 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantix: An Energy Guided Sampler for Semantic Style Transfer
Mar 28, 2025
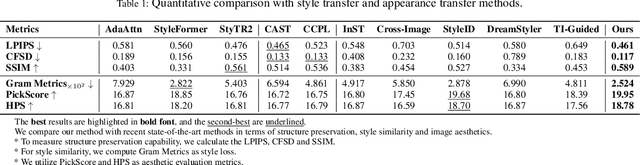
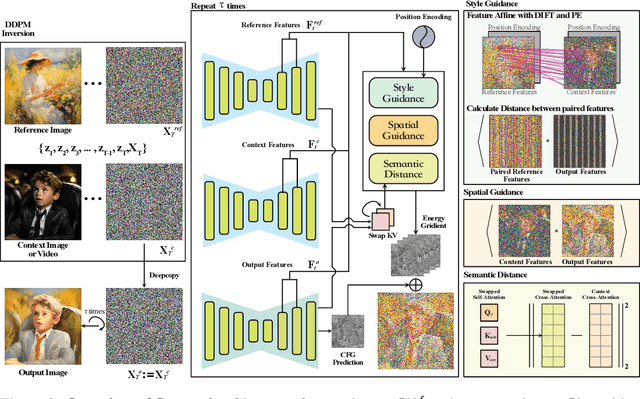
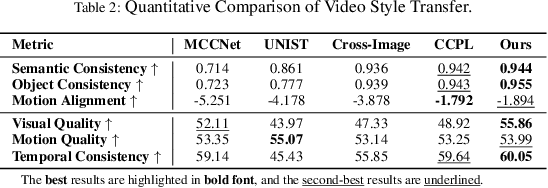
Recent advances in style and appearance transfer are impressive, but most methods isolate global style and local appearance transfer, neglecting semantic correspondence. Additionally, image and video tasks are typically handled in isolation, with little focus on integrating them for video transfer. To address these limitations, we introduce a novel task, Semantic Style Transfer, which involves transferring style and appearance features from a reference image to a target visual content based on semantic correspondence. We subsequently propose a training-free method, Semantix an energy-guided sampler designed for Semantic Style Transfer that simultaneously guides both style and appearance transfer based on semantic understanding capacity of pre-trained diffusion models. Additionally, as a sampler, Semantix be seamlessly applied to both image and video models, enabling semantic style transfer to be generic across various visual media. Specifically, once inverting both reference and context images or videos to noise space by SDEs, Semantix utilizes a meticulously crafted energy function to guide the sampling process, including three key components: Style Feature Guidance, Spatial Feature Guidance and Semantic Distance as a regularisation term. Experimental results demonstrate that Semantix not only effectively accomplishes the task of semantic style transfer across images and videos, but also surpasses existing state-of-the-art solutions in both fields. The project website is available at https://huiang-he.github.io/semantix/
MagicNaming: Consistent Identity Generation by Finding a "Name Space" in T2I Diffusion Models
Dec 19, 2024



Large-scale text-to-image diffusion models, (e.g., DALL-E, SDXL) are capable of generating famous persons by simply referring to their names. Is it possible to make such models generate generic identities as simple as the famous ones, e.g., just use a name? In this paper, we explore the existence of a "Name Space", where any point in the space corresponds to a specific identity. Fortunately, we find some clues in the feature space spanned by text embedding of celebrities' names. Specifically, we first extract the embeddings of celebrities' names in the Laion5B dataset with the text encoder of diffusion models. Such embeddings are used as supervision to learn an encoder that can predict the name (actually an embedding) of a given face image. We experimentally find that such name embeddings work well in promising the generated image with good identity consistency. Note that like the names of celebrities, our predicted name embeddings are disentangled from the semantics of text inputs, making the original generation capability of text-to-image models well-preserved. Moreover, by simply plugging such name embeddings, all variants (e.g., from Civitai) derived from the same base model (i.e., SDXL) readily become identity-aware text-to-image models. Project homepage: \url{https://magicfusion.github.io/MagicNaming/}.
