 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHY3D-Bench: Generation of 3D Assets
Feb 03, 2026While recent advances in neural representations and generative models have revolutionized 3D content creation, the field remains constrained by significant data processing bottlenecks. To address this, we introduce HY3D-Bench, an open-source ecosystem designed to establish a unified, high-quality foundation for 3D generation. Our contributions are threefold: (1) We curate a library of 250k high-fidelity 3D objects distilled from large-scale repositories, employing a rigorous pipeline to deliver training-ready artifacts, including watertight meshes and multi-view renderings; (2) We introduce structured part-level decomposition, providing the granularity essential for fine-grained perception and controllable editing; and (3) We bridge real-world distribution gaps via a scalable AIGC synthesis pipeline, contributing 125k synthetic assets to enhance diversity in long-tail categories. Validated empirically through the training of Hunyuan3D-2.1-Small, HY3D-Bench democratizes access to robust data resources, aiming to catalyze innovation across 3D perception, robotics, and digital content creation.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
HunyuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels
Jul 29, 2025



Creating immersive and playable 3D worlds from texts or images remains a fundamental challenge in computer vision and graphics. Existing world generation approaches typically fall into two categories: video-based methods that offer rich diversity but lack 3D consistency and rendering efficiency, and 3D-based methods that provide geometric consistency but struggle with limited training data and memory-inefficient representations. To address these limitations, we present HunyuanWorld 1.0, a novel framework that combines the best of both worlds for generating immersive, explorable, and interactive 3D scenes from text and image conditions. Our approach features three key advantages: 1) 360{\deg} immersive experiences via panoramic world proxies; 2) mesh export capabilities for seamless compatibility with existing computer graphics pipelines; 3) disentangled object representations for augmented interactivity. The core of our framework is a semantically layered 3D mesh representation that leverages panoramic images as 360{\deg} world proxies for semantic-aware world decomposition and reconstruction, enabling the generation of diverse 3D worlds. Extensive experiments demonstrate that our method achieves state-of-the-art performance in generating coherent, explorable, and interactive 3D worlds while enabling versatile applications in virtual reality, physical simulation, game development, and interactive content creation.
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Jun 18, 20253D AI-generated content (AIGC) is a passionate field that has significantly accelerated the creation of 3D models in gaming, film, and design. Despite the development of several groundbreaking models that have revolutionized 3D generation, the field remains largely accessible only to researchers, developers, and designers due to the complexities involved in collecting, processing, and training 3D models. To address these challenges, we introduce Hunyuan3D 2.1 as a case study in this tutorial. This tutorial offers a comprehensive, step-by-step guide on processing 3D data, training a 3D generative model, and evaluating its performance using Hunyuan3D 2.1, an advanced system for producing high-resolution, textured 3D assets. The system comprises two core components: the Hunyuan3D-DiT for shape generation and the Hunyuan3D-Paint for texture synthesis. We will explore the entire workflow, including data preparation, model architecture, training strategies, evaluation metrics, and deployment. By the conclusion of this tutorial, you will have the knowledge to finetune or develop a robust 3D generative model suitable for applications in gaming, virtual reality, and industrial design.
