 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter Importance is Not Static: Evolving Parameter Isolation for Supervised Fine-Tuning
Apr 15, 2026Supervised Fine-Tuning (SFT) of large language models often suffers from task interference and catastrophic forgetting. Recent approaches alleviate this issue by isolating task-critical parameters during training. However, these methods represent a static solution to a dynamic problem, assuming that parameter importance remains fixed once identified. In this work, we empirically demonstrate that parameter importance exhibits temporal drift over the course of training. To address this, we propose Evolving Parameter Isolation (EPI), a fine-tuning framework that adapts isolation decisions based on online estimates of parameter importance. Instead of freezing a fixed subset of parameters, EPI periodically updates isolation masks using gradient-based signals, enabling the model to protect emerging task-critical parameters while releasing outdated ones to recover plasticity. Experiments on diverse multi-task benchmarks demonstrate that EPI consistently reduces interference and forgetting compared to static isolation and standard fine-tuning, while improving overall generalization. Our analysis highlights the necessity of synchronizing isolation mechanisms with the evolving dynamics of learning diverse abilities.
Why Supervised Fine-Tuning Fails to Learn: A Systematic Study of Incomplete Learning in Large Language Models
Apr 11, 2026Supervised Fine-Tuning (SFT) is the standard approach for adapting large language models (LLMs) to downstream tasks. However, we observe a persistent failure mode: even after convergence, models often fail to correctly reproduce a subset of their own supervised training data. We refer to this behavior as the Incomplete Learning Phenomenon(ILP). This paper presents the first systematic study of ILP in LLM fine-tuning. We formalize ILP as post-training failure to internalize supervised instances and demonstrate its prevalence across multiple model families, domains, and datasets. Through controlled analyses, we identify five recurrent sources of incomplete learning: (1) missing prerequisite knowledge in the pre-trained model, (2) conflicts between SFT supervision and pre-training knowledge, (3) internal inconsistencies within SFT data, (4) left-side forgetting during sequential fine-tuning, and (5) insufficient optimization for rare or complex patterns. We introduce a diagnostic-first framework that maps unlearned samples to these causes using observable training and inference signals, and study several targeted mitigation strategies as causal interventions. Experiments on Qwen, LLaMA, and OLMo2 show that incomplete learning is widespread and heterogeneous, and that improvements in aggregate metrics can mask persistent unlearned subsets. The findings highlight the need for fine-grained diagnosis of what supervised fine-tuning fails to learn, and why.
Reason Only When Needed: Efficient Generative Reward Modeling via Model-Internal Uncertainty
Apr 11, 2026Recent advancements in the Generative Reward Model (GRM) have demonstrated its potential to enhance the reasoning abilities of LLMs through Chain-of-Thought (CoT) prompting. Despite these gains, existing implementations of GRM suffer from two critical limitations. First, CoT prompting is applied indiscriminately to all inputs regardless of their inherent complexity. This introduces unnecessary computational costs for tasks amenable to fast, direct inference. Second, existing approaches primarily rely on voting-based mechanisms to evaluate CoT outputs, which often lack granularity and precision in assessing reasoning quality. In this paper, we propose E-GRM, an efficient generative reward modeling framework grounded in model-internal uncertainty. E-GRM leverages the convergence behavior of parallel model generations to estimate uncertainty and selectively trigger CoT reasoning only when needed, without relying on handcrafted features or task-dependent signals. To improve reward fidelity, we introduce a lightweight discriminative scorer trained with a hybrid regression--ranking objective to provide fine-grained evaluation of reasoning paths. Experiments on multiple reasoning benchmarks show that E-GRM substantially reduces inference cost while consistently improving answer accuracy, demonstrating that model-internal uncertainty is an effective and general signal for efficient reasoning-aware reward modeling.
