 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Rule Violations Are Rare: Chimera Training for Logical Anomaly Detection
May 25, 2026Many practical anomalies are not merely rare inputs, but violations of semantic constraints: objects co-occur in structured ways, actions imply preconditions, and events satisfy temporal or relational regularities. We study anomaly detection in this setting, where constraints are given as logical rules over learned visual concepts, but real rule violations are rare or absent during training. We propose a neural rule evaluator that compiles each constraint into a directed acyclic graph and learns feature-aware subtree MLP gates for its internal logical operators. Each gate maps child features and edge-level negations to a parent representation and a rule-satisfaction probability, with intermediate supervision obtained from exact Boolean propagation over ground-truth concept labels. The key difficulty is that same-image training data often provide insufficient coverage of informative truth configurations and also allow shortcut solutions. To address this, we introduce chimera training: an operand-level counterfactual construction at the feature level. Instead of mixing input images, we concatenate subtree features from different samples; each operand keeps the hard truth label of the sample it came from, and the chimera target is obtained by applying the node's logical operator to those inherited labels. This supplies supervised logical counterexamples without requiring real anomalous images. Across CLEVRER, OpenImages, and VidOR, the resulting evaluator improves rule-level anomaly AUROC over independent-events and same-image semantic-training baselines, especially for compositional and relational rules. The method yields both scalar anomaly scores and rule-level attributions.
First Shape, Then Meaning: Efficient Geometry and Semantics Learning for Indoor Reconstruction
May 05, 2026Neural Surface Reconstruction has become a standard methodology for indoor 3D reconstruction, with Signed Distance Functions (SDFs) proving particularly effective for representing scene geometry. A variety of applications require a detailed understanding of the scene context, driving the need for object-level semantic signals. While recent methods successfully integrate semantic labels, they often inherit the slow training time and limited scalability of multi-SDF learning. In this paper, we introduce FSTM, a unified approach for learning geometry and semantics through a two-step process: a geometry warm-up using RGB inputs and geometric cues, followed by semantic field estimation. By first optimising geometry without semantic supervision, we observe substantial improvements compared to the standard joint optimisation. Rather than relying on specialised modules or complex multi-SDF designs, FSTM shows that a streamlined formulation is sufficient to achieve strong geometric and semantic reconstructions. Experiments on both synthetic and real-world indoor datasets show that our method outperforms multi-SDF approaches. It trains 2.3x faster on Replica, improves robustness to real-world imperfections on ScanNet++, and achieves higher recall by recovering the surfaces of more objects in the scene. The code will be made available at https://remichierchia.github.io/FSTM.
In Depth We Trust: Reliable Monocular Depth Supervision for Gaussian Splatting
Apr 07, 2026Using accurate depth priors in 3D Gaussian Splatting helps mitigate artifacts caused by sparse training data and textureless surfaces. However, acquiring accurate depth maps requires specialized acquisition systems. Foundation monocular depth estimation models offer a cost-effective alternative, but they suffer from scale ambiguity, multi-view inconsistency, and local geometric inaccuracies, which can degrade rendering performance when applied naively. This paper addresses the challenge of reliably leveraging monocular depth priors for Gaussian Splatting (GS) rendering enhancement. To this end, we introduce a training framework integrating scale-ambiguous and noisy depth priors into geometric supervision. We highlight the importance of learning from weakly aligned depth variations. We introduce a method to isolate ill-posed geometry for selective monocular depth regularization, restricting the propagation of depth inaccuracies into well-reconstructed 3D structures. Extensive experiments across diverse datasets show consistent improvements in geometric accuracy, leading to more faithful depth estimation and higher rendering quality across different GS variants and monocular depth backbones tested.
NC-Reg : Neural Cortical Maps for Rigid Registration
Jan 26, 2026We introduce neural cortical maps, a continuous and compact neural representation for cortical feature maps, as an alternative to traditional discrete structures such as grids and meshes. It can learn from meshes of arbitrary size and provide learnt features at any resolution. Neural cortical maps enable efficient optimization on the sphere and achieve runtimes up to 30 times faster than classic barycentric interpolation (for the same number of iterations). As a proof of concept, we investigate rigid registration of cortical surfaces and propose NC-Reg, a novel iterative algorithm that involves the use of neural cortical feature maps, gradient descent optimization and a simulated annealing strategy. Through ablation studies and subject-to-template experiments, our method demonstrates sub-degree accuracy ($<1^\circ$ from the global optimum), and serves as a promising robust pre-alignment strategy, which is critical in clinical settings.