Mesh-RFT: Enhancing Mesh Generation via Fine-grained Reinforcement Fine-Tuning
May 22, 2025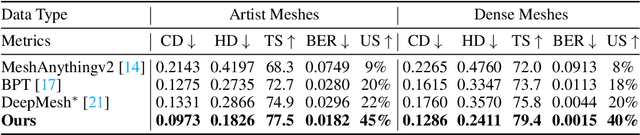
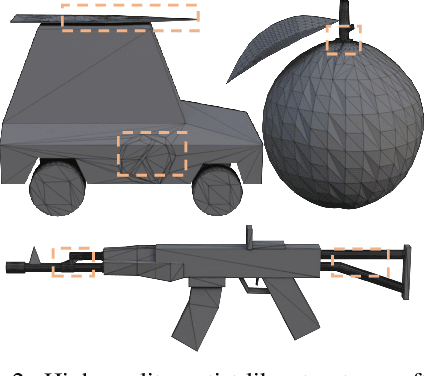
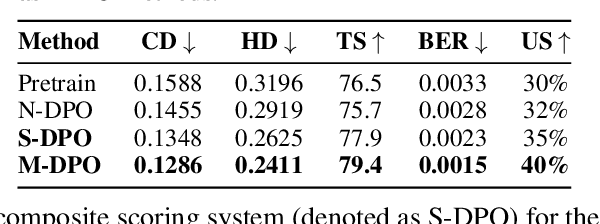
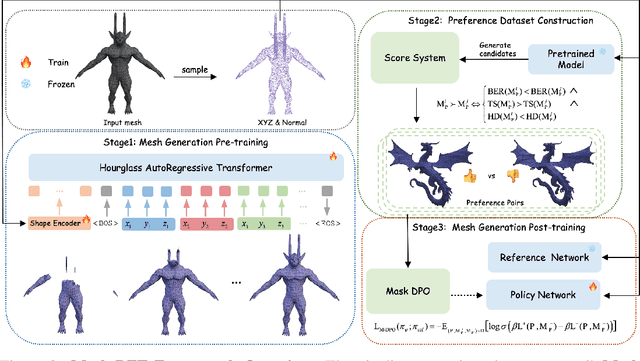
Existing pretrained models for 3D mesh generation often suffer from data biases and produce low-quality results, while global reinforcement learning (RL) methods rely on object-level rewards that struggle to capture local structure details. To address these challenges, we present \textbf{Mesh-RFT}, a novel fine-grained reinforcement fine-tuning framework that employs Masked Direct Preference Optimization (M-DPO) to enable localized refinement via quality-aware face masking. To facilitate efficient quality evaluation, we introduce an objective topology-aware scoring system to evaluate geometric integrity and topological regularity at both object and face levels through two metrics: Boundary Edge Ratio (BER) and Topology Score (TS). By integrating these metrics into a fine-grained RL strategy, Mesh-RFT becomes the first method to optimize mesh quality at the granularity of individual faces, resolving localized errors while preserving global coherence. Experiment results show that our M-DPO approach reduces Hausdorff Distance (HD) by 24.6\% and improves Topology Score (TS) by 3.8\% over pre-trained models, while outperforming global DPO methods with a 17.4\% HD reduction and 4.9\% TS gain. These results demonstrate Mesh-RFT's ability to improve geometric integrity and topological regularity, achieving new state-of-the-art performance in production-ready mesh generation. Project Page: \href{https://hitcslj.github.io/mesh-rft/}{this https URL}.
FreeMesh: Boosting Mesh Generation with Coordinates Merging
May 19, 2025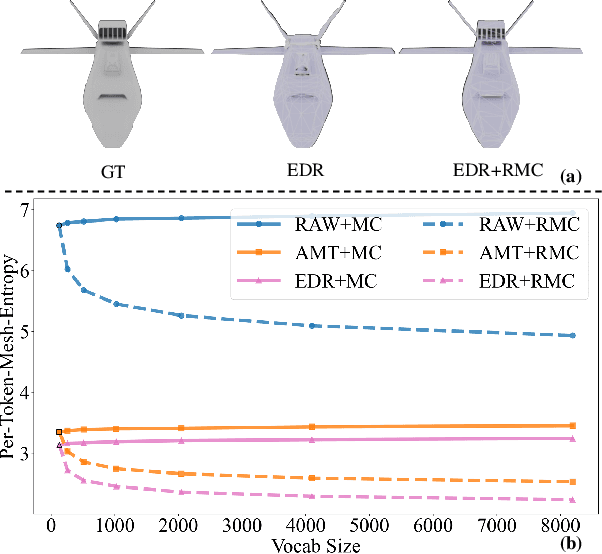
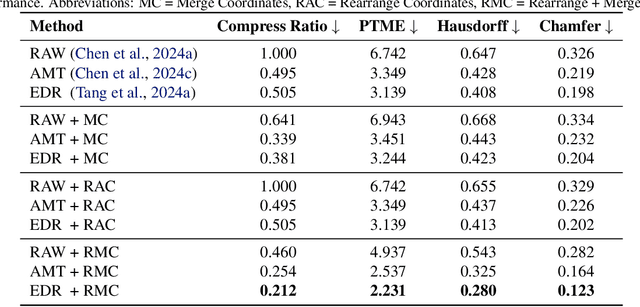
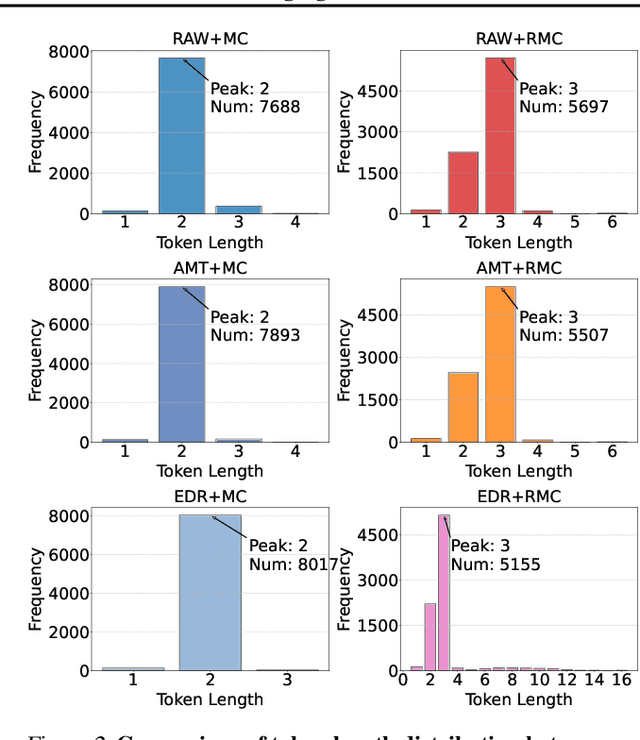
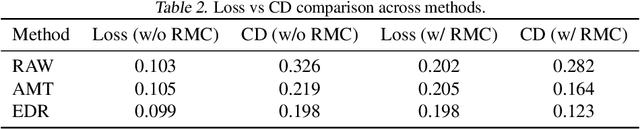
