 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Computation and Memory Efficient Zeroth-Order Optimizer for Fine-Tuning Large Language Models
Paper and Code
Oct 13, 2024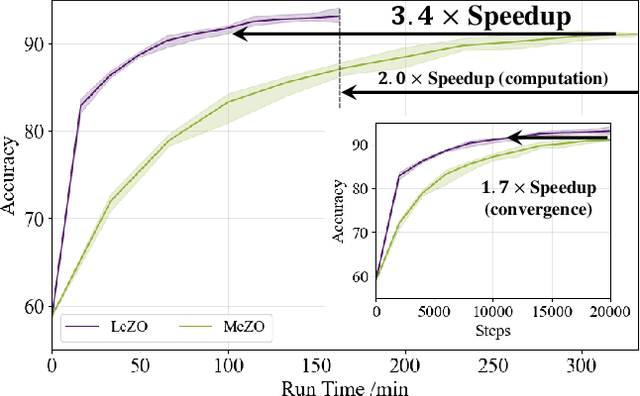
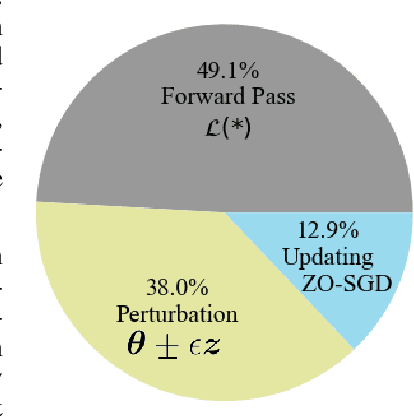
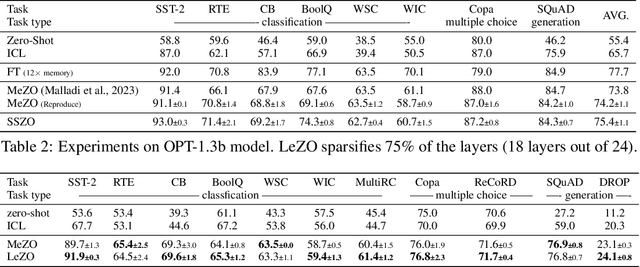
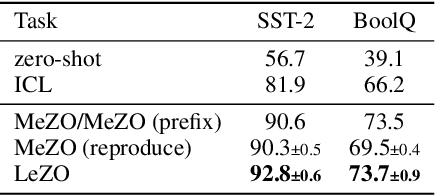
Fine-tuning is powerful for adapting large language models to downstream tasks, but it often results in huge memory usages. A promising approach to mitigate this is using Zeroth-Order (ZO) optimization, which estimates gradients to replace First-Order (FO) gradient calculations, albeit with longer training time due to its stochastic nature. By revisiting the Memory-efficient ZO (MeZO) optimizer, we discover that the full-parameter perturbation and updating processes consume over 50% of its overall fine-tuning time cost. Based on these observations, we introduce a novel layer-wise sparse computation and memory efficient ZO optimizer, named LeZO. LeZO treats layers as fundamental units for sparsification and dynamically perturbs different parameter subsets in each step to achieve full-parameter fine-tuning. LeZO incorporates layer-wise parameter sparsity in the process of simultaneous perturbation stochastic approximation (SPSA) and ZO stochastic gradient descent (ZO-SGD). It achieves accelerated computation during perturbation and updating processes without additional memory overhead. We conduct extensive experiments with the OPT model family on the SuperGLUE benchmark and two generative tasks. The experiments show that LeZO accelerates training without compromising the performance of ZO optimization. Specifically, it achieves over 3x speedup compared to MeZO on the SST-2, BoolQ, and Copa tasks.