 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsyncMesh: Fully Asynchronous Optimization for Data and Pipeline Parallelism
Jan 30, 2026Data and pipeline parallelism are key strategies for scaling neural network training across distributed devices, but their high communication cost necessitates co-located computing clusters with fast interconnects, limiting their scalability. We address this communication bottleneck by introducing asynchronous updates across both parallelism axes, relaxing the co-location requirement at the expense of introducing staleness between pipeline stages and data parallel replicas. To mitigate staleness, for pipeline parallelism, we adopt a weight look-ahead approach, and for data parallelism, we introduce an asynchronous sparse averaging method equipped with an exponential moving average based correction mechanism. We provide convergence guarantees for both sparse averaging and asynchronous updates. Experiments on large-scale language models (up to \em 1B parameters) demonstrate that our approach matches the performance of the fully synchronous baseline, while significantly reducing communication overhead.
Nesterov Method for Asynchronous Pipeline Parallel Optimization
May 02, 2025Pipeline Parallelism (PP) enables large neural network training on small, interconnected devices by splitting the model into multiple stages. To maximize pipeline utilization, asynchronous optimization is appealing as it offers 100% pipeline utilization by construction. However, it is inherently challenging as the weights and gradients are no longer synchronized, leading to stale (or delayed) gradients. To alleviate this, we introduce a variant of Nesterov Accelerated Gradient (NAG) for asynchronous optimization in PP. Specifically, we modify the look-ahead step in NAG to effectively address the staleness in gradients. We theoretically prove that our approach converges at a sublinear rate in the presence of fixed delay in gradients. Our experiments on large-scale language modelling tasks using decoder-only architectures with up to 1B parameters, demonstrate that our approach significantly outperforms existing asynchronous methods, even surpassing the synchronous baseline.
ViewFusion: Towards Multi-View Consistency via Interpolated Denoising
Feb 29, 2024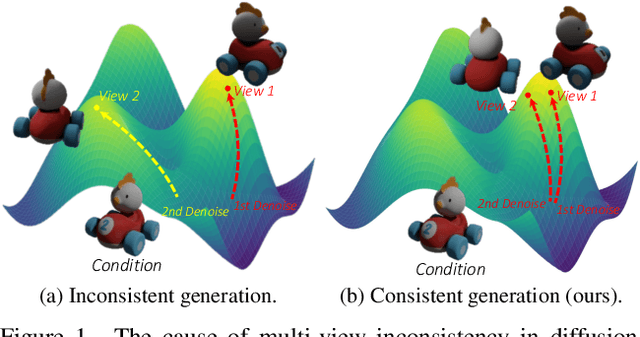
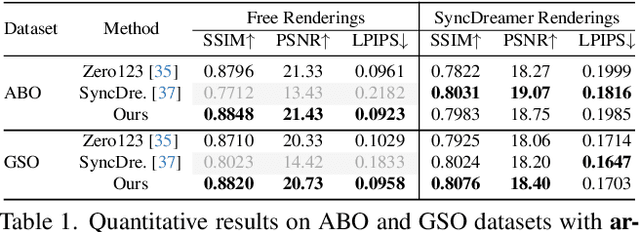
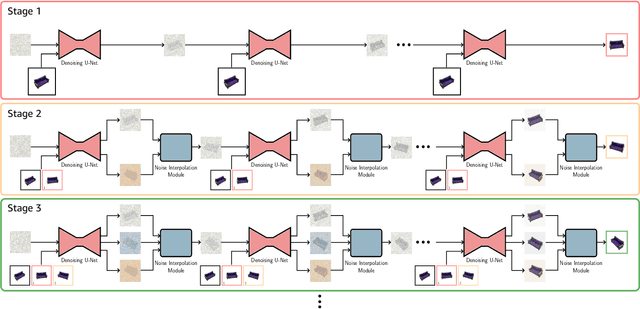
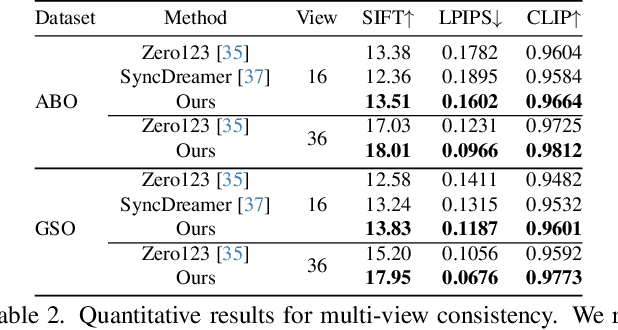
Novel-view synthesis through diffusion models has demonstrated remarkable potential for generating diverse and high-quality images. Yet, the independent process of image generation in these prevailing methods leads to challenges in maintaining multiple-view consistency. To address this, we introduce ViewFusion, a novel, training-free algorithm that can be seamlessly integrated into existing pre-trained diffusion models. Our approach adopts an auto-regressive method that implicitly leverages previously generated views as context for the next view generation, ensuring robust multi-view consistency during the novel-view generation process. Through a diffusion process that fuses known-view information via interpolated denoising, our framework successfully extends single-view conditioned models to work in multiple-view conditional settings without any additional fine-tuning. Extensive experimental results demonstrate the effectiveness of ViewFusion in generating consistent and detailed novel views.
