 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Image Matting: A Comprehensive Survey
Apr 10, 2023Image matting refers to extracting precise alpha matte from natural images, and it plays a critical role in various downstream applications, such as image editing. Despite being an ill-posed problem, traditional methods have been trying to solve it for decades. The emergence of deep learning has revolutionized the field of image matting and given birth to multiple new techniques, including automatic, interactive, and referring image matting. This paper presents a comprehensive review of recent advancements in image matting in the era of deep learning. We focus on two fundamental sub-tasks: auxiliary input-based image matting, which involves user-defined input to predict the alpha matte, and automatic image matting, which generates results without any manual intervention. We systematically review the existing methods for these two tasks according to their task settings and network structures and provide a summary of their advantages and disadvantages. Furthermore, we introduce the commonly used image matting datasets and evaluate the performance of representative matting methods both quantitatively and qualitatively. Finally, we discuss relevant applications of image matting and highlight existing challenges and potential opportunities for future research. We also maintain a public repository to track the rapid development of deep image matting at https://github.com/JizhiziLi/matting-survey.
Referring Image Matting
Jun 10, 2022


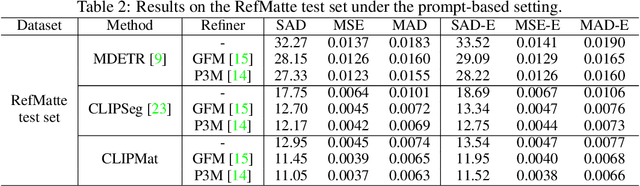
Image matting refers to extracting the accurate foregrounds in the image. Current automatic methods tend to extract all the salient objects in the image indiscriminately. In this paper, we propose a new task named Referring Image Matting (RIM), referring to extracting the meticulous alpha matte of the specific object that can best match the given natural language description. However, prevalent visual grounding methods are all limited to the segmentation level, probably due to the lack of high-quality datasets for RIM. To fill the gap, we establish the first large-scale challenging dataset RefMatte by designing a comprehensive image composition and expression generation engine to produce synthetic images on top of current public high-quality matting foregrounds with flexible logics and re-labelled diverse attributes. RefMatte consists of 230 object categories, 47,500 images, 118,749 expression-region entities, and 474,996 expressions, which can be further extended easily in the future. Besides this, we also construct a real-world test set with manually generated phrase annotations consisting of 100 natural images to further evaluate the generalization of RIM models. We first define the task of RIM in two settings, i.e., prompt-based and expression-based, and then benchmark several representative methods together with specific model designs for image matting. The results provide empirical insights into the limitations of existing methods as well as possible solutions. We believe the new task RIM along with the RefMatte dataset will open new research directions in this area and facilitate future studies. The dataset and code will be made publicly available at https://github.com/JizhiziLi/RIM.
Rethinking Portrait Matting with Privacy Preserving
Mar 31, 2022


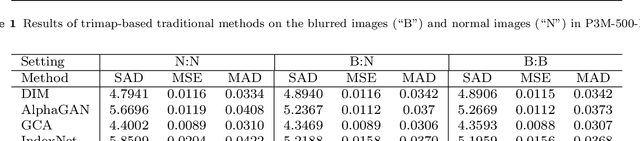
Recently, there has been an increasing concern about the privacy issue raised by using personally identifiable information in machine learning. However, previous portrait matting methods were all based on identifiable portrait images. To fill the gap, we present P3M-10k in this paper, which is the first large-scale anonymized benchmark for Privacy-Preserving Portrait Matting (P3M). P3M-10k consists of 10,000 high-resolution face-blurred portrait images along with high-quality alpha mattes. We systematically evaluate both trimap-free and trimap-based matting methods on P3M-10k and find that existing matting methods show different generalization abilities under the privacy preserving training setting, i.e., training only on face-blurred images while testing on arbitrary images. Based on the gained insights, we propose a unified matting model named P3M-Net consisting of three carefully designed integration modules that can perform privacy-insensitive semantic perception and detail-reserved matting simultaneously. We further design multiple variants of P3M-Net with different CNN and transformer backbones and identify the difference in their generalization abilities. To further mitigate this issue, we devise a simple yet effective Copy and Paste strategy (P3M-CP) that can borrow facial information from public celebrity images without privacy concerns and direct the network to reacquire the face context at both data and feature levels. P3M-CP only brings a few additional computations during training, while enabling the matting model to process both face-blurred and normal images without extra effort during inference. Extensive experiments on P3M-10k demonstrate the superiority of P3M-Net over state-of-the-art methods and the effectiveness of P3M-CP in improving the generalization ability of P3M-Net, implying a great significance of P3M for future research and real-world applications.
Deep Automatic Natural Image Matting
Jul 15, 2021