Non-Invasive 3D Wound Measurement with RGB-D Imaging
Jan 26, 2026Chronic wound monitoring and management require accurate and efficient wound measurement methods. This paper presents a fast, non-invasive 3D wound measurement algorithm based on RGB-D imaging. The method combines RGB-D odometry with B-spline surface reconstruction to generate detailed 3D wound meshes, enabling automatic computation of clinically relevant wound measurements such as perimeter, surface area, and dimensions. We evaluated our system on realistic silicone wound phantoms and measured sub-millimetre 3D reconstruction accuracy compared with high-resolution ground-truth scans. The extracted measurements demonstrated low variability across repeated captures and strong agreement with manual assessments. The proposed pipeline also outperformed a state-of-the-art object-centric RGB-D reconstruction method while maintaining runtimes suitable for real-time clinical deployment. Our approach offers a promising tool for automated wound assessment in both clinical and remote healthcare settings.
VAE with Hyperspherical Coordinates: Improving Anomaly Detection from Hypervolume-Compressed Latent Space
Jan 25, 2026Variational autoencoders (VAE) encode data into lower-dimensional latent vectors before decoding those vectors back to data. Once trained, one can hope to detect out-of-distribution (abnormal) latent vectors, but several issues arise when the latent space is high dimensional. This includes an exponential growth of the hypervolume with the dimension, which severely affects the generative capacity of the VAE. In this paper, we draw insights from high dimensional statistics: in these regimes, the latent vectors of a standard VAE are distributed on the `equators' of a hypersphere, challenging the detection of anomalies. We propose to formulate the latent variables of a VAE using hyperspherical coordinates, which allows compressing the latent vectors towards a given direction on the hypersphere, thereby allowing for a more expressive approximate posterior. We show that this improves both the fully unsupervised and OOD anomaly detection ability of the VAE, achieving the best performance on the datasets we considered, outperforming existing methods. For the unsupervised and OOD modalities, respectively, these are: i) detecting unusual landscape from the Mars Rover camera and unusual Galaxies from ground based imagery (complex, real world datasets); ii) standard benchmarks like Cifar10 and subsets of ImageNet as the in-distribution (ID) class.
Multi-View Consistent Wound Segmentation With Neural Fields
Jan 23, 2026Wound care is often challenged by the economic and logistical burdens that consistently afflict patients and hospitals worldwide. In recent decades, healthcare professionals have sought support from computer vision and machine learning algorithms. In particular, wound segmentation has gained interest due to its ability to provide professionals with fast, automatic tissue assessment from standard RGB images. Some approaches have extended segmentation to 3D, enabling more complete and precise healing progress tracking. However, inferring multi-view consistent 3D structures from 2D images remains a challenge. In this paper, we evaluate WoundNeRF, a NeRF SDF-based method for estimating robust wound segmentations from automatically generated annotations. We demonstrate the potential of this paradigm in recovering accurate segmentations by comparing it against state-of-the-art Vision Transformer networks and conventional rasterisation-based algorithms. The code will be released to facilitate further development in this promising paradigm.