Divide and Conquer: Rethinking the Training Paradigm of Neural Radiance Fields
Jan 29, 2024Neural radiance fields (NeRFs) have exhibited potential in synthesizing high-fidelity views of 3D scenes but the standard training paradigm of NeRF presupposes an equal importance for each image in the training set. This assumption poses a significant challenge for rendering specific views presenting intricate geometries, thereby resulting in suboptimal performance. In this paper, we take a closer look at the implications of the current training paradigm and redesign this for more superior rendering quality by NeRFs. Dividing input views into multiple groups based on their visual similarities and training individual models on each of these groups enables each model to specialize on specific regions without sacrificing speed or efficiency. Subsequently, the knowledge of these specialized models is aggregated into a single entity via a teacher-student distillation paradigm, enabling spatial efficiency for online render-ing. Empirically, we evaluate our novel training framework on two publicly available datasets, namely NeRF synthetic and Tanks&Temples. Our evaluation demonstrates that our DaC training pipeline enhances the rendering quality of a state-of-the-art baseline model while exhibiting convergence to a superior minimum.
BLiRF-RF: Bandlimited Radiance Fields for Dynamic Scene Modeling
Mar 18, 2023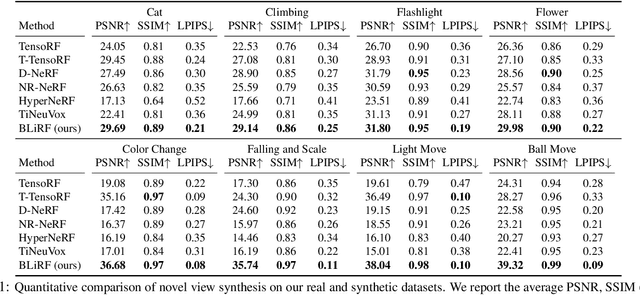
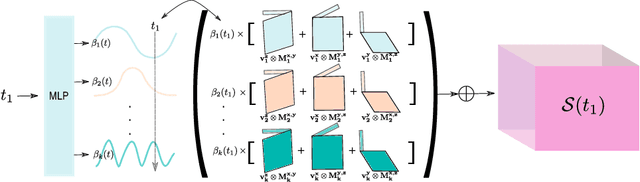

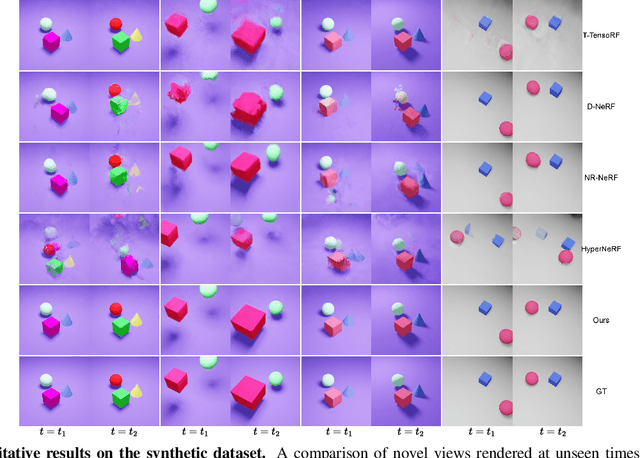
Reasoning the 3D structure of a non-rigid dynamic scene from a single moving camera is an under-constrained problem. Inspired by the remarkable progress of neural radiance fields (NeRFs) in photo-realistic novel view synthesis of static scenes, extensions have been proposed for dynamic settings. These methods heavily rely on neural priors in order to regularize the problem. In this work, we take a step back and reinvestigate how current implementations may entail deleterious effects, including limited expressiveness, entanglement of light and density fields, and sub-optimal motion localization. As a remedy, we advocate for a bridge between classic non-rigid-structure-from-motion (\nrsfm) and NeRF, enabling the well-studied priors of the former to constrain the latter. To this end, we propose a framework that factorizes time and space by formulating a scene as a composition of bandlimited, high-dimensional signals. We demonstrate compelling results across complex dynamic scenes that involve changes in lighting, texture and long-range dynamics.