JoyAI-LLM Flash: Advancing Mid-Scale LLMs with Token Efficiency
Apr 03, 2026We introduce JoyAI-LLM Flash, an efficient Mixture-of-Experts (MoE) language model designed to redefine the trade-off between strong performance and token efficiency in the sub-50B parameter regime. JoyAI-LLM Flash is pretrained on a massive corpus of 20 trillion tokens and further optimized through a rigorous post-training pipeline, including supervised fine-tuning (SFT), Direct Preference Optimization (DPO), and large-scale reinforcement learning (RL) across diverse environments. To improve token efficiency, JoyAI-LLM Flash strategically balances \emph{thinking} and \emph{non-thinking} cognitive modes and introduces FiberPO, a novel RL algorithm inspired by fibration theory that decomposes trust-region maintenance into global and local components, providing unified multi-scale stability control for LLM policy optimization. To enhance architectural sparsity, the model comprises 48B total parameters while activating only 2.7B parameters per forward pass, achieving a substantially higher sparsity ratio than contemporary industry leading models of comparable scale. To further improve inference throughput, we adopt a joint training-inference co-design that incorporates dense Multi-Token Prediction (MTP) and Quantization-Aware Training (QAT). We release the checkpoints for both JoyAI-LLM-48B-A3B Base and its post-trained variants on Hugging Face to support the open-source community.
Fibration Policy Optimization
Mar 09, 2026Large language models are increasingly trained as heterogeneous systems spanning multiple domains, expert partitions, and agentic pipelines, yet prevalent proximal objectives operate at a single scale and lack a principled mechanism for coupling token-level, trajectory-level, and higher-level hierarchical stability control. To bridge this gap, we derive the Aggregational Policy Censoring Objective (APC-Obj), the first exact unconstrained reformulation of sample-based TV-TRPO, establishing that clipping-based surrogate design and trust-region optimization are dual formulations of the same problem. Building on this foundation, we develop Fiber Bundle Gating (FBG), an algebraic framework that organizes sampled RL data as a fiber bundle and decomposes ratio gating into a base-level gate on trajectory aggregates and a fiber-level gate on per-token residuals, with provable first-order agreement with the true RL objective near on-policy. From APC-Obj and FBG we derive Fibration Policy Optimization (or simply, FiberPO), a concrete objective whose Jacobian is block-diagonal over trajectories, reduces to identity at on-policy, and provides better update direction thus improving token efficiency. The compositional nature of the framework extends beyond the trajectory-token case: fibrations compose algebraically into a Fibration Gating Hierarchy (FGH) that scales the same gating mechanism to arbitrary hierarchical depth without new primitives, as demonstrated by FiberPO-Domain, a four-level instantiation with independent trust-region budgets at the domain, prompt group, trajectory, and token levels. Together, these results connect the trust-region theory, a compositional algebraic structure, and practical multi-scale stability control into a unified framework for LLM policy optimization.
Reinforcement Learning Enhanced Multi-hop Reasoning for Temporal Knowledge Question Answering
Jan 03, 2026Temporal knowledge graph question answering (TKGQA) involves multi-hop reasoning over temporally constrained entity relationships in the knowledge graph to answer a given question. However, at each hop, large language models (LLMs) retrieve subgraphs with numerous temporally similar and semantically complex relations, increasing the risk of suboptimal decisions and error propagation. To address these challenges, we propose the multi-hop reasoning enhanced (MRE) framework, which enhances both forward and backward reasoning to improve the identification of globally optimal reasoning trajectories. Specifically, MRE begins with prompt engineering to guide the LLM in generating diverse reasoning trajectories for a given question. Valid reasoning trajectories are then selected for supervised fine-tuning, serving as a cold-start strategy. Finally, we introduce Tree-Group Relative Policy Optimization (T-GRPO), a recursive, tree-structured learning-by-exploration approach. At each hop, exploration establishes strong causal dependencies on the previous hop, while evaluation is informed by multi-path exploration feedback from subsequent hops. Experimental results on two TKGQA benchmarks indicate that the proposed MRE-based model consistently surpasses state-of-the-art (SOTA) approaches in handling complex multi-hop queries. Further analysis highlights improved interpretability and robustness to noisy temporal annotations.
