 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHY-Motion 1.0: Scaling Flow Matching Models for Text-To-Motion Generation
Dec 29, 2025We present HY-Motion 1.0, a series of state-of-the-art, large-scale, motion generation models capable of generating 3D human motions from textual descriptions. HY-Motion 1.0 represents the first successful attempt to scale up Diffusion Transformer (DiT)-based flow matching models to the billion-parameter scale within the motion generation domain, delivering instruction-following capabilities that significantly outperform current open-source benchmarks. Uniquely, we introduce a comprehensive, full-stage training paradigm -- including large-scale pretraining on over 3,000 hours of motion data, high-quality fine-tuning on 400 hours of curated data, and reinforcement learning from both human feedback and reward models -- to ensure precise alignment with the text instruction and high motion quality. This framework is supported by our meticulous data processing pipeline, which performs rigorous motion cleaning and captioning. Consequently, our model achieves the most extensive coverage, spanning over 200 motion categories across 6 major classes. We release HY-Motion 1.0 to the open-source community to foster future research and accelerate the transition of 3D human motion generation models towards commercial maturity.
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Jan 21, 2025



We present Hunyuan3D 2.0, an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets. This system includes two foundation components: a large-scale shape generation model -- Hunyuan3D-DiT, and a large-scale texture synthesis model -- Hunyuan3D-Paint. The shape generative model, built on a scalable flow-based diffusion transformer, aims to create geometry that properly aligns with a given condition image, laying a solid foundation for downstream applications. The texture synthesis model, benefiting from strong geometric and diffusion priors, produces high-resolution and vibrant texture maps for either generated or hand-crafted meshes. Furthermore, we build Hunyuan3D-Studio -- a versatile, user-friendly production platform that simplifies the re-creation process of 3D assets. It allows both professional and amateur users to manipulate or even animate their meshes efficiently. We systematically evaluate our models, showing that Hunyuan3D 2.0 outperforms previous state-of-the-art models, including the open-source models and closed-source models in geometry details, condition alignment, texture quality, and etc. Hunyuan3D 2.0 is publicly released in order to fill the gaps in the open-source 3D community for large-scale foundation generative models. The code and pre-trained weights of our models are available at: https://github.com/Tencent/Hunyuan3D-2
Trajectory Consistency Distillation
Feb 29, 2024



Latent Consistency Model (LCM) extends the Consistency Model to the latent space and leverages the guided consistency distillation technique to achieve impressive performance in accelerating text-to-image synthesis. However, we observed that LCM struggles to generate images with both clarity and detailed intricacy. To address this limitation, we initially delve into and elucidate the underlying causes. Our investigation identifies that the primary issue stems from errors in three distinct areas. Consequently, we introduce Trajectory Consistency Distillation (TCD), which encompasses trajectory consistency function and strategic stochastic sampling. The trajectory consistency function diminishes the distillation errors by broadening the scope of the self-consistency boundary condition and endowing the TCD with the ability to accurately trace the entire trajectory of the Probability Flow ODE. Additionally, strategic stochastic sampling is specifically designed to circumvent the accumulated errors inherent in multi-step consistency sampling, which is meticulously tailored to complement the TCD model. Experiments demonstrate that TCD not only significantly enhances image quality at low NFEs but also yields more detailed results compared to the teacher model at high NFEs.
Efficient Ray Sampling for Radiance Fields Reconstruction
Aug 29, 2023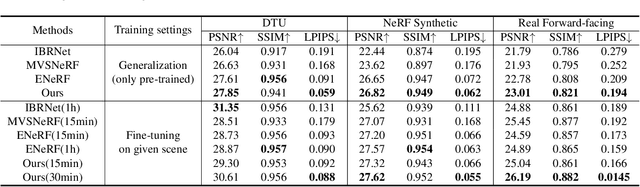
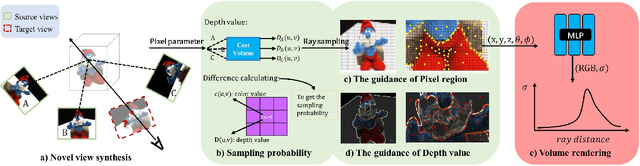

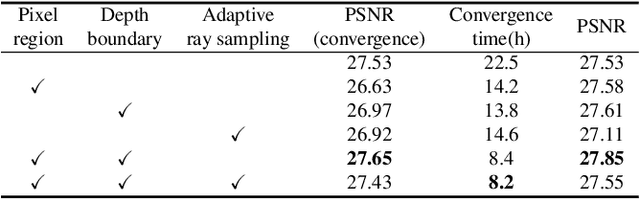
Accelerating neural radiance fields training is of substantial practical value, as the ray sampling strategy profoundly impacts network convergence. More efficient ray sampling can thus directly enhance existing NeRF models' training efficiency. We therefore propose a novel ray sampling approach for neural radiance fields that improves training efficiency while retaining photorealistic rendering results. First, we analyze the relationship between the pixel loss distribution of sampled rays and rendering quality. This reveals redundancy in the original NeRF's uniform ray sampling. Guided by this finding, we develop a sampling method leveraging pixel regions and depth boundaries. Our main idea is to sample fewer rays in training views, yet with each ray more informative for scene fitting. Sampling probability increases in pixel areas exhibiting significant color and depth variation, greatly reducing wasteful rays from other regions without sacrificing precision. Through this method, not only can the convergence of the network be accelerated, but the spatial geometry of a scene can also be perceived more accurately. Rendering outputs are enhanced, especially for texture-complex regions. Experiments demonstrate that our method significantly outperforms state-of-the-art techniques on public benchmark datasets.