* Accepted by AAAI 2025
One-shot Generative Domain Adaptation in 3D GANs
Oct 11, 2024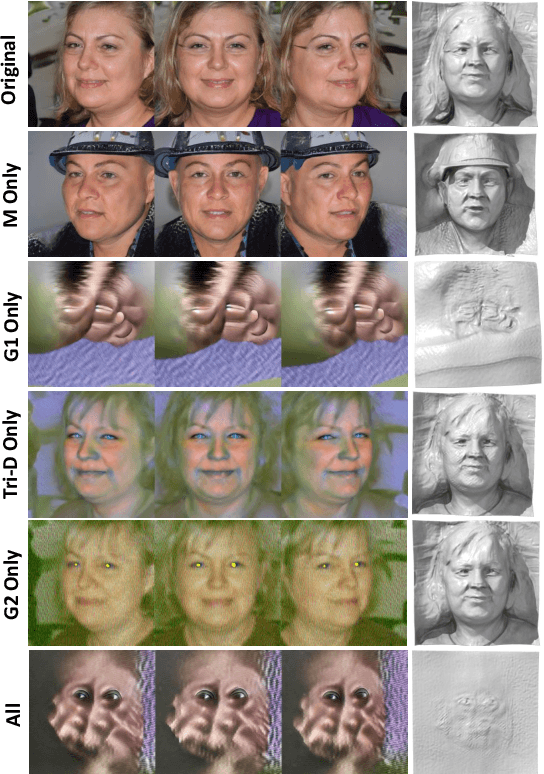
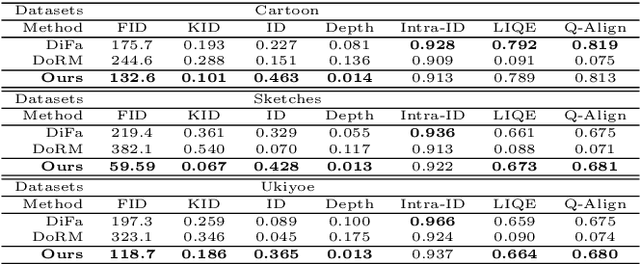
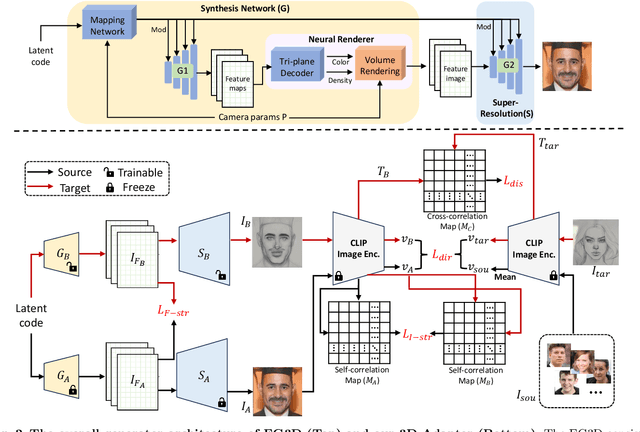

3D-aware image generation necessitates extensive training data to ensure stable training and mitigate the risk of overfitting. This paper first considers a novel task known as One-shot 3D Generative Domain Adaptation (GDA), aimed at transferring a pre-trained 3D generator from one domain to a new one, relying solely on a single reference image. One-shot 3D GDA is characterized by the pursuit of specific attributes, namely, high fidelity, large diversity, cross-domain consistency, and multi-view consistency. Within this paper, we introduce 3D-Adapter, the first one-shot 3D GDA method, for diverse and faithful generation. Our approach begins by judiciously selecting a restricted weight set for fine-tuning, and subsequently leverages four advanced loss functions to facilitate adaptation. An efficient progressive fine-tuning strategy is also implemented to enhance the adaptation process. The synergy of these three technological components empowers 3D-Adapter to achieve remarkable performance, substantiated both quantitatively and qualitatively, across all desired properties of 3D GDA. Furthermore, 3D-Adapter seamlessly extends its capabilities to zero-shot scenarios, and preserves the potential for crucial tasks such as interpolation, reconstruction, and editing within the latent space of the pre-trained generator. Code will be available at https://github.com/iceli1007/3D-Adapter.
