 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe First Challenge on Remote Sensing Infrared Image Super-Resolution at NTIRE 2026: Benchmark Results and Method Overview
Apr 23, 2026This paper presents the NTIRE 2026 Remote Sensing Infrared Image Super-Resolution (x4) Challenge, one of the associated challenges of NTIRE 2026. The challenge aims to recover high-resolution (HR) infrared images from low-resolution (LR) inputs generated through bicubic downsampling with a x4 scaling factor. The objective is to develop effective models or solutions that achieve state-of-the-art performance for infrared image SR in remote sensing scenarios. To reflect the characteristics of infrared data and practical application needs, the challenge adopts a single-track setting. A total of 115 participants registered for the competition, with 13 teams submitting valid entries. This report summarizes the challenge design, dataset, evaluation protocol, main results, and the representative methods of each team. The challenge serves as a benchmark to advance research in infrared image super-resolution and promote the development of effective solutions for real-world remote sensing applications.
The Fourth Challenge on Image Super-Resolution ($\times$4) at NTIRE 2026: Benchmark Results and Method Overview
Apr 16, 2026This paper presents the NTIRE 2026 image super-resolution ($\times$4) challenge, one of the associated competitions of the NTIRE 2026 Workshop at CVPR 2026. The challenge aims to reconstruct high-resolution (HR) images from low-resolution (LR) inputs generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective super-resolution solutions and analyze recent advances in the field. To reflect the evolving objectives of image super-resolution, the challenge includes two tracks: (1) a restoration track, which emphasizes pixel-wise fidelity and ranks submissions based on PSNR; and (2) a perceptual track, which focuses on visual realism and evaluates results using a perceptual score. A total of 194 participants registered for the challenge, with 31 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, main results, and methods of participating teams. The challenge provides a unified benchmark and offers insights into current progress and future directions in image super-resolution.
JoyAI-LLM Flash: Advancing Mid-Scale LLMs with Token Efficiency
Apr 03, 2026We introduce JoyAI-LLM Flash, an efficient Mixture-of-Experts (MoE) language model designed to redefine the trade-off between strong performance and token efficiency in the sub-50B parameter regime. JoyAI-LLM Flash is pretrained on a massive corpus of 20 trillion tokens and further optimized through a rigorous post-training pipeline, including supervised fine-tuning (SFT), Direct Preference Optimization (DPO), and large-scale reinforcement learning (RL) across diverse environments. To improve token efficiency, JoyAI-LLM Flash strategically balances \emph{thinking} and \emph{non-thinking} cognitive modes and introduces FiberPO, a novel RL algorithm inspired by fibration theory that decomposes trust-region maintenance into global and local components, providing unified multi-scale stability control for LLM policy optimization. To enhance architectural sparsity, the model comprises 48B total parameters while activating only 2.7B parameters per forward pass, achieving a substantially higher sparsity ratio than contemporary industry leading models of comparable scale. To further improve inference throughput, we adopt a joint training-inference co-design that incorporates dense Multi-Token Prediction (MTP) and Quantization-Aware Training (QAT). We release the checkpoints for both JoyAI-LLM-48B-A3B Base and its post-trained variants on Hugging Face to support the open-source community.
Reconstruction-Anchored Diffusion Model for Text-to-Motion Generation
Jan 21, 2026Diffusion models have seen widespread adoption for text-driven human motion generation and related tasks due to their impressive generative capabilities and flexibility. However, current motion diffusion models face two major limitations: a representational gap caused by pre-trained text encoders that lack motion-specific information, and error propagation during the iterative denoising process. This paper introduces Reconstruction-Anchored Diffusion Model (RAM) to address these challenges. First, RAM leverages a motion latent space as intermediate supervision for text-to-motion generation. To this end, RAM co-trains a motion reconstruction branch with two key objective functions: self-regularization to enhance the discrimination of the motion space and motion-centric latent alignment to enable accurate mapping from text to the motion latent space. Second, we propose Reconstructive Error Guidance (REG), a testing-stage guidance mechanism that exploits the diffusion model's inherent self-correction ability to mitigate error propagation. At each denoising step, REG uses the motion reconstruction branch to reconstruct the previous estimate, reproducing the prior error patterns. By amplifying the residual between the current prediction and the reconstructed estimate, REG highlights the improvements in the current prediction. Extensive experiments demonstrate that RAM achieves significant improvements and state-of-the-art performance. Our code will be released.
