 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJOintGS: Joint Optimization of Cameras, Bodies and 3D Gaussians for In-the-Wild Monocular Reconstruction
Feb 04, 2026Reconstructing high-fidelity animatable 3D human avatars from monocular RGB videos remains challenging, particularly in unconstrained in-the-wild scenarios where camera parameters and human poses from off-the-shelf methods (e.g., COLMAP, HMR2.0) are often inaccurate. Splatting (3DGS) advances demonstrate impressive rendering quality and real-time performance, they critically depend on precise camera calibration and pose annotations, limiting their applicability in real-world settings. We present JOintGS, a unified framework that jointly optimizes camera extrinsics, human poses, and 3D Gaussian representations from coarse initialization through a synergistic refinement mechanism. Our key insight is that explicit foreground-background disentanglement enables mutual reinforcement: static background Gaussians anchor camera estimation via multi-view consistency; refined cameras improve human body alignment through accurate temporal correspondence; optimized human poses enhance scene reconstruction by removing dynamic artifacts from static constraints. We further introduce a temporal dynamics module to capture fine-grained pose-dependent deformations and a residual color field to model illumination variations. Extensive experiments on NeuMan and EMDB datasets demonstrate that JOintGS achieves superior reconstruction quality, with 2.1~dB PSNR improvement over state-of-the-art methods on NeuMan dataset, while maintaining real-time rendering. Notably, our method shows significantly enhanced robustness to noisy initialization compared to the baseline.Our source code is available at https://github.com/MiliLab/JOintGS.
End-to-End HOI Reconstruction Transformer with Graph-based Encoding
Mar 08, 2025



With the diversification of human-object interaction (HOI) applications and the success of capturing human meshes, HOI reconstruction has gained widespread attention. Existing mainstream HOI reconstruction methods often rely on explicitly modeling interactions between humans and objects. However, such a way leads to a natural conflict between 3D mesh reconstruction, which emphasizes global structure, and fine-grained contact reconstruction, which focuses on local details. To address the limitations of explicit modeling, we propose the End-to-End HOI Reconstruction Transformer with Graph-based Encoding (HOI-TG). It implicitly learns the interaction between humans and objects by leveraging self-attention mechanisms. Within the transformer architecture, we devise graph residual blocks to aggregate the topology among vertices of different spatial structures. This dual focus effectively balances global and local representations. Without bells and whistles, HOI-TG achieves state-of-the-art performance on BEHAVE and InterCap datasets. Particularly on the challenging InterCap dataset, our method improves the reconstruction results for human and object meshes by 8.9% and 8.6%, respectively.
PoseBench: Benchmarking the Robustness of Pose Estimation Models under Corruptions
Jun 20, 2024



Pose estimation aims to accurately identify anatomical keypoints in humans and animals using monocular images, which is crucial for various applications such as human-machine interaction, embodied AI, and autonomous driving. While current models show promising results, they are typically trained and tested on clean data, potentially overlooking the corruption during real-world deployment and thus posing safety risks in practical scenarios. To address this issue, we introduce PoseBench, a comprehensive benchmark designed to evaluate the robustness of pose estimation models against real-world corruption. We evaluated 60 representative models, including top-down, bottom-up, heatmap-based, regression-based, and classification-based methods, across three datasets for human and animal pose estimation. Our evaluation involves 10 types of corruption in four categories: 1) blur and noise, 2) compression and color loss, 3) severe lighting, and 4) masks. Our findings reveal that state-of-the-art models are vulnerable to common real-world corruptions and exhibit distinct behaviors when tackling human and animal pose estimation tasks. To improve model robustness, we delve into various design considerations, including input resolution, pre-training datasets, backbone capacity, post-processing, and data augmentations. We hope that our benchmark will serve as a foundation for advancing research in robust pose estimation. The benchmark and source code will be released at https://xymsh.github.io/PoseBench
Contact-aware Human Motion Generation from Textual Descriptions
Mar 23, 2024

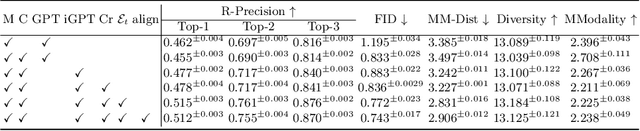

This paper addresses the problem of generating 3D interactive human motion from text. Given a textual description depicting the actions of different body parts in contact with objects, we synthesize sequences of 3D body poses that are visually natural and physically plausible. Yet, this task poses a significant challenge due to the inadequate consideration of interactions by physical contacts in both motion and textual descriptions, leading to unnatural and implausible sequences. To tackle this challenge, we create a novel dataset named RICH-CAT, representing ``Contact-Aware Texts'' constructed from the RICH dataset. RICH-CAT comprises high-quality motion, accurate human-object contact labels, and detailed textual descriptions, encompassing over 8,500 motion-text pairs across 26 indoor/outdoor actions. Leveraging RICH-CAT, we propose a novel approach named CATMO for text-driven interactive human motion synthesis that explicitly integrates human body contacts as evidence. We employ two VQ-VAE models to encode motion and body contact sequences into distinct yet complementary latent spaces and an intertwined GPT for generating human motions and contacts in a mutually conditioned manner. Additionally, we introduce a pre-trained text encoder to learn textual embeddings that better discriminate among various contact types, allowing for more precise control over synthesized motions and contacts. Our experiments demonstrate the superior performance of our approach compared to existing text-to-motion methods, producing stable, contact-aware motion sequences. Code and data will be available for research purposes.
GraMMaR: Ground-aware Motion Model for 3D Human Motion Reconstruction
Jul 01, 2023