Towards Modality-agnostic Label-efficient Segmentation with Entropy-Regularized Distribution Alignment
Aug 29, 2024



Label-efficient segmentation aims to perform effective segmentation on input data using only sparse and limited ground-truth labels for training. This topic is widely studied in 3D point cloud segmentation due to the difficulty of annotating point clouds densely, while it is also essential for cost-effective segmentation on 2D images. Until recently, pseudo-labels have been widely employed to facilitate training with limited ground-truth labels, and promising progress has been witnessed in both the 2D and 3D segmentation. However, existing pseudo-labeling approaches could suffer heavily from the noises and variations in unlabelled data, which would result in significant discrepancies between generated pseudo-labels and current model predictions during training. We analyze that this can further confuse and affect the model learning process, which shows to be a shared problem in label-efficient learning across both 2D and 3D modalities. To address this issue, we propose a novel learning strategy to regularize the pseudo-labels generated for training, thus effectively narrowing the gaps between pseudo-labels and model predictions. More specifically, our method introduces an Entropy Regularization loss and a Distribution Alignment loss for label-efficient learning, resulting in an ERDA learning strategy. Interestingly, by using KL distance to formulate the distribution alignment loss, ERDA reduces to a deceptively simple cross-entropy-based loss which optimizes both the pseudo-label generation module and the segmentation model simultaneously. In addition, we innovate in the pseudo-label generation to make our ERDA consistently effective across both 2D and 3D data modalities for segmentation. Enjoying simplicity and more modality-agnostic pseudo-label generation, our method has shown outstanding performance in fully utilizing all unlabeled data points for training across ...
Infinite-ID: Identity-preserved Personalization via ID-semantics Decoupling Paradigm
Mar 18, 2024



Drawing on recent advancements in diffusion models for text-to-image generation, identity-preserved personalization has made significant progress in accurately capturing specific identities with just a single reference image. However, existing methods primarily integrate reference images within the text embedding space, leading to a complex entanglement of image and text information, which poses challenges for preserving both identity fidelity and semantic consistency. To tackle this challenge, we propose Infinite-ID, an ID-semantics decoupling paradigm for identity-preserved personalization. Specifically, we introduce identity-enhanced training, incorporating an additional image cross-attention module to capture sufficient ID information while deactivating the original text cross-attention module of the diffusion model. This ensures that the image stream faithfully represents the identity provided by the reference image while mitigating interference from textual input. Additionally, we introduce a feature interaction mechanism that combines a mixed attention module with an AdaIN-mean operation to seamlessly merge the two streams. This mechanism not only enhances the fidelity of identity and semantic consistency but also enables convenient control over the styles of the generated images. Extensive experimental results on both raw photo generation and style image generation demonstrate the superior performance of our proposed method.
When ControlNet Meets Inexplicit Masks: A Case Study of ControlNet on its Contour-following Ability
Mar 01, 2024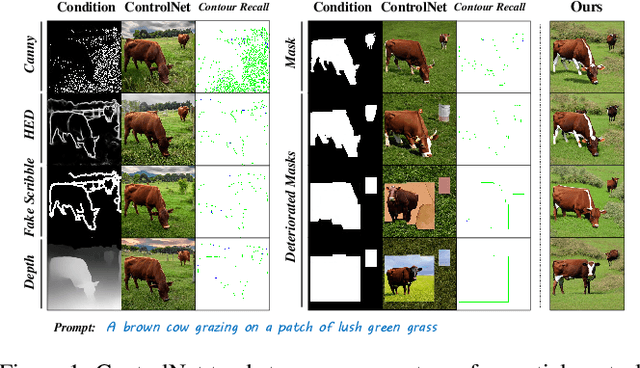
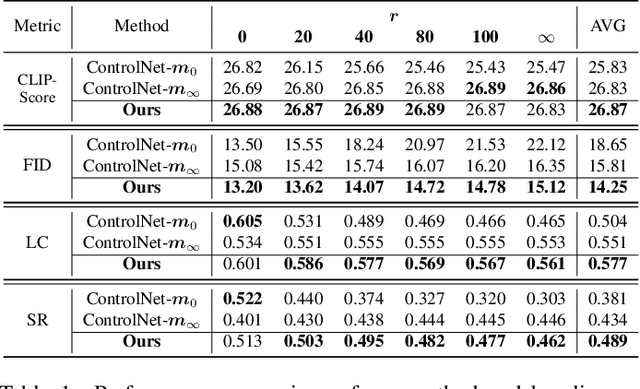


ControlNet excels at creating content that closely matches precise contours in user-provided masks. However, when these masks contain noise, as a frequent occurrence with non-expert users, the output would include unwanted artifacts. This paper first highlights the crucial role of controlling the impact of these inexplicit masks with diverse deterioration levels through in-depth analysis. Subsequently, to enhance controllability with inexplicit masks, an advanced Shape-aware ControlNet consisting of a deterioration estimator and a shape-prior modulation block is devised. The deterioration estimator assesses the deterioration factor of the provided masks. Then this factor is utilized in the modulation block to adaptively modulate the model's contour-following ability, which helps it dismiss the noise part in the inexplicit masks. Extensive experiments prove its effectiveness in encouraging ControlNet to interpret inaccurate spatial conditions robustly rather than blindly following the given contours. We showcase application scenarios like modifying shape priors and composable shape-controllable generation. Codes are soon available.