Automatic image matting (AIM) refers to estimating the soft foreground from an arbitrary natural image without any auxiliary input like trimap, which is useful for image editing. Prior methods try to learn semantic features to aid the matting process while being limited to images with salient opaque foregrounds such as humans and animals. In this paper, we investigate the difficulties when extending them to natural images with salient transparent/meticulous foregrounds or non-salient foregrounds. To address the problem, a novel end-to-end matting network is proposed, which can predict a generalized trimap for any image of the above types as a unified semantic representation. Simultaneously, the learned semantic features guide the matting network to focus on the transition areas via an attention mechanism. We also construct a test set AIM-500 that contains 500 diverse natural images covering all types along with manually labeled alpha mattes, making it feasible to benchmark the generalization ability of AIM models. Results of the experiments demonstrate that our network trained on available composite matting datasets outperforms existing methods both objectively and subjectively. The source code and dataset are available at https://github.com/JizhiziLi/AIM.
Privacy-Preserving Portrait Matting
Apr 29, 2021



Recently, there has been an increasing concern about the privacy issue raised by using personally identifiable information in machine learning. However, previous portrait matting methods were all based on identifiable portrait images. To fill the gap, we present P3M-10k in this paper, which is the first large-scale anonymized benchmark for Privacy-Preserving Portrait Matting. P3M-10k consists of 10,000 high-resolution face-blurred portrait images along with high-quality alpha mattes. We systematically evaluate both trimap-free and trimap-based matting methods on P3M-10k and find that existing matting methods show different generalization capabilities when following the Privacy-Preserving Training (PPT) setting, i.e., "training on face-blurred images and testing on arbitrary images". To devise a better trimap-free portrait matting model, we propose P3M-Net, which leverages the power of a unified framework for both semantic perception and detail matting, and specifically emphasizes the interaction between them and the encoder to facilitate the matting process. Extensive experiments on P3M-10k demonstrate that P3M-Net outperforms the state-of-the-art methods in terms of both objective metrics and subjective visual quality. Besides, it shows good generalization capacity under the PPT setting, confirming the value of P3M-10k for facilitating future research and enabling potential real-world applications. The source code and dataset will be made publicly available.
End-to-end Animal Image Matting
Oct 30, 2020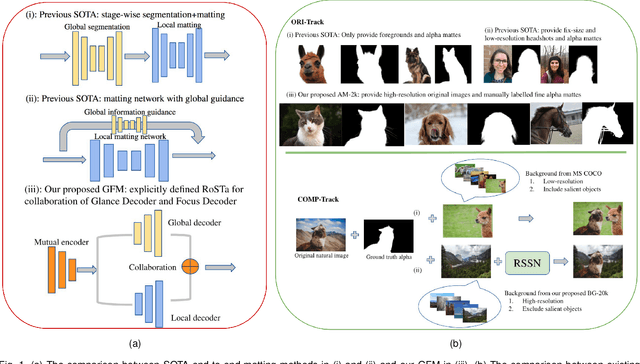
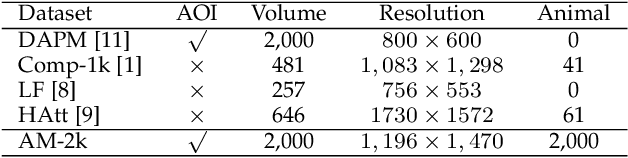
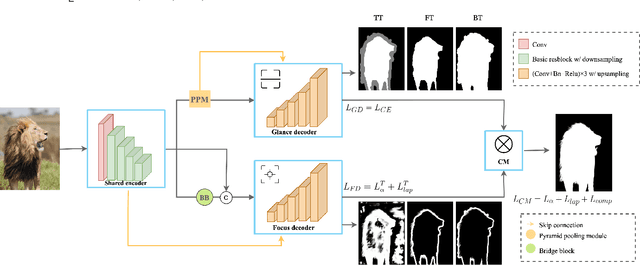
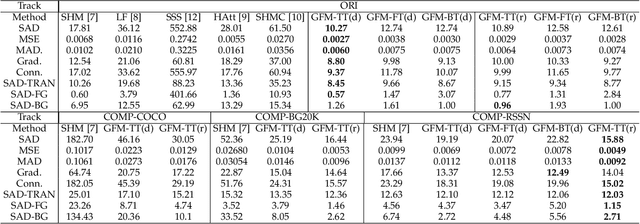
Extracting accurate foreground animals from natural animal images benefits many downstream applications such as film production and augmented reality. However, the various appearance and furry characteristics of animals challenge existing matting methods, which usually require extra user inputs such as trimap or scribbles. To resolve these problems, we study the distinct roles of semantics and details for image matting and decompose the task into two parallel sub-tasks: high-level semantic segmentation and low-level details matting. Specifically, we propose a novel Glance and Focus Matting network (GFM), which employs a shared encoder and two separate decoders to learn both tasks in a collaborative manner for end-to-end animal image matting. Besides, we establish a novel Animal Matting dataset (AM-2k) containing 2,000 high-resolution natural animal images from 20 categories along with manually labeled alpha mattes. Furthermore, we investigate the domain gap issue between composite images and natural images systematically by conducting comprehensive analyses of various discrepancies between foreground and background images. We find that a carefully designed composition route RSSN that aims to reduce the discrepancies can lead to a better model with remarkable generalization ability. Comprehensive empirical studies on AM-2k demonstrate that GFM outperforms state-of-the-art methods and effectively reduces the generalization error.