Nerfels: Renderable Neural Codes for Improved Camera Pose Estimation
Jun 04, 2022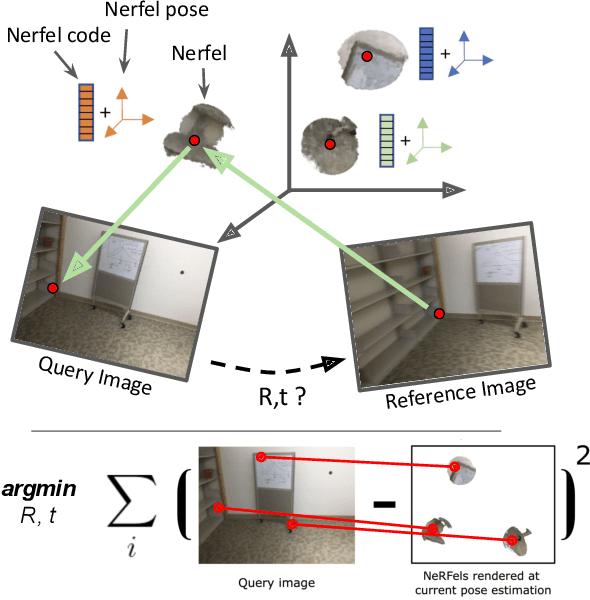
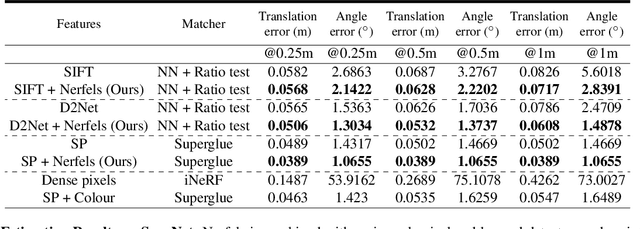


This paper presents a framework that combines traditional keypoint-based camera pose optimization with an invertible neural rendering mechanism. Our proposed 3D scene representation, Nerfels, is locally dense yet globally sparse. As opposed to existing invertible neural rendering systems which overfit a model to the entire scene, we adopt a feature-driven approach for representing scene-agnostic, local 3D patches with renderable codes. By modelling a scene only where local features are detected, our framework effectively generalizes to unseen local regions in the scene via an optimizable code conditioning mechanism in the neural renderer, all while maintaining the low memory footprint of a sparse 3D map representation. Our model can be incorporated to existing state-of-the-art hand-crafted and learned local feature pose estimators, yielding improved performance when evaluating on ScanNet for wide camera baseline scenarios.