Wound3DAssist: A Practical Framework for 3D Wound Assessment
Aug 25, 2025
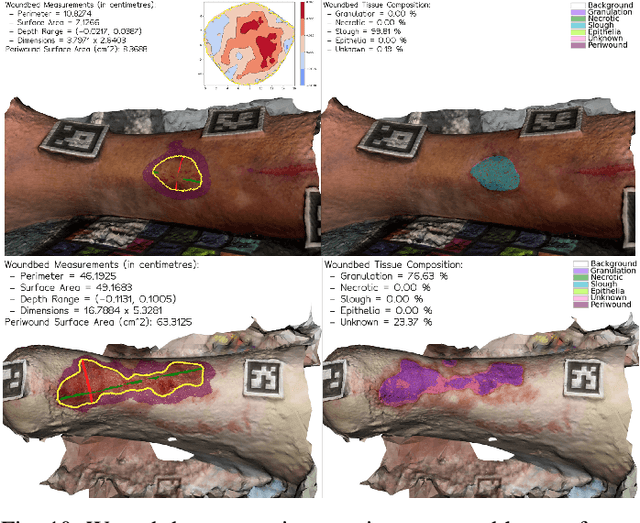
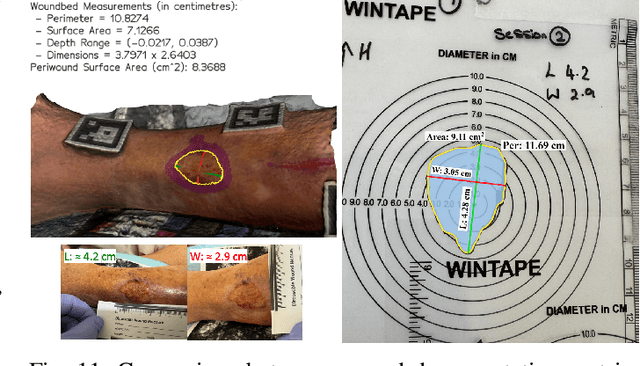
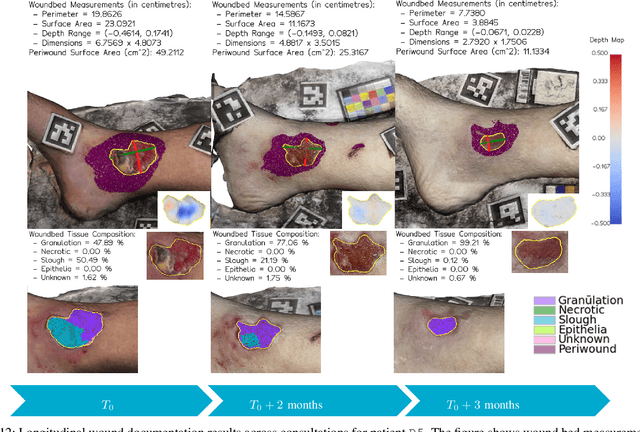
Managing chronic wounds remains a major healthcare challenge, with clinical assessment often relying on subjective and time-consuming manual documentation methods. Although 2D digital videometry frameworks aided the measurement process, these approaches struggle with perspective distortion, a limited field of view, and an inability to capture wound depth, especially in anatomically complex or curved regions. To overcome these limitations, we present Wound3DAssist, a practical framework for 3D wound assessment using monocular consumer-grade videos. Our framework generates accurate 3D models from short handheld smartphone video recordings, enabling non-contact, automatic measurements that are view-independent and robust to camera motion. We integrate 3D reconstruction, wound segmentation, tissue classification, and periwound analysis into a modular workflow. We evaluate Wound3DAssist across digital models with known geometry, silicone phantoms, and real patients. Results show that the framework supports high-quality wound bed visualization, millimeter-level accuracy, and reliable tissue composition analysis. Full assessments are completed in under 20 minutes, demonstrating feasibility for real-world clinical use.
PINNs for Medical Image Analysis: A Survey
Aug 02, 2024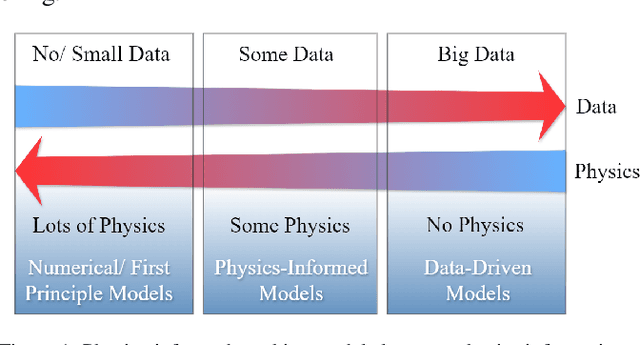

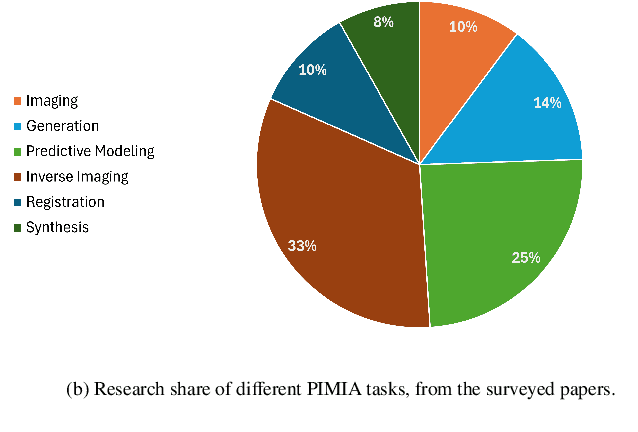

The incorporation of physical information in machine learning frameworks is transforming medical image analysis (MIA). By integrating fundamental knowledge and governing physical laws, these models achieve enhanced robustness and interpretability. In this work, we explore the utility of physics-informed approaches for MIA (PIMIA) tasks such as registration, generation, classification, and reconstruction. We present a systematic literature review of over 80 papers on physics-informed methods dedicated to MIA. We propose a unified taxonomy to investigate what physics knowledge and processes are modelled, how they are represented, and the strategies to incorporate them into MIA models. We delve deep into a wide range of image analysis tasks, from imaging, generation, prediction, inverse imaging (super-resolution and reconstruction), registration, and image analysis (segmentation and classification). For each task, we thoroughly examine and present in a tabular format the central physics-guided operation, the region of interest (with respect to human anatomy), the corresponding imaging modality, the dataset used for model training, the deep network architecture employed, and the primary physical process, equation, or principle utilized. Additionally, we also introduce a novel metric to compare the performance of PIMIA methods across different tasks and datasets. Based on this review, we summarize and distil our perspectives on the challenges, open research questions, and directions for future research. We highlight key open challenges in PIMIA, including selecting suitable physics priors and establishing a standardized benchmarking platform.