Trajectory Consistency Distillation
Feb 29, 2024



Latent Consistency Model (LCM) extends the Consistency Model to the latent space and leverages the guided consistency distillation technique to achieve impressive performance in accelerating text-to-image synthesis. However, we observed that LCM struggles to generate images with both clarity and detailed intricacy. To address this limitation, we initially delve into and elucidate the underlying causes. Our investigation identifies that the primary issue stems from errors in three distinct areas. Consequently, we introduce Trajectory Consistency Distillation (TCD), which encompasses trajectory consistency function and strategic stochastic sampling. The trajectory consistency function diminishes the distillation errors by broadening the scope of the self-consistency boundary condition and endowing the TCD with the ability to accurately trace the entire trajectory of the Probability Flow ODE. Additionally, strategic stochastic sampling is specifically designed to circumvent the accumulated errors inherent in multi-step consistency sampling, which is meticulously tailored to complement the TCD model. Experiments demonstrate that TCD not only significantly enhances image quality at low NFEs but also yields more detailed results compared to the teacher model at high NFEs.
HandRefiner: Refining Malformed Hands in Generated Images by Diffusion-based Conditional Inpainting
Nov 29, 2023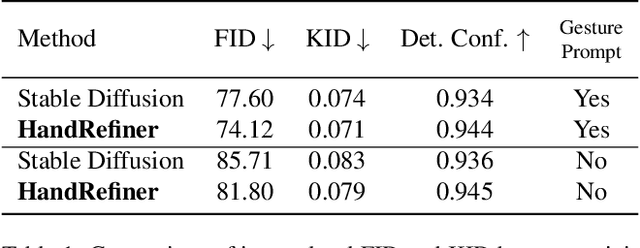
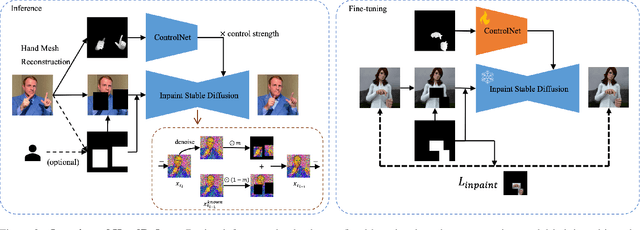


Diffusion models have achieved remarkable success in generating realistic images but suffer from generating accurate human hands, such as incorrect finger counts or irregular shapes. This difficulty arises from the complex task of learning the physical structure and pose of hands from training images, which involves extensive deformations and occlusions. For correct hand generation, our paper introduces a lightweight post-processing solution called $\textbf{HandRefiner}$. HandRefiner employs a conditional inpainting approach to rectify malformed hands while leaving other parts of the image untouched. We leverage the hand mesh reconstruction model that consistently adheres to the correct number of fingers and hand shape, while also being capable of fitting the desired hand pose in the generated image. Given a generated failed image due to malformed hands, we utilize ControlNet modules to re-inject such correct hand information. Additionally, we uncover a phase transition phenomenon within ControlNet as we vary the control strength. It enables us to take advantage of more readily available synthetic data without suffering from the domain gap between realistic and synthetic hands. Experiments demonstrate that HandRefiner can significantly improve the generation quality quantitatively and qualitatively. The code is available at https://github.com/wenquanlu/HandRefiner .
