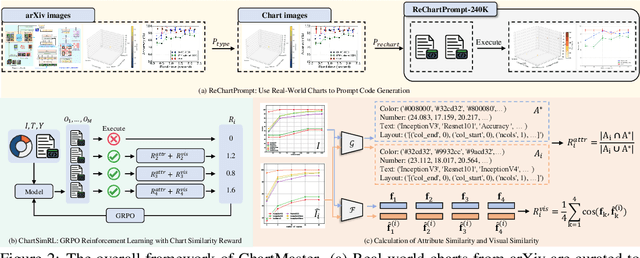

The chart-to-code generation task requires MLLMs to convert chart images into executable code. This task faces two major challenges: limited data diversity and insufficient maintenance of visual consistency between generated and original charts during training. Existing datasets mainly rely on seed data to prompt GPT models for code generation, resulting in homogeneous samples. To address this, we propose ReChartPrompt, which leverages real-world, human-designed charts from arXiv papers as prompts instead of synthetic seeds. Using the diverse styles and rich content of arXiv charts, we construct ReChartPrompt-240K, a large-scale and highly diverse dataset. Another challenge is that although SFT effectively improve code understanding, it often fails to ensure that generated charts are visually consistent with the originals. To address this, we propose ChartSimRL, a GRPO-based reinforcement learning algorithm guided by a novel chart similarity reward. This reward consists of attribute similarity, which measures the overlap of chart attributes such as layout and color between the generated and original charts, and visual similarity, which assesses similarity in texture and other overall visual features using convolutional neural networks. Unlike traditional text-based rewards such as accuracy or format rewards, our reward considers the multimodal nature of the chart-to-code task and effectively enhances the model's ability to accurately reproduce charts. By integrating ReChartPrompt and ChartSimRL, we develop the ChartMaster model, which achieves state-of-the-art results among 7B-parameter models and even rivals GPT-4o on various chart-to-code generation benchmarks. All resources are available at https://github.com/WentaoTan/ChartMaster.
Bilateral Collaboration with Large Vision-Language Models for Open Vocabulary Human-Object Interaction Detection
Jul 09, 2025Open vocabulary Human-Object Interaction (HOI) detection is a challenging task that detects all <human, verb, object> triplets of interest in an image, even those that are not pre-defined in the training set. Existing approaches typically rely on output features generated by large Vision-Language Models (VLMs) to enhance the generalization ability of interaction representations. However, the visual features produced by VLMs are holistic and coarse-grained, which contradicts the nature of detection tasks. To address this issue, we propose a novel Bilateral Collaboration framework for open vocabulary HOI detection (BC-HOI). This framework includes an Attention Bias Guidance (ABG) component, which guides the VLM to produce fine-grained instance-level interaction features according to the attention bias provided by the HOI detector. It also includes a Large Language Model (LLM)-based Supervision Guidance (LSG) component, which provides fine-grained token-level supervision for the HOI detector by the LLM component of the VLM. LSG enhances the ability of ABG to generate high-quality attention bias. We conduct extensive experiments on two popular benchmarks: HICO-DET and V-COCO, consistently achieving superior performance in the open vocabulary and closed settings. The code will be released in Github.
Democratizing High-Fidelity Co-Speech Gesture Video Generation
Jul 09, 2025Co-speech gesture video generation aims to synthesize realistic, audio-aligned videos of speakers, complete with synchronized facial expressions and body gestures. This task presents challenges due to the significant one-to-many mapping between audio and visual content, further complicated by the scarcity of large-scale public datasets and high computational demands. We propose a lightweight framework that utilizes 2D full-body skeletons as an efficient auxiliary condition to bridge audio signals with visual outputs. Our approach introduces a diffusion model conditioned on fine-grained audio segments and a skeleton extracted from the speaker's reference image, predicting skeletal motions through skeleton-audio feature fusion to ensure strict audio coordination and body shape consistency. The generated skeletons are then fed into an off-the-shelf human video generation model with the speaker's reference image to synthesize high-fidelity videos. To democratize research, we present CSG-405-the first public dataset with 405 hours of high-resolution videos across 71 speech types, annotated with 2D skeletons and diverse speaker demographics. Experiments show that our method exceeds state-of-the-art approaches in visual quality and synchronization while generalizing across speakers and contexts.