SALVE: A 3D Reconstruction Benchmark of Wounds from Consumer-grade Videos
Jul 29, 2024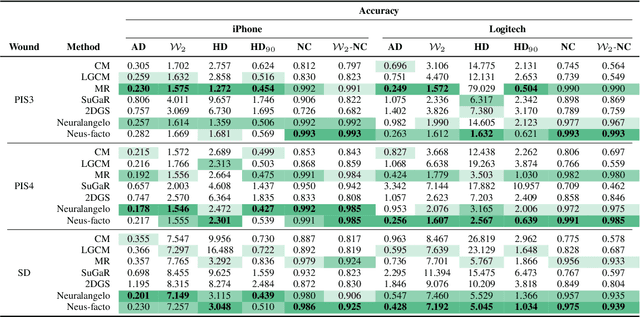
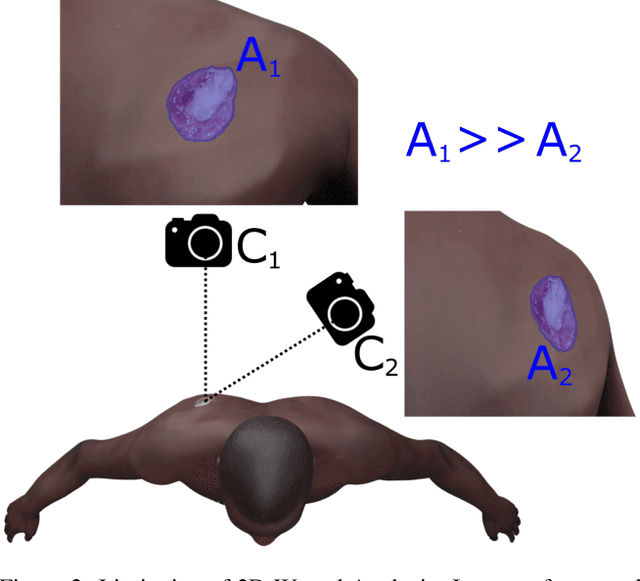
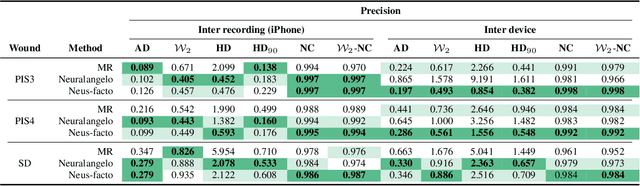

Managing chronic wounds is a global challenge that can be alleviated by the adoption of automatic systems for clinical wound assessment from consumer-grade videos. While 2D image analysis approaches are insufficient for handling the 3D features of wounds, existing approaches utilizing 3D reconstruction methods have not been thoroughly evaluated. To address this gap, this paper presents a comprehensive study on 3D wound reconstruction from consumer-grade videos. Specifically, we introduce the SALVE dataset, comprising video recordings of realistic wound phantoms captured with different cameras. Using this dataset, we assess the accuracy and precision of state-of-the-art methods for 3D reconstruction, ranging from traditional photogrammetry pipelines to advanced neural rendering approaches. In our experiments, we observe that photogrammetry approaches do not provide smooth surfaces suitable for precise clinical measurements of wounds. Neural rendering approaches show promise in addressing this issue, advancing the use of this technology in wound care practices.