 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDUT: Learning Video Stabilization by Simply Watching Unstable Videos
Dec 01, 2020
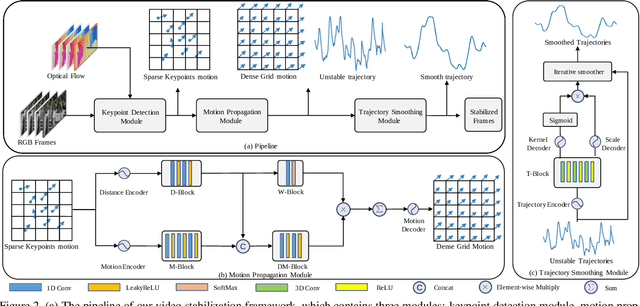


We propose a Deep Unsupervised Trajectory-based stabilization framework (DUT) in this paper. Traditional stabilizers focus on trajectory-based smoothing, which is controllable but fragile in occluded and textureless cases regarding the usage of hand-crafted features. On the other hand, previous deep video stabilizers directly generate stable videos in a supervised manner without explicit trajectory estimation, which is robust but less controllable and the appropriate paired data are hard to obtain. To construct a controllable and robust stabilizer, DUT makes the first attempt to stabilize unstable videos by explicitly estimating and smoothing trajectories in an unsupervised deep learning manner, which is composed of a DNN-based keypoint detector and motion estimator to generate grid-based trajectories, and a DNN-based trajectory smoother to stabilize videos. We exploit both the nature of continuity in motion and the consistency of keypoints and grid vertices before and after stabilization for unsupervised training. Experiment results on public benchmarks show that DUT outperforms representative state-of-the-art methods both qualitatively and quantitatively.
End-to-end Animal Image Matting
Oct 30, 2020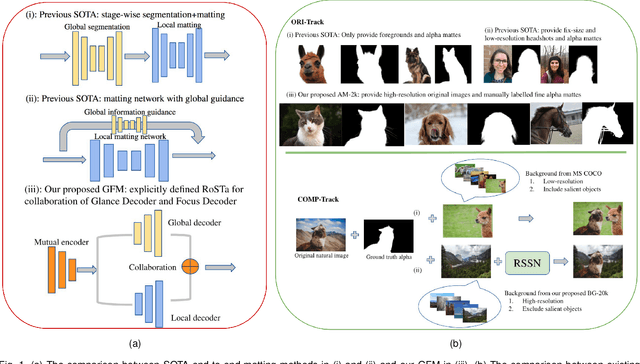
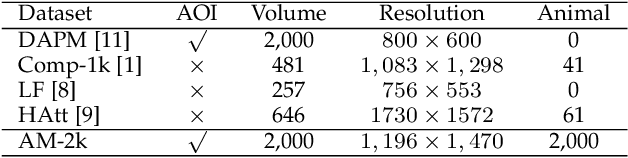
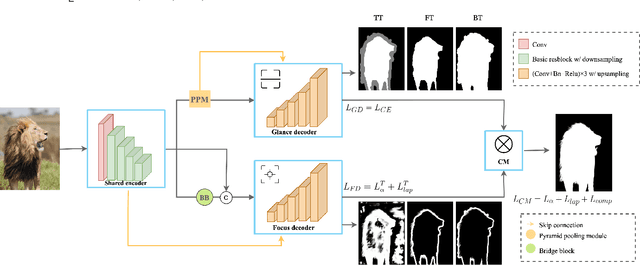
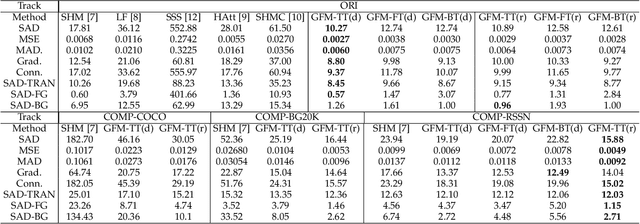
Extracting accurate foreground animals from natural animal images benefits many downstream applications such as film production and augmented reality. However, the various appearance and furry characteristics of animals challenge existing matting methods, which usually require extra user inputs such as trimap or scribbles. To resolve these problems, we study the distinct roles of semantics and details for image matting and decompose the task into two parallel sub-tasks: high-level semantic segmentation and low-level details matting. Specifically, we propose a novel Glance and Focus Matting network (GFM), which employs a shared encoder and two separate decoders to learn both tasks in a collaborative manner for end-to-end animal image matting. Besides, we establish a novel Animal Matting dataset (AM-2k) containing 2,000 high-resolution natural animal images from 20 categories along with manually labeled alpha mattes. Furthermore, we investigate the domain gap issue between composite images and natural images systematically by conducting comprehensive analyses of various discrepancies between foreground and background images. We find that a carefully designed composition route RSSN that aims to reduce the discrepancies can lead to a better model with remarkable generalization ability. Comprehensive empirical studies on AM-2k demonstrate that GFM outperforms state-of-the-art methods and effectively reduces the generalization error.