The next-coordinate prediction paradigm has emerged as the de facto standard in current auto-regressive mesh generation methods. Despite their effectiveness, there is no efficient measurement for the various tokenizers that serialize meshes into sequences. In this paper, we introduce a new metric Per-Token-Mesh-Entropy (PTME) to evaluate the existing mesh tokenizers theoretically without any training. Building upon PTME, we propose a plug-and-play tokenization technique called coordinate merging. It further improves the compression ratios of existing tokenizers by rearranging and merging the most frequent patterns of coordinates. Through experiments on various tokenization methods like MeshXL, MeshAnything V2, and Edgerunner, we further validate the performance of our method. We hope that the proposed PTME and coordinate merging can enhance the existing mesh tokenizers and guide the further development of native mesh generation.
Unleashing Vecset Diffusion Model for Fast Shape Generation
Mar 20, 20253D shape generation has greatly flourished through the development of so-called "native" 3D diffusion, particularly through the Vecset Diffusion Model (VDM). While recent advancements have shown promising results in generating high-resolution 3D shapes, VDM still struggles with high-speed generation. Challenges exist because of difficulties not only in accelerating diffusion sampling but also VAE decoding in VDM, areas under-explored in previous works. To address these challenges, we present FlashVDM, a systematic framework for accelerating both VAE and DiT in VDM. For DiT, FlashVDM enables flexible diffusion sampling with as few as 5 inference steps and comparable quality, which is made possible by stabilizing consistency distillation with our newly introduced Progressive Flow Distillation. For VAE, we introduce a lightning vecset decoder equipped with Adaptive KV Selection, Hierarchical Volume Decoding, and Efficient Network Design. By exploiting the locality of the vecset and the sparsity of shape surface in the volume, our decoder drastically lowers FLOPs, minimizing the overall decoding overhead. We apply FlashVDM to Hunyuan3D-2 to obtain Hunyuan3D-2 Turbo. Through systematic evaluation, we show that our model significantly outperforms existing fast 3D generation methods, achieving comparable performance to the state-of-the-art while reducing inference time by over 45x for reconstruction and 32x for generation. Code and models are available at https://github.com/Tencent/FlashVDM.