Guiding Human-Object Interactions with Rich Geometry and Relations
Mar 26, 2025Human-object interaction (HOI) synthesis is crucial for creating immersive and realistic experiences for applications such as virtual reality. Existing methods often rely on simplified object representations, such as the object's centroid or the nearest point to a human, to achieve physically plausible motions. However, these approaches may overlook geometric complexity, resulting in suboptimal interaction fidelity. To address this limitation, we introduce ROG, a novel diffusion-based framework that models the spatiotemporal relationships inherent in HOIs with rich geometric detail. For efficient object representation, we select boundary-focused and fine-detail key points from the object mesh, ensuring a comprehensive depiction of the object's geometry. This representation is used to construct an interactive distance field (IDF), capturing the robust HOI dynamics. Furthermore, we develop a diffusion-based relation model that integrates spatial and temporal attention mechanisms, enabling a better understanding of intricate HOI relationships. This relation model refines the generated motion's IDF, guiding the motion generation process to produce relation-aware and semantically aligned movements. Experimental evaluations demonstrate that ROG significantly outperforms state-of-the-art methods in the realism and semantic accuracy of synthesized HOIs.
Effortless Active Labeling for Long-Term Test-Time Adaptation
Mar 18, 2025Long-term test-time adaptation (TTA) is a challenging task due to error accumulation. Recent approaches tackle this issue by actively labeling a small proportion of samples in each batch, yet the annotation burden quickly grows as the batch number increases. In this paper, we investigate how to achieve effortless active labeling so that a maximum of one sample is selected for annotation in each batch. First, we annotate the most valuable sample in each batch based on the single-step optimization perspective in the TTA context. In this scenario, the samples that border between the source- and target-domain data distributions are considered the most feasible for the model to learn in one iteration. Then, we introduce an efficient strategy to identify these samples using feature perturbation. Second, we discover that the gradient magnitudes produced by the annotated and unannotated samples have significant variations. Therefore, we propose balancing their impact on model optimization using two dynamic weights. Extensive experiments on the popular ImageNet-C, -R, -K, -A and PACS databases demonstrate that our approach consistently outperforms state-of-the-art methods with significantly lower annotation costs.
Modeling Thousands of Human Annotators for Generalizable Text-to-Image Person Re-identification
Mar 13, 2025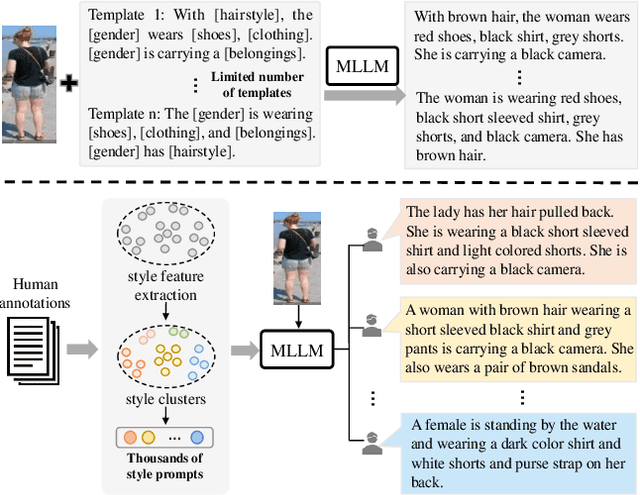
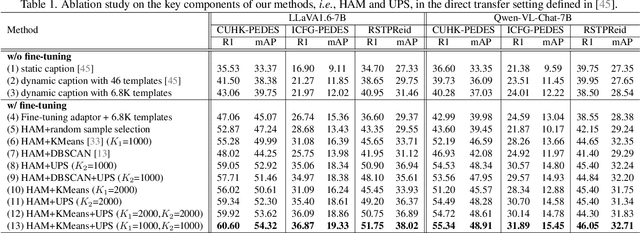
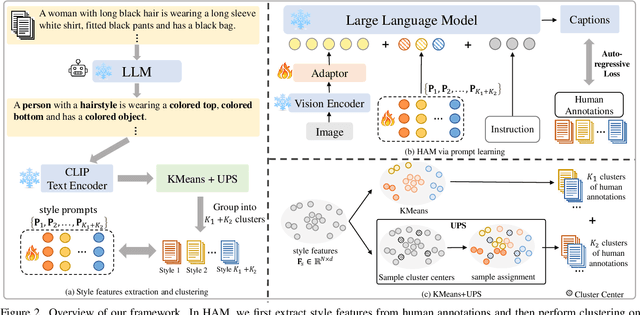
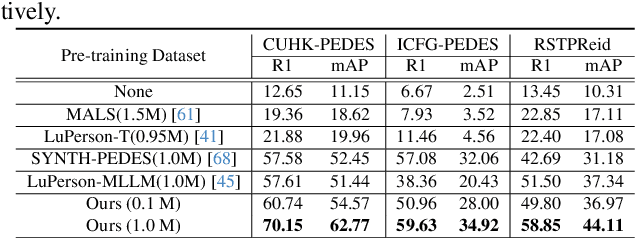