Self-supervised Exposure Trajectory Recovery for Dynamic Blur Estimation
Oct 06, 2020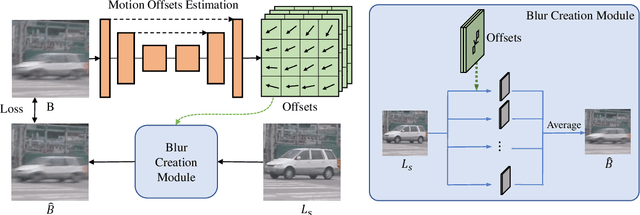
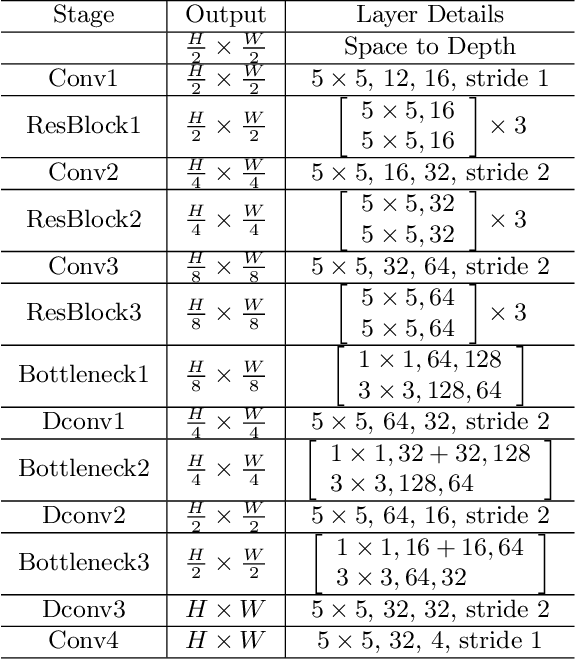
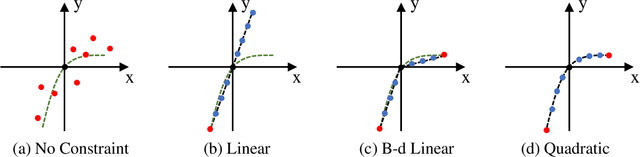
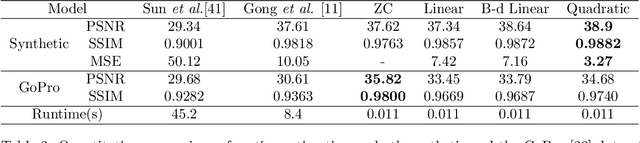
Dynamic scene blurring is an important yet challenging topic. Recently, deep learning methods have achieved impressive performance for dynamic scene deblurring. However, the motion information contained in a blurry image has yet to be fully explored and accurately formulated because: (i) the ground truth of blurry motion is difficult to obtain; (ii) the temporal ordering is destroyed during the exposure; and (iii) the motion estimation is highly ill-posed. By revisiting the principle of camera exposure, dynamic blur can be described by the relative motions of sharp content with respect to each exposed pixel. We define exposure trajectories, which record the trajectories of relative motions to represent the motion information contained in a blurry image and explain the causes of the dynamic blur. A new blur representation, which we call motion offset, is proposed to model pixel-wise displacements of the latent sharp image at multiple timepoints. Under mild constraints, the learned motion offsets can recover dense, (non-)linear exposure trajectories, which significantly reduce temporal disorder and ill-posed problems. Finally, we demonstrate that the estimated exposure trajectories can fit real-world dynamic blurs and further contribute to motion-aware image deblurring and warping-based video extraction from a single blurry image.