Efficient Reasoning via Thought-Training and Thought-Free Inference
Nov 05, 2025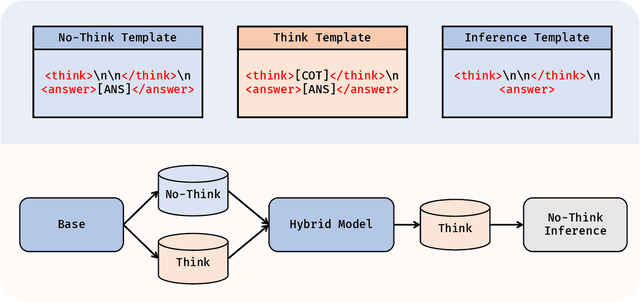
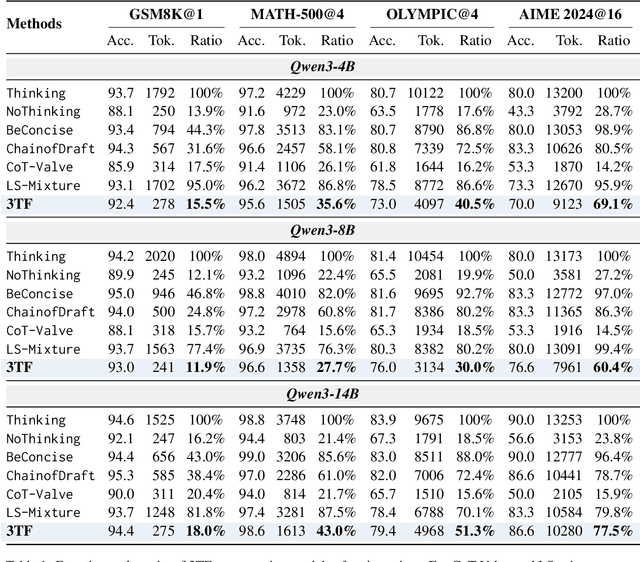
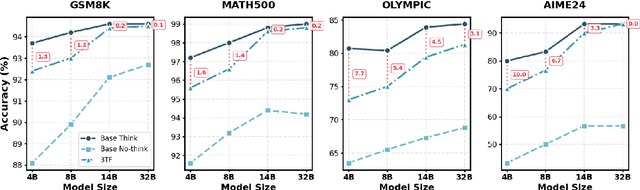
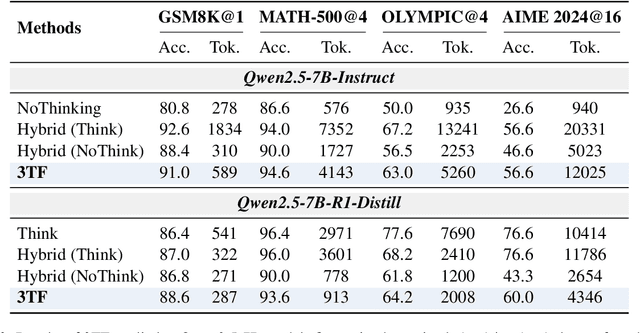
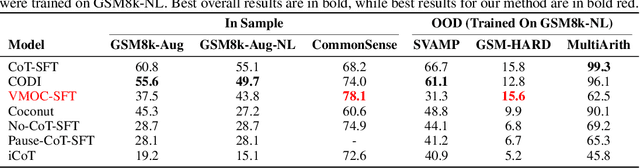
Recent advances in large language models (LLMs) have leveraged explicit Chain-of-Thought (CoT) prompting to improve reasoning accuracy. However, most existing methods primarily compress verbose reasoning outputs. These Long-to-Short transformations aim to improve efficiency, but still rely on explicit reasoning during inference. In this work, we introduce \textbf{3TF} (\textbf{T}hought-\textbf{T}raining and \textbf{T}hought-\textbf{F}ree inference), a framework for efficient reasoning that takes a Short-to-Long perspective. We first train a hybrid model that can operate in both reasoning and non-reasoning modes, and then further train it on CoT-annotated data to internalize structured reasoning, while enforcing concise, thought-free outputs at inference time using the no-reasoning mode. Unlike compression-based approaches, 3TF improves the reasoning quality of non-reasoning outputs, enabling models to perform rich internal reasoning implicitly while keeping external outputs short. Empirically, 3TF-trained models obtain large improvements on reasoning benchmarks under thought-free inference, demonstrating that high quality reasoning can be learned and executed implicitly without explicit step-by-step generation.
