 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Depth We Trust: Reliable Monocular Depth Supervision for Gaussian Splatting
Apr 07, 2026Using accurate depth priors in 3D Gaussian Splatting helps mitigate artifacts caused by sparse training data and textureless surfaces. However, acquiring accurate depth maps requires specialized acquisition systems. Foundation monocular depth estimation models offer a cost-effective alternative, but they suffer from scale ambiguity, multi-view inconsistency, and local geometric inaccuracies, which can degrade rendering performance when applied naively. This paper addresses the challenge of reliably leveraging monocular depth priors for Gaussian Splatting (GS) rendering enhancement. To this end, we introduce a training framework integrating scale-ambiguous and noisy depth priors into geometric supervision. We highlight the importance of learning from weakly aligned depth variations. We introduce a method to isolate ill-posed geometry for selective monocular depth regularization, restricting the propagation of depth inaccuracies into well-reconstructed 3D structures. Extensive experiments across diverse datasets show consistent improvements in geometric accuracy, leading to more faithful depth estimation and higher rendering quality across different GS variants and monocular depth backbones tested.
Non-Invasive 3D Wound Measurement with RGB-D Imaging
Jan 26, 2026Chronic wound monitoring and management require accurate and efficient wound measurement methods. This paper presents a fast, non-invasive 3D wound measurement algorithm based on RGB-D imaging. The method combines RGB-D odometry with B-spline surface reconstruction to generate detailed 3D wound meshes, enabling automatic computation of clinically relevant wound measurements such as perimeter, surface area, and dimensions. We evaluated our system on realistic silicone wound phantoms and measured sub-millimetre 3D reconstruction accuracy compared with high-resolution ground-truth scans. The extracted measurements demonstrated low variability across repeated captures and strong agreement with manual assessments. The proposed pipeline also outperformed a state-of-the-art object-centric RGB-D reconstruction method while maintaining runtimes suitable for real-time clinical deployment. Our approach offers a promising tool for automated wound assessment in both clinical and remote healthcare settings.
VAE with Hyperspherical Coordinates: Improving Anomaly Detection from Hypervolume-Compressed Latent Space
Jan 25, 2026Variational autoencoders (VAE) encode data into lower-dimensional latent vectors before decoding those vectors back to data. Once trained, one can hope to detect out-of-distribution (abnormal) latent vectors, but several issues arise when the latent space is high dimensional. This includes an exponential growth of the hypervolume with the dimension, which severely affects the generative capacity of the VAE. In this paper, we draw insights from high dimensional statistics: in these regimes, the latent vectors of a standard VAE are distributed on the `equators' of a hypersphere, challenging the detection of anomalies. We propose to formulate the latent variables of a VAE using hyperspherical coordinates, which allows compressing the latent vectors towards a given direction on the hypersphere, thereby allowing for a more expressive approximate posterior. We show that this improves both the fully unsupervised and OOD anomaly detection ability of the VAE, achieving the best performance on the datasets we considered, outperforming existing methods. For the unsupervised and OOD modalities, respectively, these are: i) detecting unusual landscape from the Mars Rover camera and unusual Galaxies from ground based imagery (complex, real world datasets); ii) standard benchmarks like Cifar10 and subsets of ImageNet as the in-distribution (ID) class.