Adversarial Attacks for Embodied Agents
May 19, 2020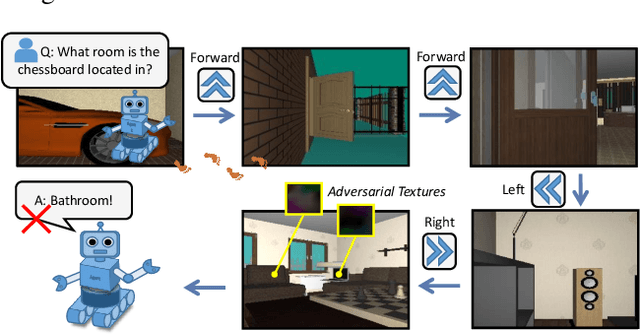
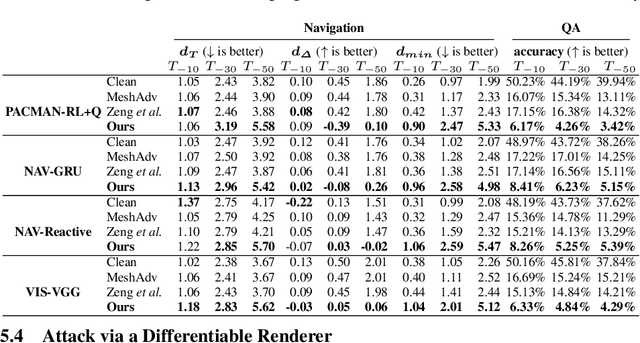
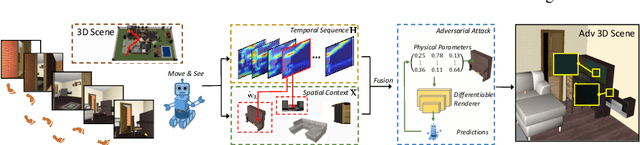

Adversarial attacks are valuable for providing insights into the blind-spots of deep learning models and help improve their robustness. Existing work on adversarial attacks have mainly focused on static scenes; however, it remains unclear whether such attacks are effective against embodied agents, which could navigate and interact with a dynamic environment. In this work, we take the first step to study adversarial attacks for embodied agents. In particular, we generate spatiotemporal perturbations to form 3D adversarial examples, which exploit the interaction history in both the temporal and spatial dimensions. Regarding the temporal dimension, since agents make predictions based on historical observations, we develop a trajectory attention module to explore scene view contributions, which further help localize 3D objects appeared with the highest stimuli. By conciliating with clues from the temporal dimension, along the spatial dimension, we adversarially perturb the physical properties (e.g., texture and 3D shape) of the contextual objects that appeared in the most important scene views. Extensive experiments on the EQA-v1 dataset for several embodied tasks in both the white-box and black-box settings have been conducted, which demonstrate that our perturbations have strong attack and generalization abilities.
Feedback Graph Convolutional Network for Skeleton-based Action Recognition
Mar 17, 2020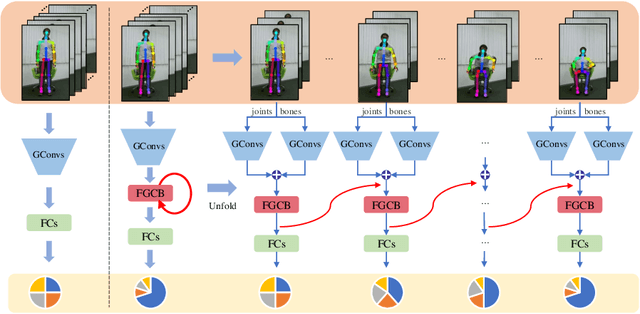



Skeleton-based action recognition has attracted considerable attention in computer vision since skeleton data is more robust to the dynamic circumstance and complicated background than other modalities. Recently, many researchers have used the Graph Convolutional Network (GCN) to model spatial-temporal features of skeleton sequences by an end-to-end optimization. However, conventional GCNs are feedforward networks which are impossible for low-level layers to access semantic information in the high-level layers. In this paper, we propose a novel network, named Feedback Graph Convolutional Network (FGCN). This is the first work that introduces the feedback mechanism into GCNs and action recognition. Compared with conventional GCNs, FGCN has the following advantages: (1) a multi-stage temporal sampling strategy is designed to extract spatial-temporal features for action recognition in a coarse-to-fine progressive process; (2) A dense connections based Feedback Graph Convolutional Block (FGCB) is proposed to introduce feedback connections into the GCNs. It transmits the high-level semantic features to the low-level layers and flows temporal information stage by stage to progressively model global spatial-temporal features for action recognition; (3) The FGCN model provides early predictions. In the early stages, the model receives partial information about actions. Naturally, its predictions are relatively coarse. The coarse predictions are treated as the prior to guide the feature learning of later stages for a accurate prediction. Extensive experiments on the datasets, NTU-RGB+D, NTU-RGB+D120 and Northwestern-UCLA, demonstrate that the proposed FGCN is effective for action recognition. It achieves the state-of-the-art performance on the three datasets.