Efficient Reasoning via Thought-Training and Thought-Free Inference
Nov 05, 2025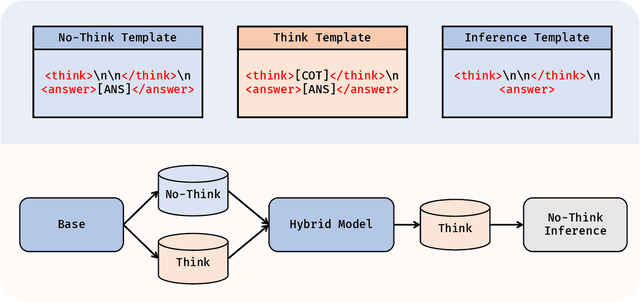
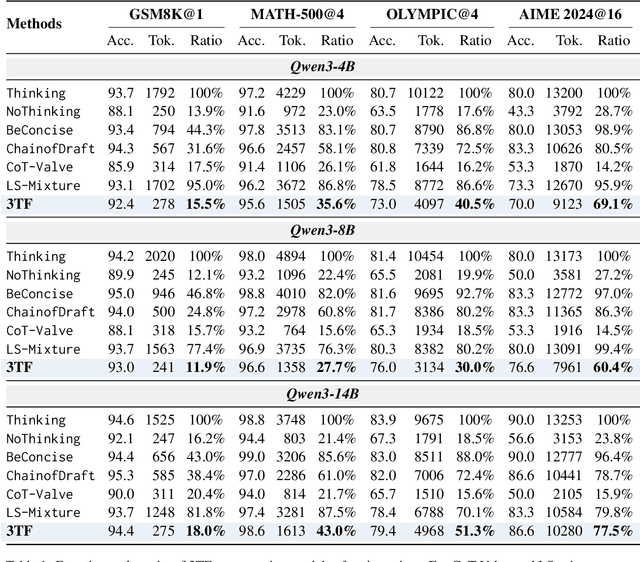
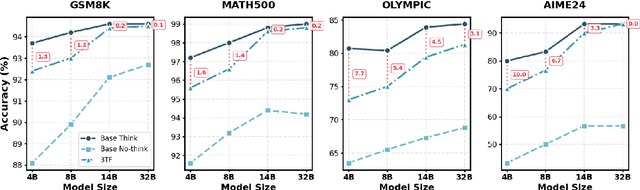
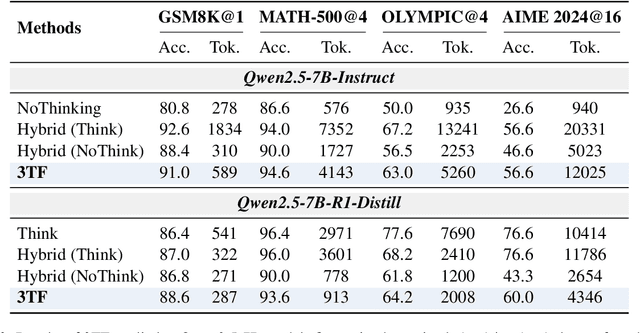
Recent advances in large language models (LLMs) have leveraged explicit Chain-of-Thought (CoT) prompting to improve reasoning accuracy. However, most existing methods primarily compress verbose reasoning outputs. These Long-to-Short transformations aim to improve efficiency, but still rely on explicit reasoning during inference. In this work, we introduce \textbf{3TF} (\textbf{T}hought-\textbf{T}raining and \textbf{T}hought-\textbf{F}ree inference), a framework for efficient reasoning that takes a Short-to-Long perspective. We first train a hybrid model that can operate in both reasoning and non-reasoning modes, and then further train it on CoT-annotated data to internalize structured reasoning, while enforcing concise, thought-free outputs at inference time using the no-reasoning mode. Unlike compression-based approaches, 3TF improves the reasoning quality of non-reasoning outputs, enabling models to perform rich internal reasoning implicitly while keeping external outputs short. Empirically, 3TF-trained models obtain large improvements on reasoning benchmarks under thought-free inference, demonstrating that high quality reasoning can be learned and executed implicitly without explicit step-by-step generation.