Deformation-aware GAN for Medical Image Synthesis with Substantially Misaligned Pairs
Aug 18, 2024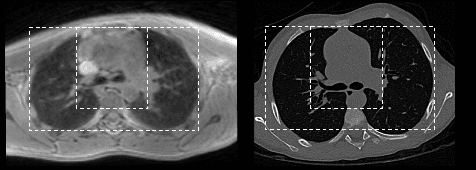
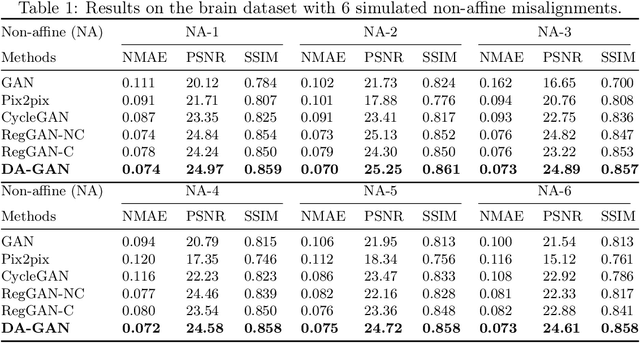
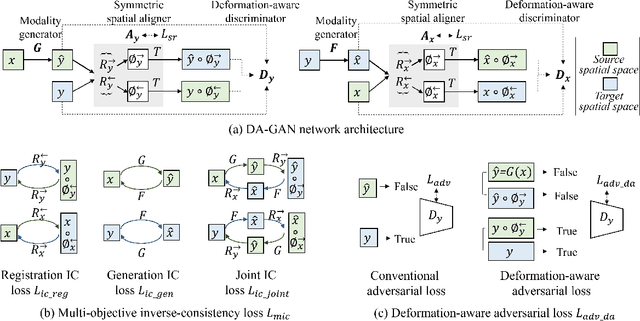
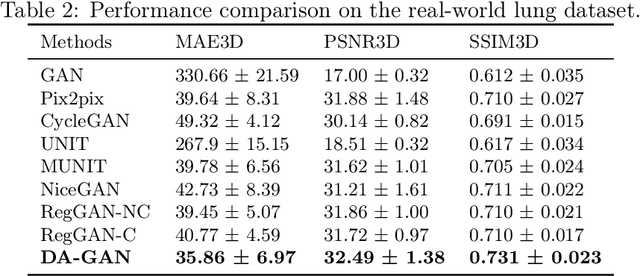
Medical image synthesis generates additional imaging modalities that are costly, invasive or harmful to acquire, which helps to facilitate the clinical workflow. When training pairs are substantially misaligned (e.g., lung MRI-CT pairs with respiratory motion), accurate image synthesis remains a critical challenge. Recent works explored the directional registration module to adjust misalignment in generative adversarial networks (GANs); however, substantial misalignment will lead to 1) suboptimal data mapping caused by correspondence ambiguity, and 2) degraded image fidelity caused by morphology influence on discriminators. To address the challenges, we propose a novel Deformation-aware GAN (DA-GAN) to dynamically correct the misalignment during the image synthesis based on multi-objective inverse consistency. Specifically, in the generative process, three levels of inverse consistency cohesively optimise symmetric registration and image generation for improved correspondence. In the adversarial process, to further improve image fidelity under misalignment, we design deformation-aware discriminators to disentangle the mismatched spatial morphology from the judgement of image fidelity. Experimental results show that DA-GAN achieved superior performance on a public dataset with simulated misalignments and a real-world lung MRI-CT dataset with respiratory motion misalignment. The results indicate the potential for a wide range of medical image synthesis tasks such as radiotherapy planning.
SALVE: A 3D Reconstruction Benchmark of Wounds from Consumer-grade Videos
Jul 29, 2024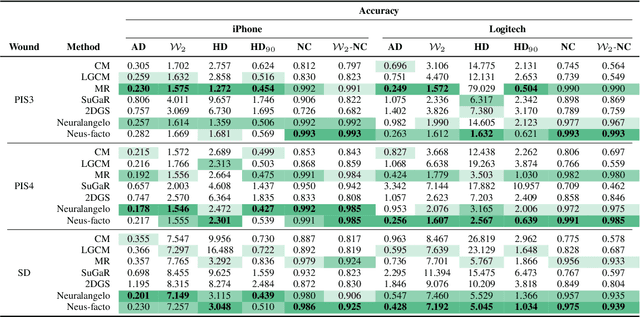
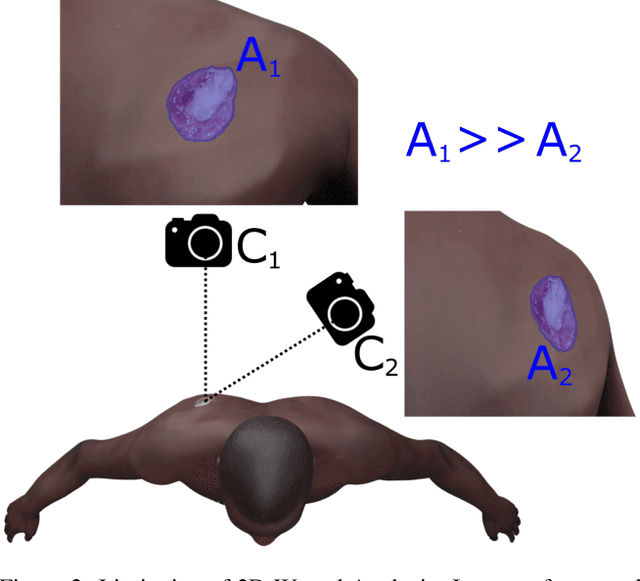
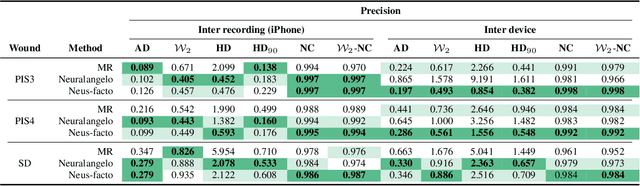

Managing chronic wounds is a global challenge that can be alleviated by the adoption of automatic systems for clinical wound assessment from consumer-grade videos. While 2D image analysis approaches are insufficient for handling the 3D features of wounds, existing approaches utilizing 3D reconstruction methods have not been thoroughly evaluated. To address this gap, this paper presents a comprehensive study on 3D wound reconstruction from consumer-grade videos. Specifically, we introduce the SALVE dataset, comprising video recordings of realistic wound phantoms captured with different cameras. Using this dataset, we assess the accuracy and precision of state-of-the-art methods for 3D reconstruction, ranging from traditional photogrammetry pipelines to advanced neural rendering approaches. In our experiments, we observe that photogrammetry approaches do not provide smooth surfaces suitable for precise clinical measurements of wounds. Neural rendering approaches show promise in addressing this issue, advancing the use of this technology in wound care practices.