ChartMaster: Advancing Chart-to-Code Generation with Real-World Charts and Chart Similarity Reinforcement Learning
Aug 25, 2025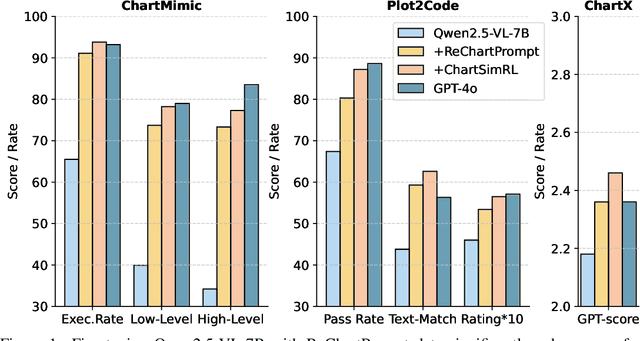

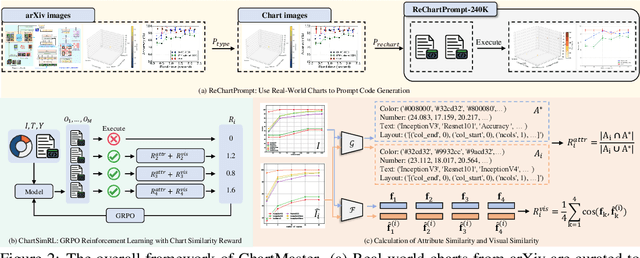

The chart-to-code generation task requires MLLMs to convert chart images into executable code. This task faces two major challenges: limited data diversity and insufficient maintenance of visual consistency between generated and original charts during training. Existing datasets mainly rely on seed data to prompt GPT models for code generation, resulting in homogeneous samples. To address this, we propose ReChartPrompt, which leverages real-world, human-designed charts from arXiv papers as prompts instead of synthetic seeds. Using the diverse styles and rich content of arXiv charts, we construct ReChartPrompt-240K, a large-scale and highly diverse dataset. Another challenge is that although SFT effectively improve code understanding, it often fails to ensure that generated charts are visually consistent with the originals. To address this, we propose ChartSimRL, a GRPO-based reinforcement learning algorithm guided by a novel chart similarity reward. This reward consists of attribute similarity, which measures the overlap of chart attributes such as layout and color between the generated and original charts, and visual similarity, which assesses similarity in texture and other overall visual features using convolutional neural networks. Unlike traditional text-based rewards such as accuracy or format rewards, our reward considers the multimodal nature of the chart-to-code task and effectively enhances the model's ability to accurately reproduce charts. By integrating ReChartPrompt and ChartSimRL, we develop the ChartMaster model, which achieves state-of-the-art results among 7B-parameter models and even rivals GPT-4o on various chart-to-code generation benchmarks. All resources are available at https://github.com/WentaoTan/ChartMaster.
Learning Temporal Abstractions via Variational Homomorphisms in Option-Induced Abstract MDPs
Jul 24, 2025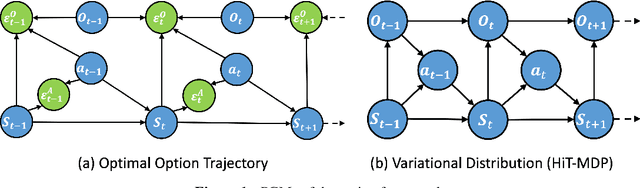
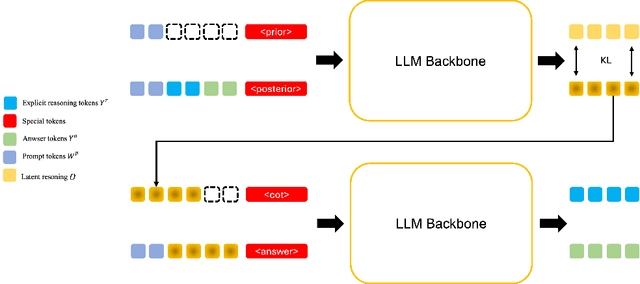
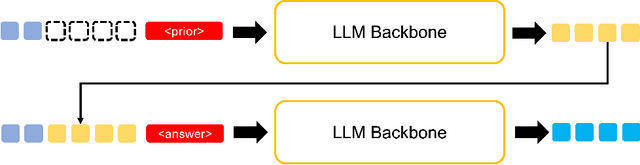
Large Language Models (LLMs) have shown remarkable reasoning ability through explicit Chain-of-Thought (CoT) prompting, but generating these step-by-step textual explanations is computationally expensive and slow. To overcome this, we aim to develop a framework for efficient, implicit reasoning, where the model "thinks" in a latent space without generating explicit text for every step. We propose that these latent thoughts can be modeled as temporally-extended abstract actions, or options, within a hierarchical reinforcement learning framework. To effectively learn a diverse library of options as latent embeddings, we first introduce the Variational Markovian Option Critic (VMOC), an off-policy algorithm that uses variational inference within the HiT-MDP framework. To provide a rigorous foundation for using these options as an abstract reasoning space, we extend the theory of continuous MDP homomorphisms. This proves that learning a policy in the simplified, abstract latent space, for which VMOC is suited, preserves the optimality of the solution to the original, complex problem. Finally, we propose a cold-start procedure that leverages supervised fine-tuning (SFT) data to distill human reasoning demonstrations into this latent option space, providing a rich initialization for the model's reasoning capabilities. Extensive experiments demonstrate that our approach achieves strong performance on complex logical reasoning benchmarks and challenging locomotion tasks, validating our framework as a principled method for learning abstract skills for both language and control.