Demystifying complex human-ground interactions is essential for accurate and realistic 3D human motion reconstruction from RGB videos, as it ensures consistency between the humans and the ground plane. Prior methods have modeled human-ground interactions either implicitly or in a sparse manner, often resulting in unrealistic and incorrect motions when faced with noise and uncertainty. In contrast, our approach explicitly represents these interactions in a dense and continuous manner. To this end, we propose a novel Ground-aware Motion Model for 3D Human Motion Reconstruction, named GraMMaR, which jointly learns the distribution of transitions in both pose and interaction between every joint and ground plane at each time step of a motion sequence. It is trained to explicitly promote consistency between the motion and distance change towards the ground. After training, we establish a joint optimization strategy that utilizes GraMMaR as a dual-prior, regularizing the optimization towards the space of plausible ground-aware motions. This leads to realistic and coherent motion reconstruction, irrespective of the assumed or learned ground plane. Through extensive evaluation on the AMASS and AIST++ datasets, our model demonstrates good generalization and discriminating abilities in challenging cases including complex and ambiguous human-ground interactions. The code will be released.
Rethinking Portrait Matting with Privacy Preserving
Mar 31, 2022


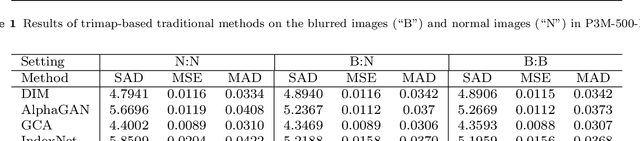
Recently, there has been an increasing concern about the privacy issue raised by using personally identifiable information in machine learning. However, previous portrait matting methods were all based on identifiable portrait images. To fill the gap, we present P3M-10k in this paper, which is the first large-scale anonymized benchmark for Privacy-Preserving Portrait Matting (P3M). P3M-10k consists of 10,000 high-resolution face-blurred portrait images along with high-quality alpha mattes. We systematically evaluate both trimap-free and trimap-based matting methods on P3M-10k and find that existing matting methods show different generalization abilities under the privacy preserving training setting, i.e., training only on face-blurred images while testing on arbitrary images. Based on the gained insights, we propose a unified matting model named P3M-Net consisting of three carefully designed integration modules that can perform privacy-insensitive semantic perception and detail-reserved matting simultaneously. We further design multiple variants of P3M-Net with different CNN and transformer backbones and identify the difference in their generalization abilities. To further mitigate this issue, we devise a simple yet effective Copy and Paste strategy (P3M-CP) that can borrow facial information from public celebrity images without privacy concerns and direct the network to reacquire the face context at both data and feature levels. P3M-CP only brings a few additional computations during training, while enabling the matting model to process both face-blurred and normal images without extra effort during inference. Extensive experiments on P3M-10k demonstrate the superiority of P3M-Net over state-of-the-art methods and the effectiveness of P3M-CP in improving the generalization ability of P3M-Net, implying a great significance of P3M for future research and real-world applications.
Privacy-Preserving Portrait Matting
Apr 29, 2021



Recently, there has been an increasing concern about the privacy issue raised by using personally identifiable information in machine learning. However, previous portrait matting methods were all based on identifiable portrait images. To fill the gap, we present P3M-10k in this paper, which is the first large-scale anonymized benchmark for Privacy-Preserving Portrait Matting. P3M-10k consists of 10,000 high-resolution face-blurred portrait images along with high-quality alpha mattes. We systematically evaluate both trimap-free and trimap-based matting methods on P3M-10k and find that existing matting methods show different generalization capabilities when following the Privacy-Preserving Training (PPT) setting, i.e., "training on face-blurred images and testing on arbitrary images". To devise a better trimap-free portrait matting model, we propose P3M-Net, which leverages the power of a unified framework for both semantic perception and detail matting, and specifically emphasizes the interaction between them and the encoder to facilitate the matting process. Extensive experiments on P3M-10k demonstrate that P3M-Net outperforms the state-of-the-art methods in terms of both objective metrics and subjective visual quality. Besides, it shows good generalization capacity under the PPT setting, confirming the value of P3M-10k for facilitating future research and enabling potential real-world applications. The source code and dataset will be made publicly available.