PBR3DGen: A VLM-guided Mesh Generation with High-quality PBR Texture
Mar 14, 2025Generating high-quality physically based rendering (PBR) materials is important to achieve realistic rendering in the downstream tasks, yet it remains challenging due to the intertwined effects of materials and lighting. While existing methods have made breakthroughs by incorporating material decomposition in the 3D generation pipeline, they tend to bake highlights into albedo and ignore spatially varying properties of metallicity and roughness. In this work, we present PBR3DGen, a two-stage mesh generation method with high-quality PBR materials that integrates the novel multi-view PBR material estimation model and a 3D PBR mesh reconstruction model. Specifically, PBR3DGen leverages vision language models (VLM) to guide multi-view diffusion, precisely capturing the spatial distribution and inherent attributes of reflective-metalness material. Additionally, we incorporate view-dependent illumination-aware conditions as pixel-aware priors to enhance spatially varying material properties. Furthermore, our reconstruction model reconstructs high-quality mesh with PBR materials. Experimental results demonstrate that PBR3DGen significantly outperforms existing methods, achieving new state-of-the-art results for PBR estimation and mesh generation. More results and visualization can be found on our project page: https://pbr3dgen1218.github.io/.
Nautilus: Locality-aware Autoencoder for Scalable Mesh Generation
Jan 27, 2025



Triangle meshes are fundamental to 3D applications, enabling efficient modification and rasterization while maintaining compatibility with standard rendering pipelines. However, current automatic mesh generation methods typically rely on intermediate representations that lack the continuous surface quality inherent to meshes. Converting these representations into meshes produces dense, suboptimal outputs. Although recent autoregressive approaches demonstrate promise in directly modeling mesh vertices and faces, they are constrained by the limitation in face count, scalability, and structural fidelity. To address these challenges, we propose Nautilus, a locality-aware autoencoder for artist-like mesh generation that leverages the local properties of manifold meshes to achieve structural fidelity and efficient representation. Our approach introduces a novel tokenization algorithm that preserves face proximity relationships and compresses sequence length through locally shared vertices and edges, enabling the generation of meshes with an unprecedented scale of up to 5,000 faces. Furthermore, we develop a Dual-stream Point Conditioner that provides multi-scale geometric guidance, ensuring global consistency and local structural fidelity by capturing fine-grained geometric features. Extensive experiments demonstrate that Nautilus significantly outperforms state-of-the-art methods in both fidelity and scalability. The project page will be released to https://nautilusmeshgen.github.io.
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Jan 21, 2025



We present Hunyuan3D 2.0, an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets. This system includes two foundation components: a large-scale shape generation model -- Hunyuan3D-DiT, and a large-scale texture synthesis model -- Hunyuan3D-Paint. The shape generative model, built on a scalable flow-based diffusion transformer, aims to create geometry that properly aligns with a given condition image, laying a solid foundation for downstream applications. The texture synthesis model, benefiting from strong geometric and diffusion priors, produces high-resolution and vibrant texture maps for either generated or hand-crafted meshes. Furthermore, we build Hunyuan3D-Studio -- a versatile, user-friendly production platform that simplifies the re-creation process of 3D assets. It allows both professional and amateur users to manipulate or even animate their meshes efficiently. We systematically evaluate our models, showing that Hunyuan3D 2.0 outperforms previous state-of-the-art models, including the open-source models and closed-source models in geometry details, condition alignment, texture quality, and etc. Hunyuan3D 2.0 is publicly released in order to fill the gaps in the open-source 3D community for large-scale foundation generative models. The code and pre-trained weights of our models are available at: https://github.com/Tencent/Hunyuan3D-2