MotionFlux: Efficient Text-Guided Motion Generation through Rectified Flow Matching and Preference Alignment
Aug 27, 2025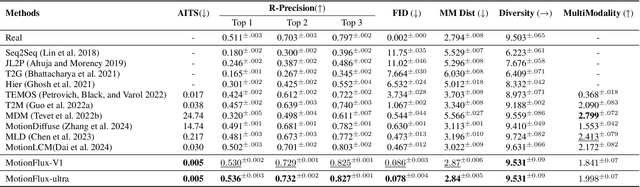
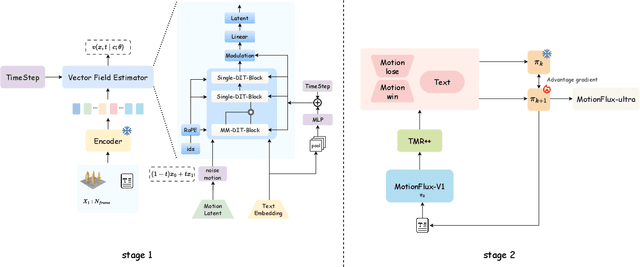
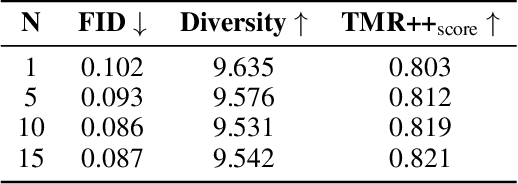
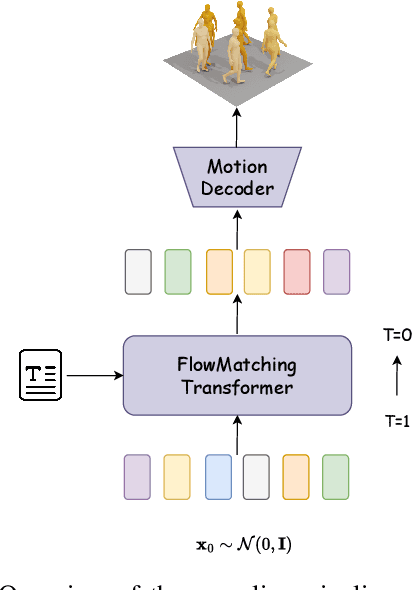
Motion generation is essential for animating virtual characters and embodied agents. While recent text-driven methods have made significant strides, they often struggle with achieving precise alignment between linguistic descriptions and motion semantics, as well as with the inefficiencies of slow, multi-step inference. To address these issues, we introduce TMR++ Aligned Preference Optimization (TAPO), an innovative framework that aligns subtle motion variations with textual modifiers and incorporates iterative adjustments to reinforce semantic grounding. To further enable real-time synthesis, we propose MotionFLUX, a high-speed generation framework based on deterministic rectified flow matching. Unlike traditional diffusion models, which require hundreds of denoising steps, MotionFLUX constructs optimal transport paths between noise distributions and motion spaces, facilitating real-time synthesis. The linearized probability paths reduce the need for multi-step sampling typical of sequential methods, significantly accelerating inference time without sacrificing motion quality. Experimental results demonstrate that, together, TAPO and MotionFLUX form a unified system that outperforms state-of-the-art approaches in both semantic consistency and motion quality, while also accelerating generation speed. The code and pretrained models will be released.
ChartMaster: Advancing Chart-to-Code Generation with Real-World Charts and Chart Similarity Reinforcement Learning
Aug 25, 2025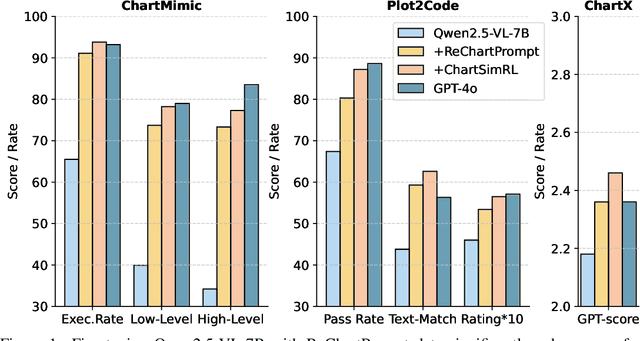

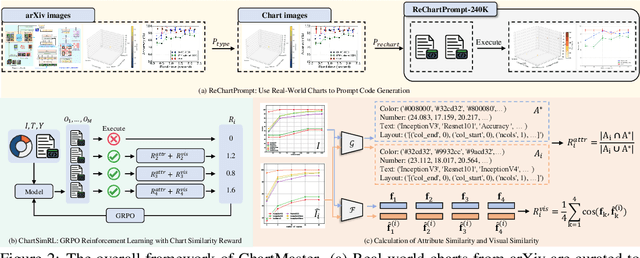

The chart-to-code generation task requires MLLMs to convert chart images into executable code. This task faces two major challenges: limited data diversity and insufficient maintenance of visual consistency between generated and original charts during training. Existing datasets mainly rely on seed data to prompt GPT models for code generation, resulting in homogeneous samples. To address this, we propose ReChartPrompt, which leverages real-world, human-designed charts from arXiv papers as prompts instead of synthetic seeds. Using the diverse styles and rich content of arXiv charts, we construct ReChartPrompt-240K, a large-scale and highly diverse dataset. Another challenge is that although SFT effectively improve code understanding, it often fails to ensure that generated charts are visually consistent with the originals. To address this, we propose ChartSimRL, a GRPO-based reinforcement learning algorithm guided by a novel chart similarity reward. This reward consists of attribute similarity, which measures the overlap of chart attributes such as layout and color between the generated and original charts, and visual similarity, which assesses similarity in texture and other overall visual features using convolutional neural networks. Unlike traditional text-based rewards such as accuracy or format rewards, our reward considers the multimodal nature of the chart-to-code task and effectively enhances the model's ability to accurately reproduce charts. By integrating ReChartPrompt and ChartSimRL, we develop the ChartMaster model, which achieves state-of-the-art results among 7B-parameter models and even rivals GPT-4o on various chart-to-code generation benchmarks. All resources are available at https://github.com/WentaoTan/ChartMaster.