One More Step: A Versatile Plug-and-Play Module for Rectifying Diffusion Schedule Flaws and Enhancing Low-Frequency Controls
Nov 27, 2023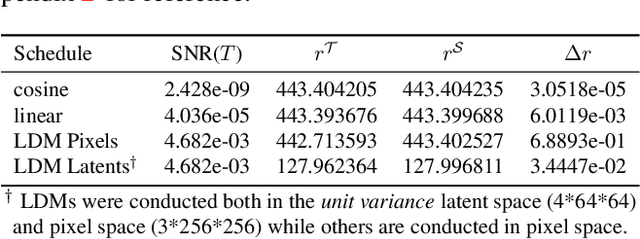
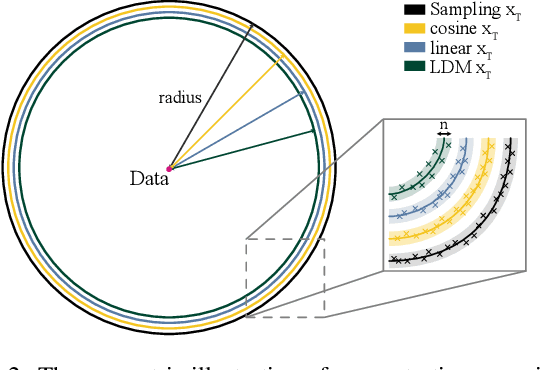
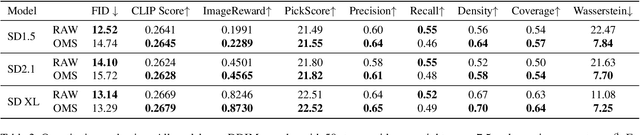
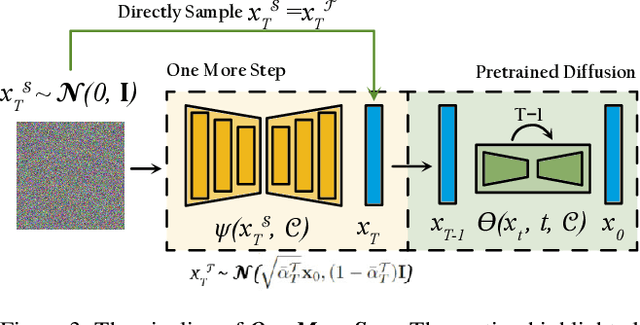
It is well known that many open-released foundational diffusion models have difficulty in generating images that substantially depart from average brightness, despite such images being present in the training data. This is due to an inconsistency: while denoising starts from pure Gaussian noise during inference, the training noise schedule retains residual data even in the final timestep distribution, due to difficulties in numerical conditioning in mainstream formulation, leading to unintended bias during inference. To mitigate this issue, certain $\epsilon$-prediction models are combined with an ad-hoc offset-noise methodology. In parallel, some contemporary models have adopted zero-terminal SNR noise schedules together with $\mathbf{v}$-prediction, which necessitate major alterations to pre-trained models. However, such changes risk destabilizing a large multitude of community-driven applications anchored on these pre-trained models. In light of this, our investigation revisits the fundamental causes, leading to our proposal of an innovative and principled remedy, called One More Step (OMS). By integrating a compact network and incorporating an additional simple yet effective step during inference, OMS elevates image fidelity and harmonizes the dichotomy between training and inference, while preserving original model parameters. Once trained, various pre-trained diffusion models with the same latent domain can share the same OMS module.
Peer is Your Pillar: A Data-unbalanced Conditional GANs for Few-shot Image Generation
Nov 14, 2023



Few-shot image generation aims to train generative models using a small number of training images. When there are few images available for training (e.g. 10 images), Learning From Scratch (LFS) methods often generate images that closely resemble the training data while Transfer Learning (TL) methods try to improve performance by leveraging prior knowledge from GANs pre-trained on large-scale datasets. However, current TL methods may not allow for sufficient control over the degree of knowledge preservation from the source model, making them unsuitable for setups where the source and target domains are not closely related. To address this, we propose a novel pipeline called Peer is your Pillar (PIP), which combines a target few-shot dataset with a peer dataset to create a data-unbalanced conditional generation. Our approach includes a class embedding method that separates the class space from the latent space, and we use a direction loss based on pre-trained CLIP to improve image diversity. Experiments on various few-shot datasets demonstrate the advancement of the proposed PIP, especially reduces the training requirements of few-shot image generation.