Text-to-image person re-identification (ReID) aims to retrieve the images of an interested person based on textual descriptions. One main challenge for this task is the high cost in manually annotating large-scale databases, which affects the generalization ability of ReID models. Recent works handle this problem by leveraging Multi-modal Large Language Models (MLLMs) to describe pedestrian images automatically. However, the captions produced by MLLMs lack diversity in description styles. To address this issue, we propose a Human Annotator Modeling (HAM) approach to enable MLLMs to mimic the description styles of thousands of human annotators. Specifically, we first extract style features from human textual descriptions and perform clustering on them. This allows us to group textual descriptions with similar styles into the same cluster. Then, we employ a prompt to represent each of these clusters and apply prompt learning to mimic the description styles of different human annotators. Furthermore, we define a style feature space and perform uniform sampling in this space to obtain more diverse clustering prototypes, which further enriches the diversity of the MLLM-generated captions. Finally, we adopt HAM to automatically annotate a massive-scale database for text-to-image ReID. Extensive experiments on this database demonstrate that it significantly improves the generalization ability of ReID models.
Beyond Human Data: Aligning Multimodal Large Language Models by Iterative Self-Evolution
Dec 20, 2024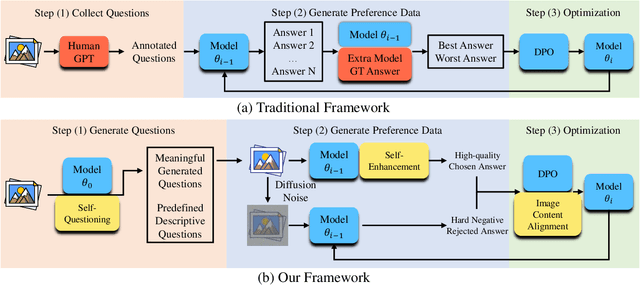



Human preference alignment can greatly enhance Multimodal Large Language Models (MLLMs), but collecting high-quality preference data is costly. A promising solution is the self-evolution strategy, where models are iteratively trained on data they generate. However, current techniques still rely on human- or GPT-annotated data and sometimes require additional models or ground truth answers. To address these issues, we propose a novel multimodal self-evolution framework that enables the model to autonomously generate high-quality questions and answers using only unannotated images. First, we implement an image-driven self-questioning mechanism, allowing the model to create and evaluate questions based on image content, regenerating them if they are irrelevant or unanswerable. This sets a strong foundation for answer generation. Second, we introduce an answer self-enhancement technique, starting with image captioning to improve answer quality. We also use corrupted images to generate rejected answers, forming distinct preference pairs for optimization. Finally, we incorporate an image content alignment loss function alongside Direct Preference Optimization (DPO) loss to reduce hallucinations, ensuring the model focuses on image content. Experiments show that our framework performs competitively with methods using external information, offering a more efficient and scalable approach to MLLMs.