Learning Temporal Abstractions via Variational Homomorphisms in Option-Induced Abstract MDPs
Jul 24, 2025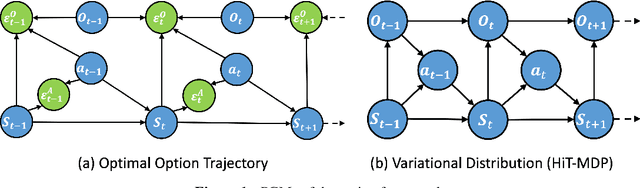
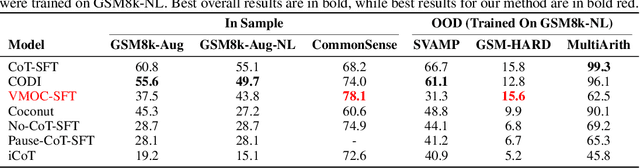
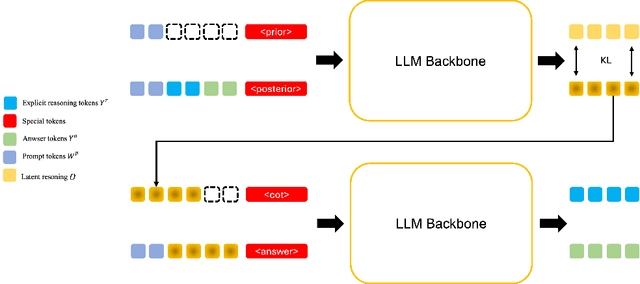
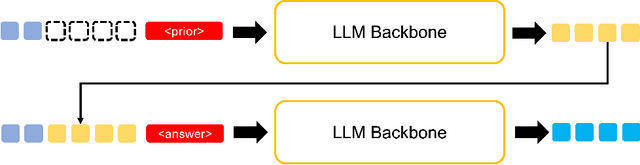
Large Language Models (LLMs) have shown remarkable reasoning ability through explicit Chain-of-Thought (CoT) prompting, but generating these step-by-step textual explanations is computationally expensive and slow. To overcome this, we aim to develop a framework for efficient, implicit reasoning, where the model "thinks" in a latent space without generating explicit text for every step. We propose that these latent thoughts can be modeled as temporally-extended abstract actions, or options, within a hierarchical reinforcement learning framework. To effectively learn a diverse library of options as latent embeddings, we first introduce the Variational Markovian Option Critic (VMOC), an off-policy algorithm that uses variational inference within the HiT-MDP framework. To provide a rigorous foundation for using these options as an abstract reasoning space, we extend the theory of continuous MDP homomorphisms. This proves that learning a policy in the simplified, abstract latent space, for which VMOC is suited, preserves the optimality of the solution to the original, complex problem. Finally, we propose a cold-start procedure that leverages supervised fine-tuning (SFT) data to distill human reasoning demonstrations into this latent option space, providing a rich initialization for the model's reasoning capabilities. Extensive experiments demonstrate that our approach achieves strong performance on complex logical reasoning benchmarks and challenging locomotion tasks, validating our framework as a principled method for learning abstract skills for both language and control.