Learning Instance and Task-Aware Dynamic Kernels for Few Shot Learning
Dec 07, 2021



Learning and generalizing to novel concepts with few samples (Few-Shot Learning) is still an essential challenge to real-world applications. A principle way of achieving few-shot learning is to realize a model that can rapidly adapt to the context of a given task. Dynamic networks have been shown capable of learning content-adaptive parameters efficiently, making them suitable for few-shot learning. In this paper, we propose to learn the dynamic kernels of a convolution network as a function of the task at hand, enabling faster generalization. To this end, we obtain our dynamic kernels based on the entire task and each sample and develop a mechanism further conditioning on each individual channel and position independently. This results in dynamic kernels that simultaneously attend to the global information whilst also considering minuscule details available. We empirically show that our model improves performance on few-shot classification and detection tasks, achieving a tangible improvement over several baseline models. This includes state-of-the-art results on 4 few-shot classification benchmarks: mini-ImageNet, tiered-ImageNet, CUB and FC100 and competitive results on a few-shot detection dataset: MS COCO-PASCAL-VOC.
Localising In Complex Scenes Using Balanced Adversarial Adaptation
Nov 09, 2020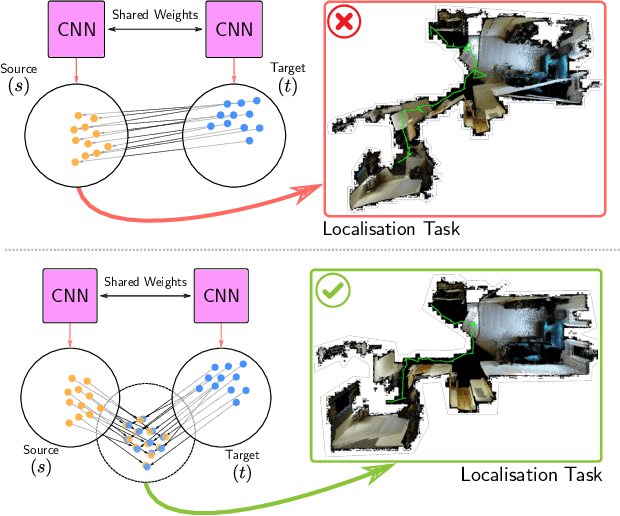
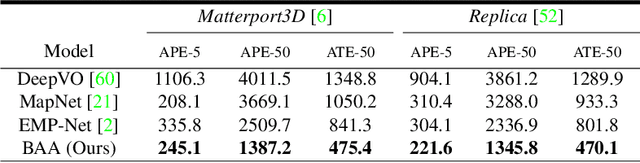
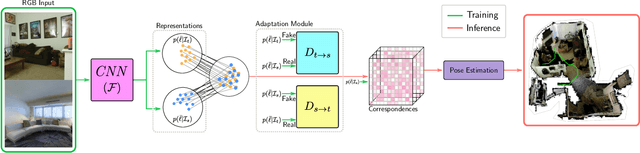
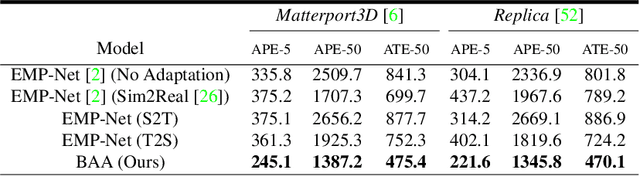
Domain adaptation and generative modelling have collectively mitigated the expensive nature of data collection and labelling by leveraging the rich abundance of accurate, labelled data in simulation environments. In this work, we study the performance gap that exists between representations optimised for localisation on simulation environments and the application of such representations in a real-world setting. Our method exploits the shared geometric similarities between simulation and real-world environments whilst maintaining invariance towards visual discrepancies. This is achieved by optimising a representation extractor to project both simulated and real representations into a shared representation space. Our method uses a symmetrical adversarial approach which encourages the representation extractor to conceal the domain that features are extracted from and simultaneously preserves robust attributes between source and target domains that are beneficial for localisation. We evaluate our method by adapting representations optimised for indoor Habitat simulated environments (Matterport3D and Replica) to a real-world indoor environment (Active Vision Dataset), showing that it compares favourably against fully-supervised approaches.