CDPM: Convolutional Deformable Part Models for Person Re-identification
Jun 12, 2019

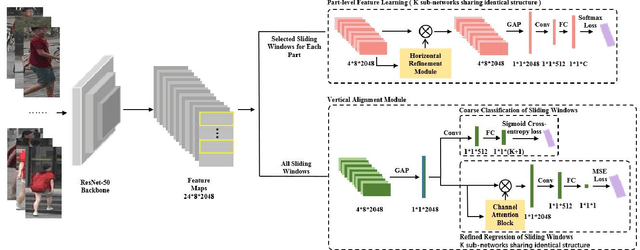
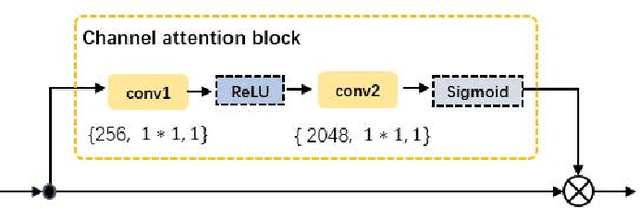
Part-level representations are essential for robust person re-identification. Due to errors in pedestrian detection, there are usually severe mis-alignment problems for body parts, which degrade the quality of part representations. To handle this problem, we propose a novel model named Convolutional Deformable Part Models (CDPM). CDPM works by decoupling the complex part alignment procedure into two easier steps. First, a vertical alignment step detects each part in the vertical direction with the help of a multi-task learning model. Second, a horizontal refinement step based on self-attention suppresses the background information around each detected body part. Since the two steps are performed orthogonally and sequentially, the difficulty of part alignment is significantly reduced. In the testing stage, CDPM is able to accurately align flexible body parts without the need of any outside information. Extensive experimental results justify the effectiveness of CDPM for part alignment. Most impressively, CDPM achieves state-of-the-art performance on three large-scale datasets: Market-1501, DukeMTMC-ReID,and CUHK03.
Sparse Camera Network for Visual Surveillance -- A Comprehensive Survey
Feb 03, 2013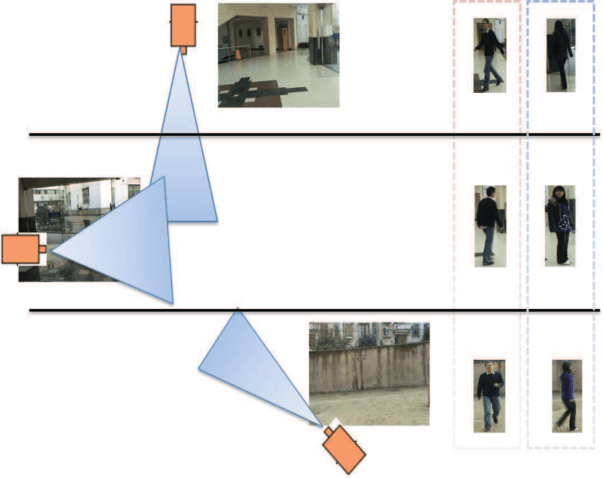



Technological advances in sensor manufacture, communication, and computing are stimulating the development of new applications that are transforming traditional vision systems into pervasive intelligent camera networks. The analysis of visual cues in multi-camera networks enables a wide range of applications, from smart home and office automation to large area surveillance and traffic surveillance. While dense camera networks - in which most cameras have large overlapping fields of view - are well studied, we are mainly concerned with sparse camera networks. A sparse camera network undertakes large area surveillance using as few cameras as possible, and most cameras have non-overlapping fields of view with one another. The task is challenging due to the lack of knowledge about the topological structure of the network, variations in the appearance and motion of specific tracking targets in different views, and the difficulties of understanding composite events in the network. In this review paper, we present a comprehensive survey of recent research results to address the problems of intra-camera tracking, topological structure learning, target appearance modeling, and global activity understanding in sparse camera networks. A number of current open research issues are discussed.