NeRF Director: Revisiting View Selection in Neural Volume Rendering
Jun 13, 2024



Neural Rendering representations have significantly contributed to the field of 3D computer vision. Given their potential, considerable efforts have been invested to improve their performance. Nonetheless, the essential question of selecting training views is yet to be thoroughly investigated. This key aspect plays a vital role in achieving high-quality results and aligns with the well-known tenet of deep learning: "garbage in, garbage out". In this paper, we first illustrate the importance of view selection by demonstrating how a simple rotation of the test views within the most pervasive NeRF dataset can lead to consequential shifts in the performance rankings of state-of-the-art techniques. To address this challenge, we introduce a unified framework for view selection methods and devise a thorough benchmark to assess its impact. Significant improvements can be achieved without leveraging error or uncertainty estimation but focusing on uniform view coverage of the reconstructed object, resulting in a training-free approach. Using this technique, we show that high-quality renderings can be achieved faster by using fewer views. We conduct extensive experiments on both synthetic datasets and realistic data to demonstrate the effectiveness of our proposed method compared with random, conventional error-based, and uncertainty-guided view selection.
Divide and Conquer: Rethinking the Training Paradigm of Neural Radiance Fields
Jan 29, 2024Neural radiance fields (NeRFs) have exhibited potential in synthesizing high-fidelity views of 3D scenes but the standard training paradigm of NeRF presupposes an equal importance for each image in the training set. This assumption poses a significant challenge for rendering specific views presenting intricate geometries, thereby resulting in suboptimal performance. In this paper, we take a closer look at the implications of the current training paradigm and redesign this for more superior rendering quality by NeRFs. Dividing input views into multiple groups based on their visual similarities and training individual models on each of these groups enables each model to specialize on specific regions without sacrificing speed or efficiency. Subsequently, the knowledge of these specialized models is aggregated into a single entity via a teacher-student distillation paradigm, enabling spatial efficiency for online render-ing. Empirically, we evaluate our novel training framework on two publicly available datasets, namely NeRF synthetic and Tanks&Temples. Our evaluation demonstrates that our DaC training pipeline enhances the rendering quality of a state-of-the-art baseline model while exhibiting convergence to a superior minimum.
DeepCSR: A 3D Deep Learning Approach for Cortical Surface Reconstruction
Oct 22, 2020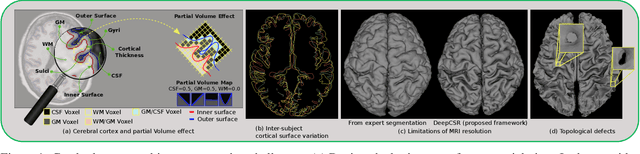
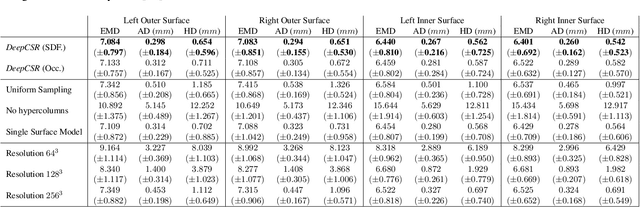

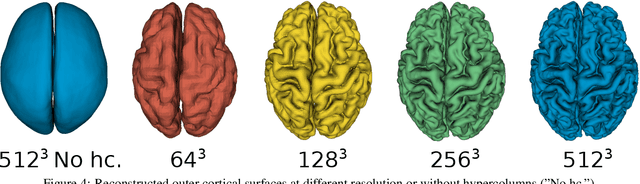
The study of neurodegenerative diseases relies on the reconstruction and analysis of the brain cortex from magnetic resonance imaging (MRI). Traditional frameworks for this task like FreeSurfer demand lengthy runtimes, while its accelerated variant FastSurfer still relies on a voxel-wise segmentation which is limited by its resolution to capture narrow continuous objects as cortical surfaces. Having these limitations in mind, we propose DeepCSR, a 3D deep learning framework for cortical surface reconstruction from MRI. Towards this end, we train a neural network model with hypercolumn features to predict implicit surface representations for points in a brain template space. After training, the cortical surface at a desired level of detail is obtained by evaluating surface representations at specific coordinates, and subsequently applying a topology correction algorithm and an isosurface extraction method. Thanks to the continuous nature of this approach and the efficacy of its hypercolumn features scheme, DeepCSR efficiently reconstructs cortical surfaces at high resolution capturing fine details in the cortical folding. Moreover, DeepCSR is as accurate, more precise, and faster than the widely used FreeSurfer toolbox and its deep learning powered variant FastSurfer on reconstructing cortical surfaces from MRI which should facilitate large-scale medical studies and new healthcare applications.