EMPNet: Neural Localisation and Mapping Using Embedded Memory Points
Aug 02, 2019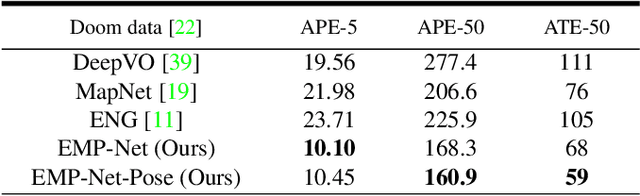
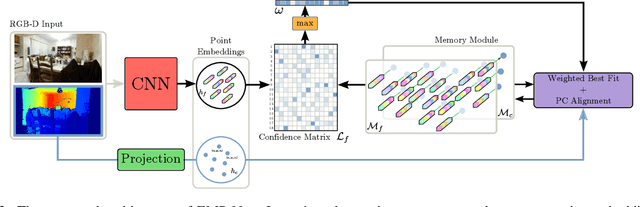
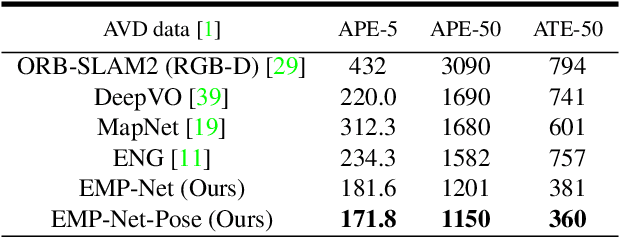
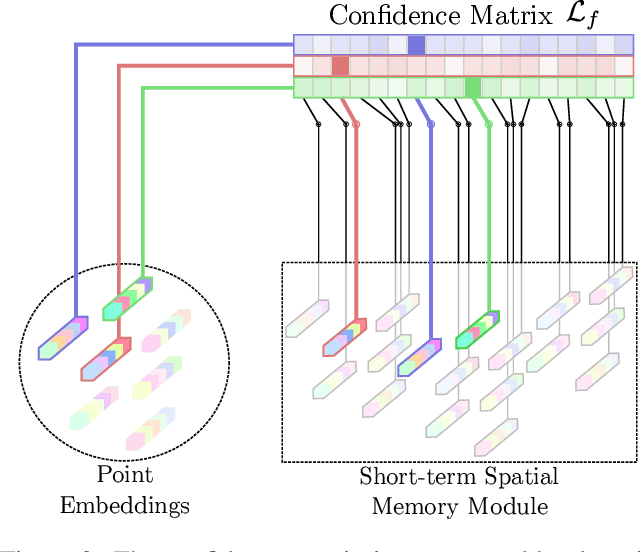
Continuously estimating an agent's state space and a representation of its surroundings has proven vital towards full autonomy. A shared common ground among systems which successfully achieve this feat is the integration of previously encountered observations into the current state being estimated. This necessitates the use of a memory module for incorporating previously visited states whilst simultaneously offering an internal representation of the observed environment. In this work we develop a memory module which contains rigidly aligned point-embeddings that represent a coherent scene structure acquired from an RGB-D sequence of observations. The point-embeddings are extracted using modern convolutional neural network architectures, and alignment is performed by computing a dense correspondence matrix between a new observation and the current embeddings residing in the memory module. The whole framework is end-to-end trainable, resulting in a recurrent joint optimisation of the point-embeddings contained in the memory. This process amplifies the shared information across states, providing increased robustness and accuracy. We show significant improvement of our method across a set of experiments performed on the synthetic VIZDoom environment and a real world Active Vision Dataset.
Traversing Latent Space using Decision Ferns
Dec 06, 2018


The practice of transforming raw data to a feature space so that inference can be performed in that space has been popular for many years. Recently, rapid progress in deep neural networks has given both researchers and practitioners enhanced methods that increase the richness of feature representations, be it from images, text or speech. In this work we show how a constructed latent space can be explored in a controlled manner and argue that this complements well founded inference methods. For constructing the latent space a Variational Autoencoder is used. We present a novel controller module that allows for smooth traversal in the latent space and construct an end-to-end trainable framework. We explore the applicability of our method for performing spatial transformations as well as kinematics for predicting future latent vectors of a video sequence.