AP-CAP: Advancing High-Quality Data Synthesis for Animal Pose Estimation via a Controllable Image Generation Pipeline
Apr 01, 2025The task of 2D animal pose estimation plays a crucial role in advancing deep learning applications in animal behavior analysis and ecological research. Despite notable progress in some existing approaches, our study reveals that the scarcity of high-quality datasets remains a significant bottleneck, limiting the full potential of current methods. To address this challenge, we propose a novel Controllable Image Generation Pipeline for synthesizing animal pose estimation data, termed AP-CAP. Within this pipeline, we introduce a Multi-Modal Animal Image Generation Model capable of producing images with expected poses. To enhance the quality and diversity of the generated data, we further propose three innovative strategies: (1) Modality-Fusion-Based Animal Image Synthesis Strategy to integrate multi-source appearance representations, (2) Pose-Adjustment-Based Animal Image Synthesis Strategy to dynamically capture diverse pose variations, and (3) Caption-Enhancement-Based Animal Image Synthesis Strategy to enrich visual semantic understanding. Leveraging the proposed model and strategies, we create the MPCH Dataset (Modality-Pose-Caption Hybrid), the first hybrid dataset that innovatively combines synthetic and real data, establishing the largest-scale multi-source heterogeneous benchmark repository for animal pose estimation to date. Extensive experiments demonstrate the superiority of our method in improving both the performance and generalization capability of animal pose estimators.
Beyond Human Data: Aligning Multimodal Large Language Models by Iterative Self-Evolution
Dec 20, 2024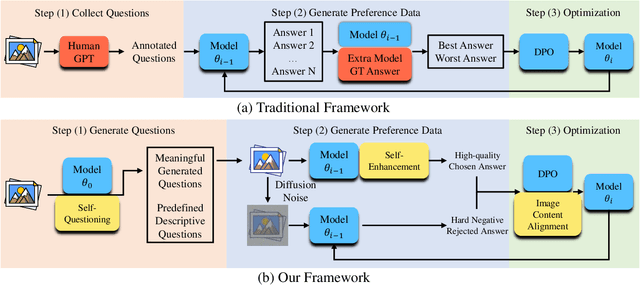



Human preference alignment can greatly enhance Multimodal Large Language Models (MLLMs), but collecting high-quality preference data is costly. A promising solution is the self-evolution strategy, where models are iteratively trained on data they generate. However, current techniques still rely on human- or GPT-annotated data and sometimes require additional models or ground truth answers. To address these issues, we propose a novel multimodal self-evolution framework that enables the model to autonomously generate high-quality questions and answers using only unannotated images. First, we implement an image-driven self-questioning mechanism, allowing the model to create and evaluate questions based on image content, regenerating them if they are irrelevant or unanswerable. This sets a strong foundation for answer generation. Second, we introduce an answer self-enhancement technique, starting with image captioning to improve answer quality. We also use corrupted images to generate rejected answers, forming distinct preference pairs for optimization. Finally, we incorporate an image content alignment loss function alongside Direct Preference Optimization (DPO) loss to reduce hallucinations, ensuring the model focuses on image content. Experiments show that our framework performs competitively with methods using external information, offering a more efficient and scalable approach to MLLMs.
Temporal-Enhanced Multimodal Transformer for Referring Multi-Object Tracking and Segmentation
Oct 17, 2024



Referring multi-object tracking (RMOT) is an emerging cross-modal task that aims to locate an arbitrary number of target objects and maintain their identities referred by a language expression in a video. This intricate task involves the reasoning of linguistic and visual modalities, along with the temporal association of target objects. However, the seminal work employs only loose feature fusion and overlooks the utilization of long-term information on tracked objects. In this study, we introduce a compact Transformer-based method, termed TenRMOT. We conduct feature fusion at both encoding and decoding stages to fully exploit the advantages of Transformer architecture. Specifically, we incrementally perform cross-modal fusion layer-by-layer during the encoding phase. In the decoding phase, we utilize language-guided queries to probe memory features for accurate prediction of the desired objects. Moreover, we introduce a query update module that explicitly leverages temporal prior information of the tracked objects to enhance the consistency of their trajectories. In addition, we introduce a novel task called Referring Multi-Object Tracking and Segmentation (RMOTS) and construct a new dataset named Ref-KITTI Segmentation. Our dataset consists of 18 videos with 818 expressions, and each expression averages 10.7 masks, which poses a greater challenge compared to the typical single mask in most existing referring video segmentation datasets. TenRMOT demonstrates superior performance on both the referring multi-object tracking and the segmentation tasks.