Simultaneous Computation and Memory Efficient Zeroth-Order Optimizer for Fine-Tuning Large Language Models
Oct 13, 2024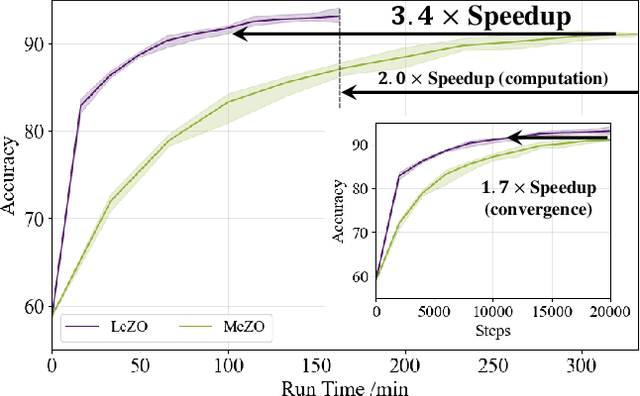
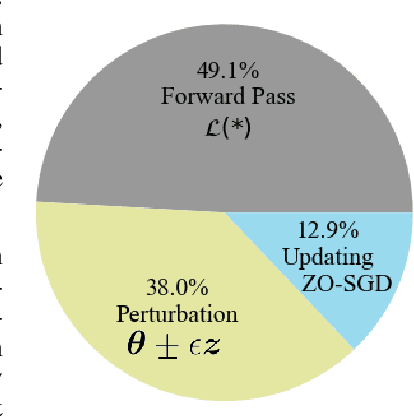
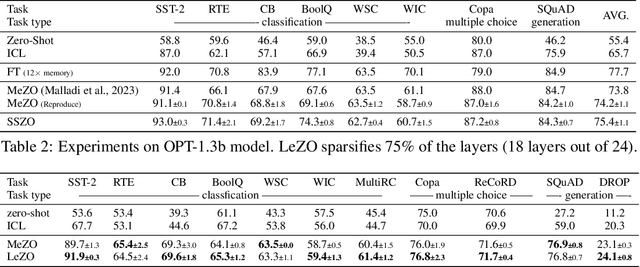
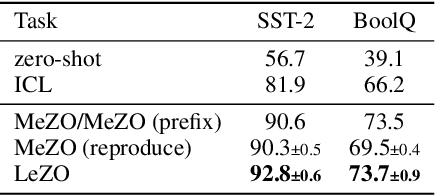
Fine-tuning is powerful for adapting large language models to downstream tasks, but it often results in huge memory usages. A promising approach to mitigate this is using Zeroth-Order (ZO) optimization, which estimates gradients to replace First-Order (FO) gradient calculations, albeit with longer training time due to its stochastic nature. By revisiting the Memory-efficient ZO (MeZO) optimizer, we discover that the full-parameter perturbation and updating processes consume over 50% of its overall fine-tuning time cost. Based on these observations, we introduce a novel layer-wise sparse computation and memory efficient ZO optimizer, named LeZO. LeZO treats layers as fundamental units for sparsification and dynamically perturbs different parameter subsets in each step to achieve full-parameter fine-tuning. LeZO incorporates layer-wise parameter sparsity in the process of simultaneous perturbation stochastic approximation (SPSA) and ZO stochastic gradient descent (ZO-SGD). It achieves accelerated computation during perturbation and updating processes without additional memory overhead. We conduct extensive experiments with the OPT model family on the SuperGLUE benchmark and two generative tasks. The experiments show that LeZO accelerates training without compromising the performance of ZO optimization. Specifically, it achieves over 3x speedup compared to MeZO on the SST-2, BoolQ, and Copa tasks.
Harnessing the Power of MLLMs for Transferable Text-to-Image Person ReID
May 08, 2024



Text-to-image person re-identification (ReID) retrieves pedestrian images according to textual descriptions. Manually annotating textual descriptions is time-consuming, restricting the scale of existing datasets and therefore the generalization ability of ReID models. As a result, we study the transferable text-to-image ReID problem, where we train a model on our proposed large-scale database and directly deploy it to various datasets for evaluation. We obtain substantial training data via Multi-modal Large Language Models (MLLMs). Moreover, we identify and address two key challenges in utilizing the obtained textual descriptions. First, an MLLM tends to generate descriptions with similar structures, causing the model to overfit specific sentence patterns. Thus, we propose a novel method that uses MLLMs to caption images according to various templates. These templates are obtained using a multi-turn dialogue with a Large Language Model (LLM). Therefore, we can build a large-scale dataset with diverse textual descriptions. Second, an MLLM may produce incorrect descriptions. Hence, we introduce a novel method that automatically identifies words in a description that do not correspond with the image. This method is based on the similarity between one text and all patch token embeddings in the image. Then, we mask these words with a larger probability in the subsequent training epoch, alleviating the impact of noisy textual descriptions. The experimental results demonstrate that our methods significantly boost the direct transfer text-to-image ReID performance. Benefiting from the pre-trained model weights, we also achieve state-of-the-art performance in the traditional evaluation settings.